Division of Clinical Pathology, Laboratori Vita s.r.l., Via Sabaudia 19, 04100, Latina, Italy.
Unit of Computer Systems an Bioinformatics, Department of Engineering, Università Campus Bio-Medico di Roma, Via Alvaro del Portillo 21, 00128, Rome, Italy.
Sci Rep. 2022 Feb 23;12(1):3041. doi: 10.1038/s41598-022-06788-2.
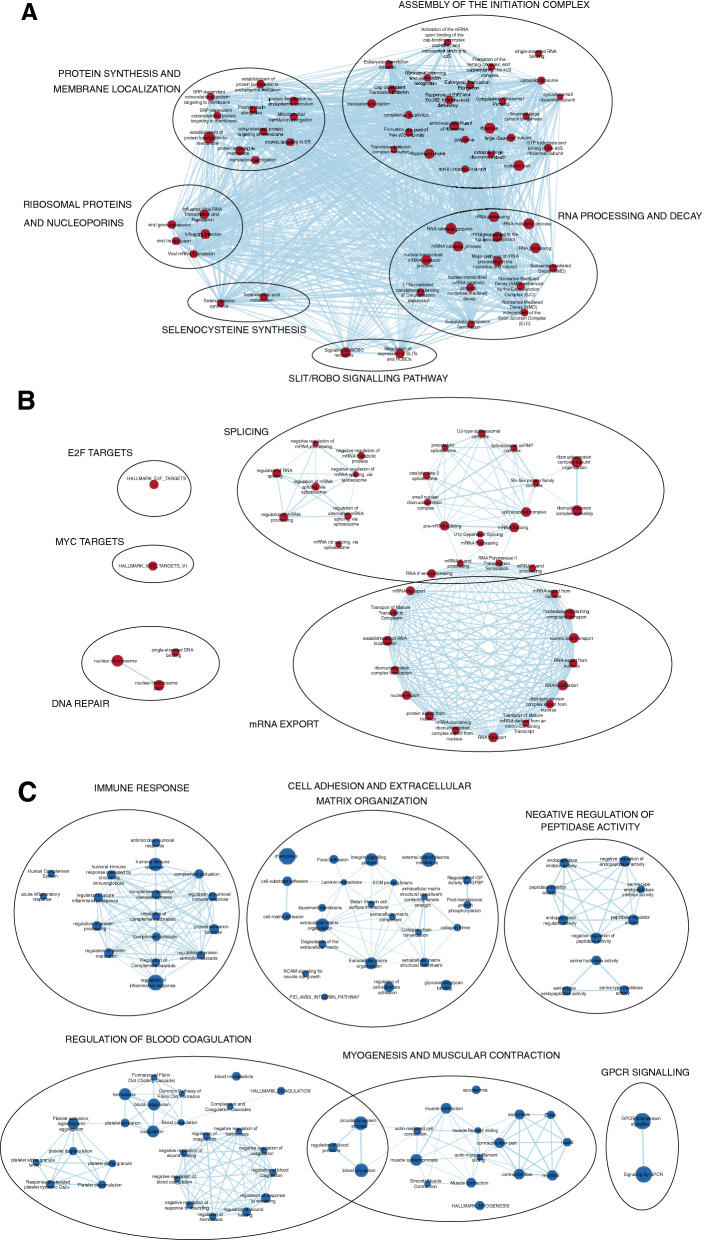
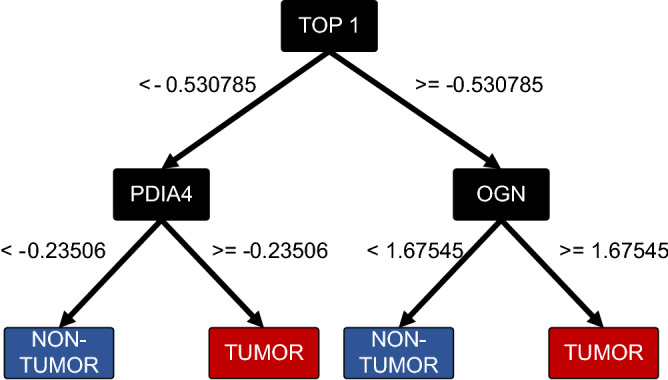
Ovarian cancer is one of the most common gynecological malignancies, ranking third after cervical and uterine cancer. High-grade serous ovarian cancer (HGSOC) is one of the most aggressive subtype, and the late onset of its symptoms leads in most cases to an unfavourable prognosis. Current predictive algorithms used to estimate the risk of having Ovarian Cancer fail to provide sufficient sensitivity and specificity to be used widely in clinical practice. The use of additional biomarkers or parameters such as age or menopausal status to overcome these issues showed only weak improvements. It is necessary to identify novel molecular signatures and the development of new predictive algorithms able to support the diagnosis of HGSOC, and at the same time, deepen the understanding of this elusive disease, with the final goal of improving patient survival. Here, we apply a Machine Learning-based pipeline to an open-source HGSOC Proteomic dataset to develop a decision support system (DSS) that displayed high discerning ability on a dataset of HGSOC biopsies. The proposed DSS consists of a double-step feature selection and a decision tree, with the resulting output consisting of a combination of three highly discriminating proteins: TOP1, PDIA4, and OGN, that could be of interest for further clinical and experimental validation. Furthermore, we took advantage of the ranked list of proteins generated during the feature selection steps to perform a pathway analysis to provide a snapshot of the main deregulated pathways of HGSOC. The datasets used for this study are available in the Clinical Proteomic Tumor Analysis Consortium (CPTAC) data portal ( https://cptac-data-portal.georgetown.edu/ ).
卵巢癌是最常见的妇科恶性肿瘤之一,位居宫颈癌和子宫内膜癌之后,排名第三。高级别浆液性卵巢癌(HGSOC)是最具侵袭性的亚型之一,其症状出现较晚,导致大多数情况下预后不良。目前用于估计卵巢癌风险的预测算法未能提供足够的敏感性和特异性,无法在临床实践中广泛应用。使用年龄或绝经状态等其他生物标志物或参数来克服这些问题,仅显示出微弱的改善。有必要识别新的分子特征,并开发新的预测算法,以支持 HGSOC 的诊断,同时加深对这种难以捉摸的疾病的理解,最终目标是提高患者的生存率。在这里,我们将基于机器学习的管道应用于开源 HGSOC 蛋白质组数据集,以开发一种决策支持系统 (DSS),该系统在 HGSOC 活检数据集上显示出了很高的辨别能力。所提出的 DSS 由两步特征选择和决策树组成,其输出结果由三种高度区分的蛋白质组成:TOP1、PDIA4 和 OGN,这可能对进一步的临床和实验验证感兴趣。此外,我们利用特征选择步骤中生成的蛋白质排名列表进行途径分析,以提供 HGSOC 主要失调途径的快照。本研究中使用的数据集可在临床蛋白质组肿瘤分析联盟 (CPTAC) 数据门户 ( https://cptac-data-portal.georgetown.edu/ ) 中获得。