Department of Chemical and Biomolecular Engineering, University of Maryland, College Park, Maryland, United States of America.
PLoS Comput Biol. 2022 Mar 24;18(3):e1009831. doi: 10.1371/journal.pcbi.1009831. eCollection 2022 Mar.
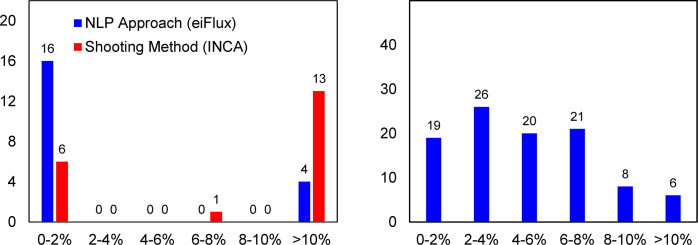
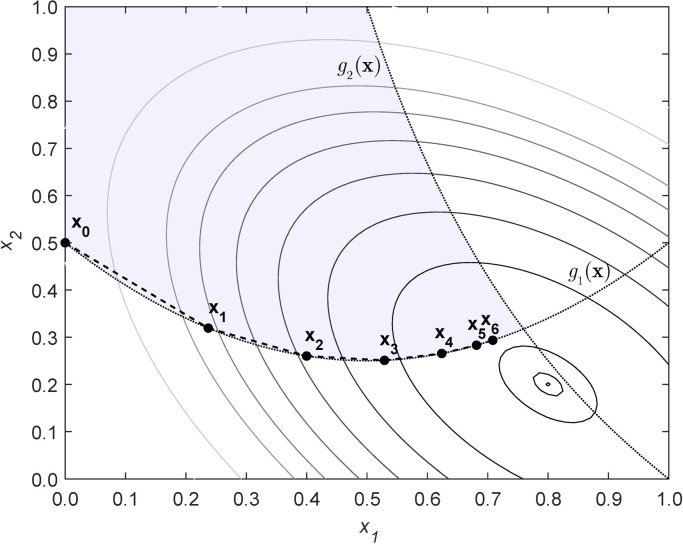
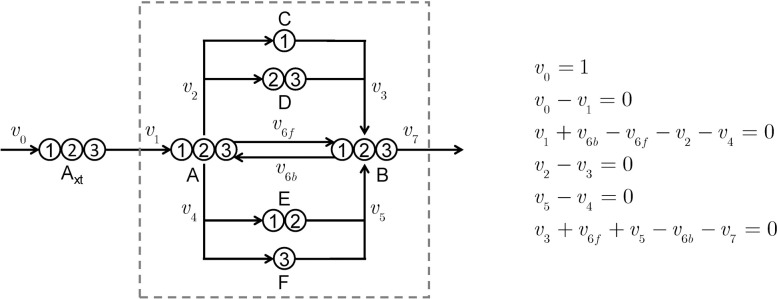
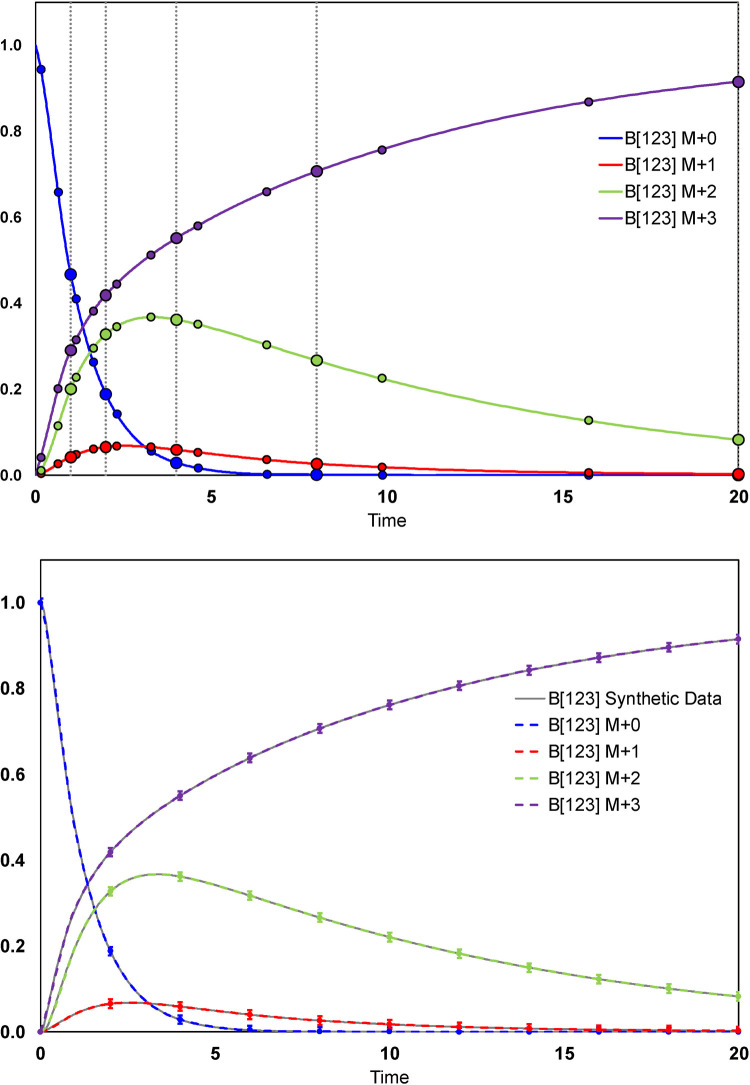
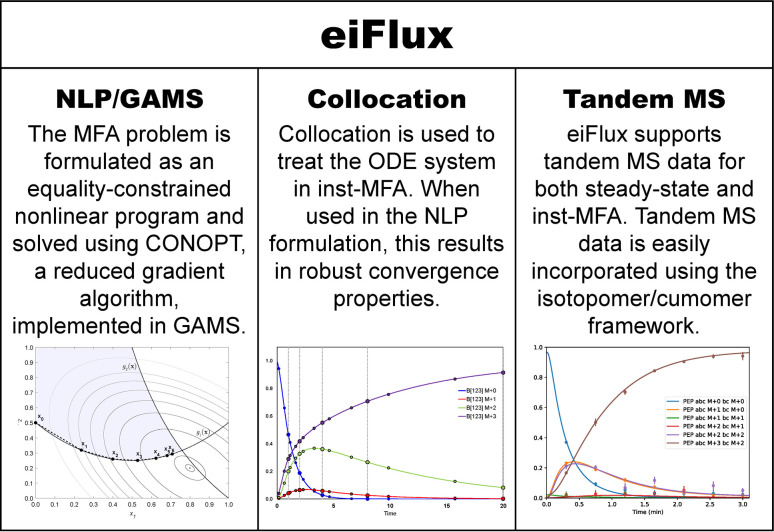
Stable isotope-assisted metabolic flux analysis (MFA) is a powerful method to estimate carbon flow and partitioning in metabolic networks. At its core, MFA is a parameter estimation problem wherein the fluxes and metabolite pool sizes are model parameters that are estimated, via optimization, to account for measurements of steady-state or isotopically-nonstationary isotope labeling patterns. As MFA problems advance in scale, they require efficient computational methods for fast and robust convergence. The structure of the MFA problem enables it to be cast as an equality-constrained nonlinear program (NLP), where the equality constraints are constructed from the MFA model equations, and the objective function is defined as the sum of squared residuals (SSR) between the model predictions and a set of labeling measurements. This NLP can be solved by using an algebraic modeling language (AML) that offers state-of-the-art optimization solvers for robust parameter estimation and superior scalability to large networks. When implemented in this manner, the optimization is performed with no distinction between state variables and model parameters. During each iteration of such an optimization, the system state is updated instead of being calculated explicitly from scratch, and this occurs concurrently with improvement in the model parameter estimates. This optimization approach starkly contrasts with traditional "shooting" methods where the state variables and model parameters are kept distinct and the system state is computed afresh during each iteration of a stepwise optimization. Our NLP formulation uses the MFA modeling framework of Wiechert et al. [1], which is amenable to incorporation of the model equations into an NLP. The NLP constraints consist of balances on either elementary metabolite units (EMUs) or cumomers. In this formulation, both the steady-state and isotopically-nonstationary MFA (inst-MFA) problems may be solved as an NLP. For the inst-MFA case, the ordinary differential equation (ODE) system describing the labeling dynamics is transcribed into a system of algebraic constraints for the NLP using collocation. This large-scale NLP may be solved efficiently using an NLP solver implemented on an AML. In our implementation, we used the reduced gradient solver CONOPT, implemented in the General Algebraic Modeling System (GAMS). The NLP framework is particularly advantageous for inst-MFA, scaling well to large networks with many free parameters, and having more robust convergence properties compared to the shooting methods that compute the system state and sensitivities at each iteration. Additionally, this NLP approach supports the use of tandem-MS data for both steady-state and inst-MFA when the cumomer framework is used. We assembled a software, eiFlux, written in Python and GAMS that uses the NLP approach and supports both steady-state and inst-MFA. We demonstrate the effectiveness of the NLP formulation on several examples, including a genome-scale inst-MFA model, to highlight the scalability and robustness of this approach. In addition to typical inst-MFA applications, we expect that this framework and our associated software, eiFlux, will be particularly useful for applying inst-MFA to complex MFA models, such as those developed for eukaryotes (e.g. algae) and co-cultures with multiple cell types.
稳定同位素辅助代谢通量分析(MFA)是一种估计代谢网络中碳流量和分配的强大方法。在其核心,MFA 是一个参数估计问题,其中通量和代谢物池大小是通过优化来估计的模型参数,以解释稳态或同位素非稳态同位素标记模式的测量结果。随着 MFA 问题的规模推进,它们需要高效的计算方法来实现快速和稳健的收敛。MFA 问题的结构使其能够被表示为等式约束非线性规划(NLP),其中等式约束是由 MFA 模型方程构建的,目标函数定义为模型预测与一组标记测量之间的平方残差(SSR)的和。这种 NLP 可以使用代数建模语言(AML)来解决,AML 为稳健的参数估计和对大型网络的卓越可扩展性提供了最先进的优化求解器。以这种方式实现时,优化在没有区分状态变量和模型参数的情况下进行。在这种优化的每次迭代中,系统状态都会更新,而不是从头开始显式计算,并且在模型参数估计改进的同时进行。这种优化方法与传统的“拍摄”方法形成鲜明对比,在传统方法中,状态变量和模型参数保持不同,并且在逐步优化的每次迭代中都要重新计算系统状态。我们的 NLP 公式使用 Wiechert 等人的 MFA 建模框架 [1],该框架可用于将模型方程纳入 NLP。NLP 约束包括基本代谢物单位(EMU)或 cumomer 的平衡。在这种配方中,稳态和同位素非稳态 MFA(inst-MFA)问题都可以作为 NLP 来解决。对于 inst-MFA 情况,描述标记动力学的常微分方程(ODE)系统使用配置法转录为 NLP 的代数约束系统。使用在 AML 上实现的 NLP 求解器可以有效地解决这个大规模的 NLP。在我们的实现中,我们使用了简化梯度求解器 CONOPT,它在通用代数建模系统(GAMS)中实现。NLP 框架对于 inst-MFA 特别有利,它可以很好地扩展到具有许多自由参数的大型网络,并且与计算系统状态和灵敏度的拍摄方法相比,具有更稳健的收敛特性。此外,当使用 cumomer 框架时,这种 NLP 方法支持对稳态和 inst-MFA 同时使用串联-MS 数据。我们编写了一个名为 eiFlux 的软件,该软件使用 NLP 方法,用 Python 和 GAMS 编写,支持稳态和 inst-MFA。我们通过几个示例展示了 NLP 公式的有效性,包括一个基因组规模的 inst-MFA 模型,以突出这种方法的可扩展性和稳健性。除了典型的 inst-MFA 应用外,我们预计这个框架和我们的相关软件 eiFlux 将特别有用,可用于将 inst-MFA 应用于复杂的 MFA 模型,例如为真核生物(例如藻类)和具有多种细胞类型的共培养物开发的模型。