Department of Environmental Microbiology, Helmholtz Centre for Environmental Research - UFZ, Leipzig, Germany.
Institute for Bioengineering and Biosciences, Department of Bioengineering, Instituto Superior Técnico Universidade de Lisboa, Lisbon, Portugal.
Microbiome. 2022 Mar 25;10(1):48. doi: 10.1186/s40168-021-01219-2.
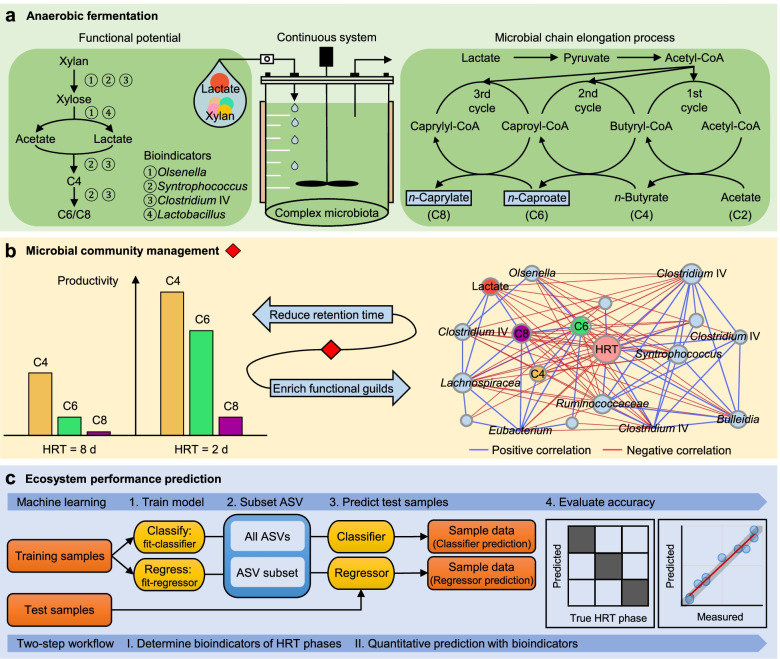
The ability to quantitatively predict ecophysiological functions of microbial communities provides an important step to engineer microbiota for desired functions related to specific biochemical conversions. Here, we present the quantitative prediction of medium-chain carboxylate production in two continuous anaerobic bioreactors from 16S rRNA gene dynamics in enriched communities.
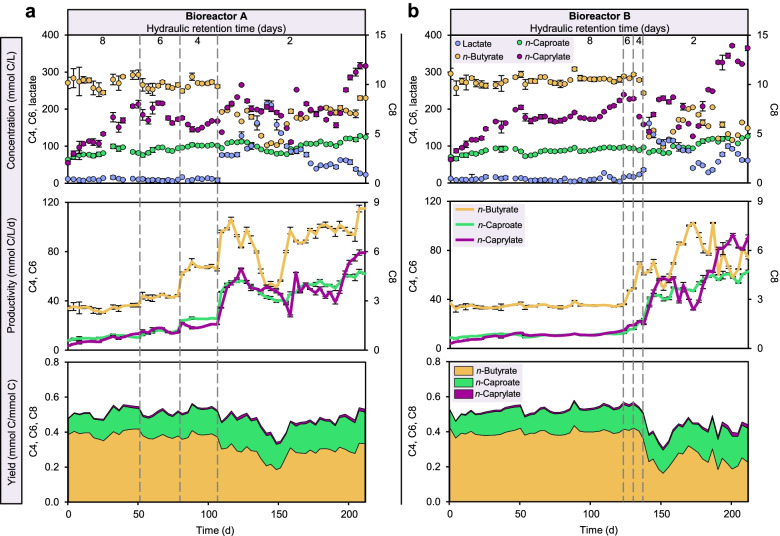
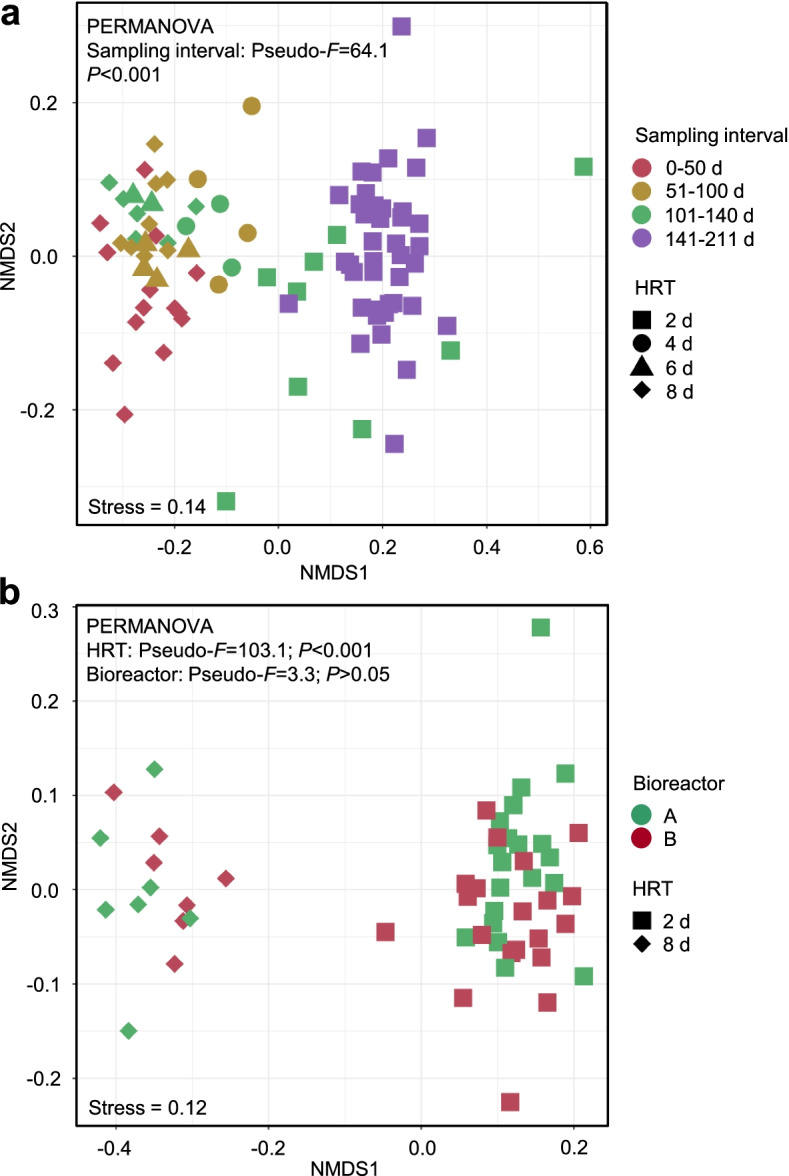
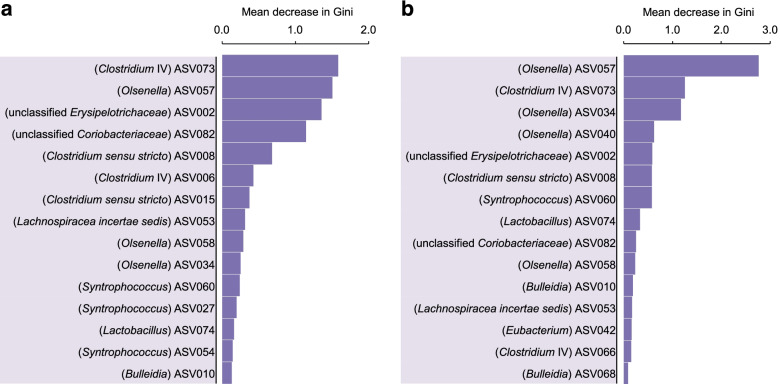
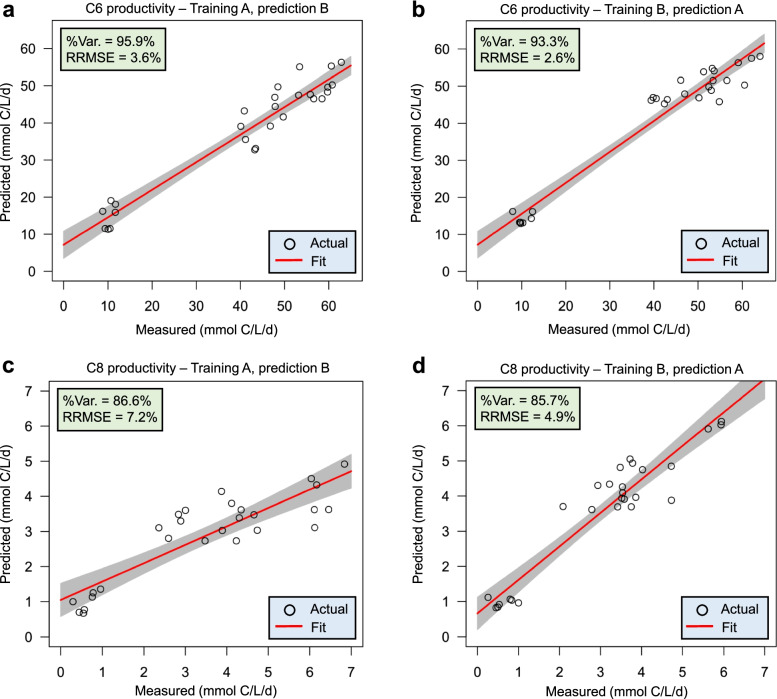
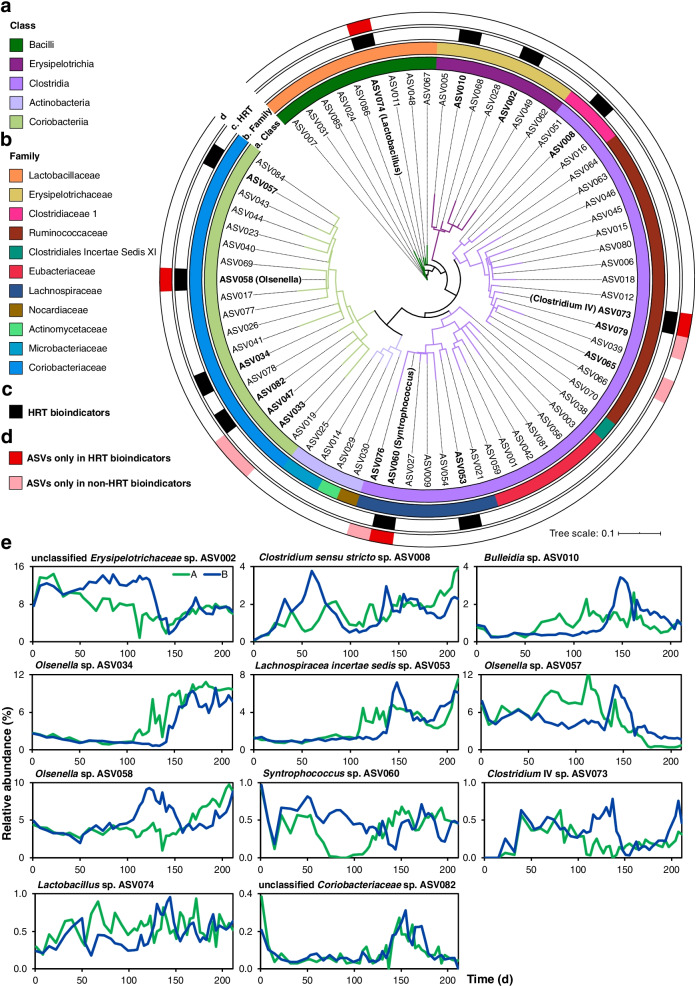
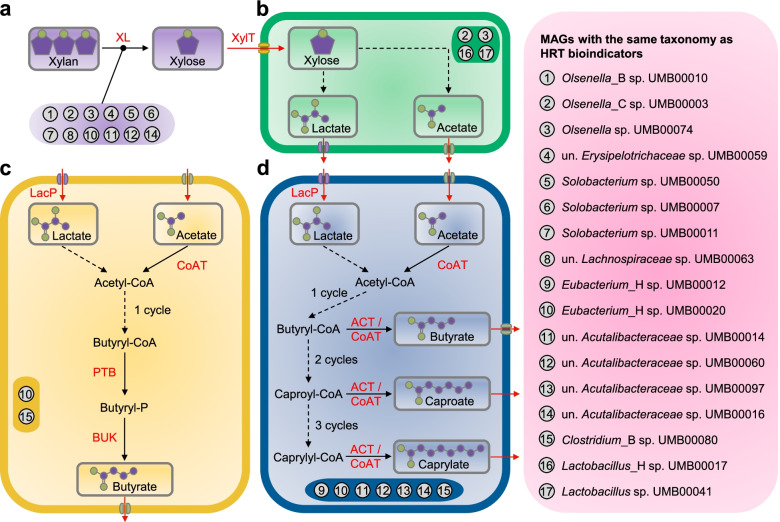
By progressively shortening the hydraulic retention time (HRT) from 8 to 2 days with different temporal schemes in two bioreactors operated for 211 days, we achieved higher productivities and yields of the target products n-caproate and n-caprylate. The datasets generated from each bioreactor were applied independently for training and testing machine learning algorithms using 16S rRNA genes to predict n-caproate and n-caprylate productivities. Our dataset consisted of 14 and 40 samples from HRT of 8 and 2 days, respectively. Because of the size and balance of our dataset, we compared linear regression, support vector machine and random forest regression algorithms using the original and balanced datasets generated using synthetic minority oversampling. Further, we performed cross-validation to estimate model stability. The random forest regression was the best algorithm producing more consistent results with median of error rates below 8%. More than 90% accuracy in the prediction of n-caproate and n-caprylate productivities was achieved. Four inferred bioindicators belonging to the genera Olsenella, Lactobacillus, Syntrophococcus and Clostridium IV suggest their relevance to the higher carboxylate productivity at shorter HRT. The recovery of metagenome-assembled genomes of these bioindicators confirmed their genetic potential to perform key steps of medium-chain carboxylate production.
Shortening the hydraulic retention time of the continuous bioreactor systems allows to shape the communities with desired chain elongation functions. Using machine learning, we demonstrated that 16S rRNA amplicon sequencing data can be used to predict bioreactor process performance quantitatively and accurately. Characterizing and harnessing bioindicators holds promise to manage reactor microbiota towards selection of the target processes. Our mathematical framework is transferrable to other ecosystem processes and microbial systems where community dynamics is linked to key functions. The general methodology used here can be adapted to data types of other functional categories such as genes, transcripts, proteins or metabolites. Video Abstract.
定量预测微生物群落的生态生理学功能为实现与特定生化转化相关的功能而对微生物群落进行工程改造提供了重要步骤。在这里,我们根据富集群落中的 16S rRNA 基因动态,定量预测了两个连续厌氧生物反应器中中链羧酸的产生。
通过在两个生物反应器中以不同的时间方案逐渐将水力停留时间(HRT)从 8 天缩短至 2 天,我们在运行 211 天的情况下实现了目标产物正己酸和正辛酸的更高生产力和产率。从每个生物反应器生成的数据集分别用于训练和测试使用 16S rRNA 基因预测正己酸和正辛酸生产力的机器学习算法。我们的数据集由分别来自 HRT 为 8 天和 2 天的 14 个和 40 个样本组成。由于数据集的大小和平衡,我们比较了使用原始数据集和使用合成少数族裔过采样生成的平衡数据集的线性回归、支持向量机和随机森林回归算法。此外,我们进行了交叉验证以估计模型稳定性。随机森林回归是最好的算法,其误差率中位数低于 8%,结果更为一致。在正己酸和正辛酸生产力的预测中,达到了 90%以上的准确率。属于 Olsenella、Lactobacillus、Syntrophococcus 和 Clostridium IV 属的四个推断的生物标志物表明它们与较短 HRT 下更高的羧酸产量相关。这些生物标志物的宏基因组组装基因组的恢复证实了它们在进行中链羧酸产生的关键步骤中的遗传潜力。
缩短连续生物反应器系统的水力停留时间可以使群落具有所需的链延伸功能。使用机器学习,我们证明了 16S rRNA 扩增子测序数据可用于定量和准确地预测生物反应器过程性能。对生物标志物进行特征描述和利用有望实现对反应器微生物群落的管理,以选择目标过程。我们的数学框架可应用于其他生态系统过程和微生物系统,其中群落动态与关键功能相关。这里使用的一般方法可以适用于其他功能类别(如基因、转录本、蛋白质或代谢物)的数据类型。