Gurugubelli Venkata Sukumar, Fang Hua, Shikany James M, Balkus Salvador V, Rumbut Joshua, Ngo Hieu, Wang Honggang, Allison Jeroan J, Steffen Lyn M
University of Massachusetts Dartmouth, 285 Old Westport Rd, North Dartmouth, 02747, Massachusetts, USA.
Department of Quantitative Health Sciences, University of Massachusetts Medical School, 55 N Lake Ave, Worcester, 01655, Massachusetts, USA.
Smart Health (Amst). 2022 Mar;23. doi: 10.1016/j.smhl.2021.100263. Epub 2022 Jan 13.
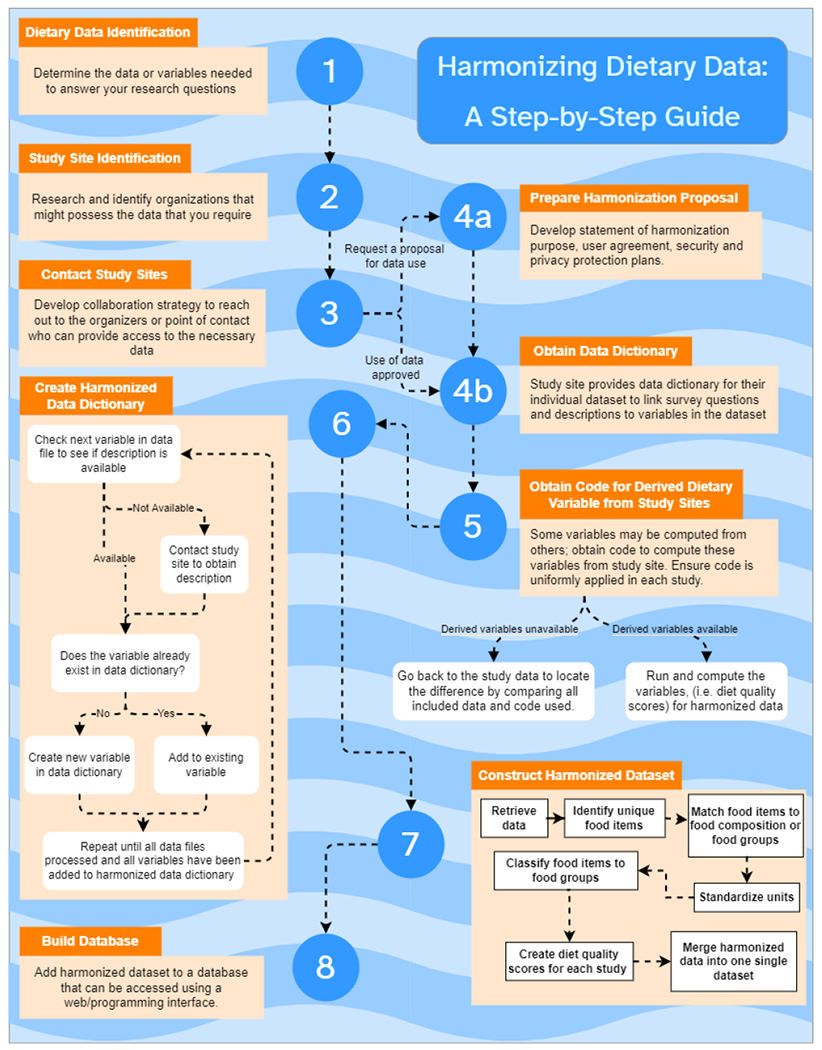
Data harmonization is the process by which each of the variables from different research studies are standardized to similar units resulting in comparable datasets. These data may be integrated for more powerful and accurate examination and prediction of outcomes for use in the intelligent and smart electronic health software programs and systems. Prospective harmonization is performed when researchers create guidelines for gathering and managing the data before data collection begins. In contrast, retrospective harmonization is performed by pooling previously collected data from various studies using expert domain knowledge to identify and translate variables. In nutritional epidemiology, dietary data harmonization is often necessary to construct the nutrient and food databases necessary to answer complex research questions and develop effective public health policy. In this paper, we review methods for effective data harmonization, including developing a harmonization plan, which common standards already exist for harmonization, and defining variables needed to harmonize datasets. Currently, several large-scale studies maintain harmonized nutrient databases, especially in Europe, and steps have been proposed to inform the retrospective harmonization process. As an example, data harmonization methods are applied to several U.S longitudinal diet datasets. Based on our review, considerations for future dietary data harmonization include user agreements for sharing private data among participating studies, defining variables and data dictionaries that accurately map variables among studies, and the use of secure data storage servers to maintain privacy. These considerations establish necessary components of harmonized data for smart health applications which can promote healthier eating and provide greater insights into the effect of dietary patterns on health.
数据协调是一个过程,通过该过程,来自不同研究的每个变量都被标准化为相似的单位,从而产生可比较的数据集。这些数据可以被整合起来,以便更有力、准确地检查和预测结果,用于智能电子健康软件程序和系统。前瞻性协调是在研究人员在数据收集开始前制定数据收集和管理指南时进行的。相比之下,回顾性协调是通过利用专家领域知识汇总先前从各种研究中收集的数据来识别和转换变量来进行的。在营养流行病学中,饮食数据协调通常是构建回答复杂研究问题和制定有效公共卫生政策所需的营养和食物数据库所必需的。在本文中,我们回顾了有效的数据协调方法,包括制定协调计划、哪些协调的通用标准已经存在,以及定义协调数据集所需的变量。目前,有几项大规模研究维护着协调的营养数据库,尤其是在欧洲,并且已经提出了一些步骤来指导回顾性协调过程。例如,数据协调方法被应用于几个美国纵向饮食数据集。基于我们的综述,未来饮食数据协调的考虑因素包括参与研究之间共享私人数据的用户协议、定义准确映射研究之间变量的变量和数据字典,以及使用安全的数据存储服务器来维护隐私。这些考虑因素确立了智能健康应用中协调数据的必要组成部分,这些应用可以促进更健康的饮食,并提供对饮食模式对健康影响的更深入洞察。