Tong Qianqian, Liang Guannan, Bi Jinbo
Computer Science and Engineering, University of Connecticut, Storrs, CT 06269.
Neurocomputing (Amst). 2022 Apr 7;481:333-356. doi: 10.1016/j.neucom.2022.01.014. Epub 2022 Jan 21.
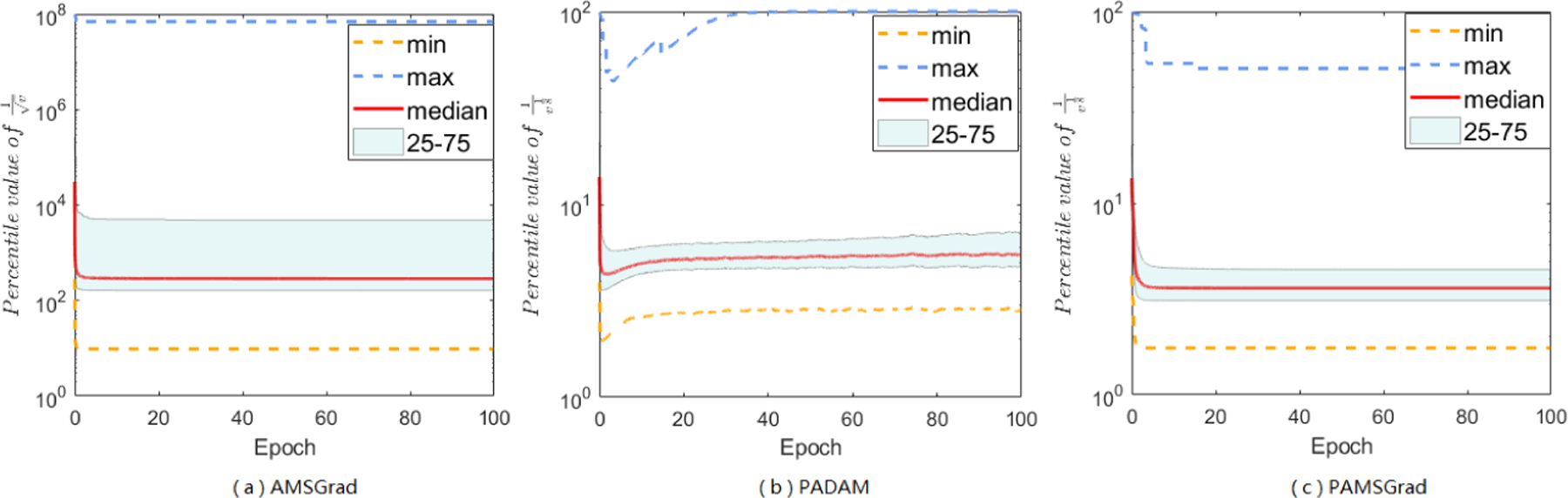
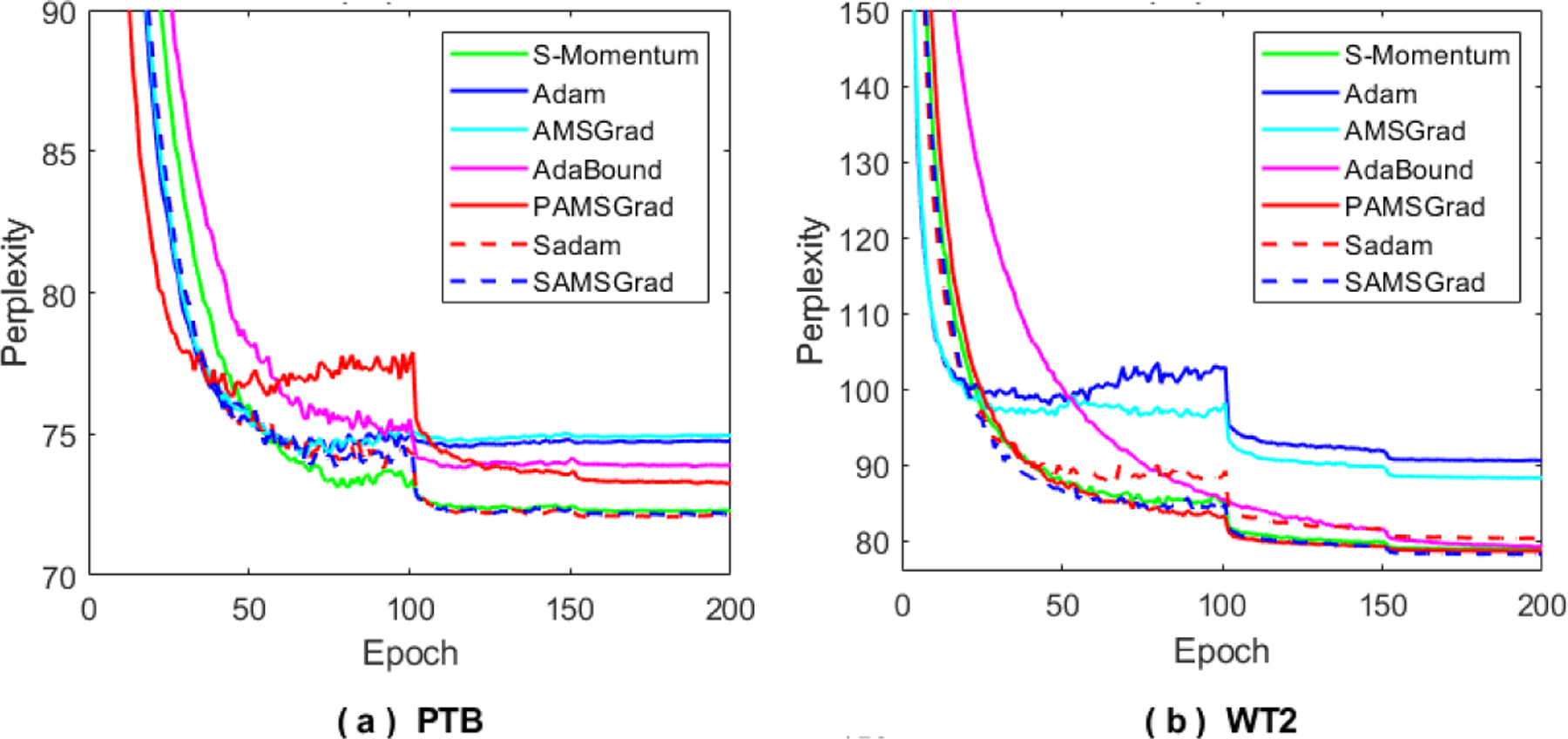
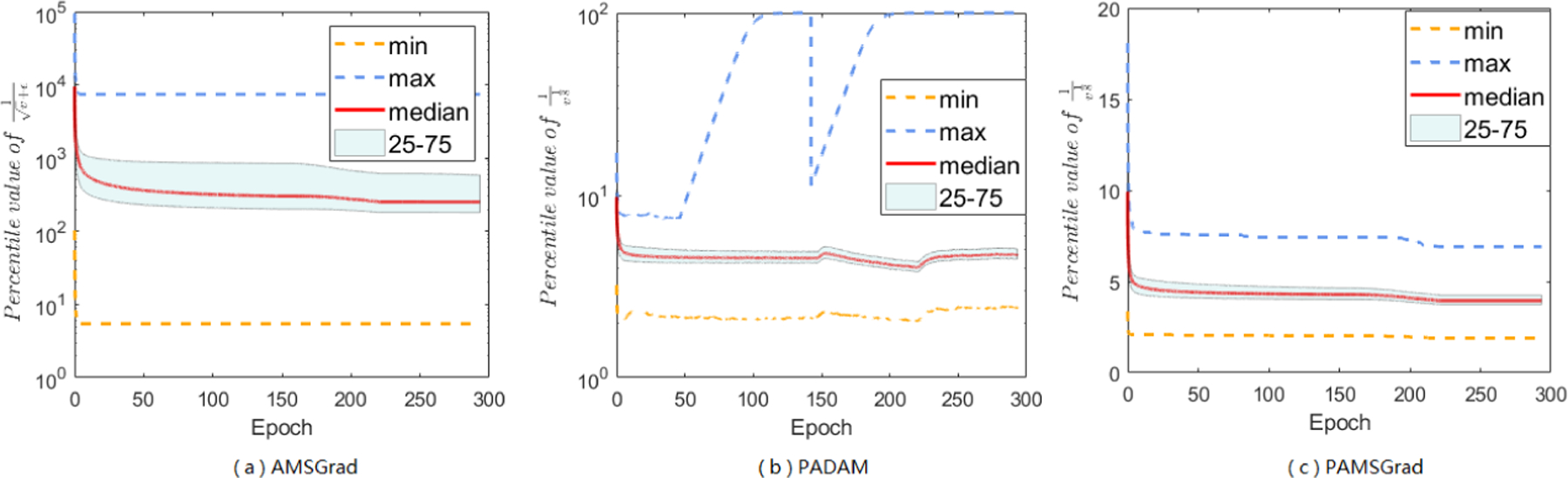
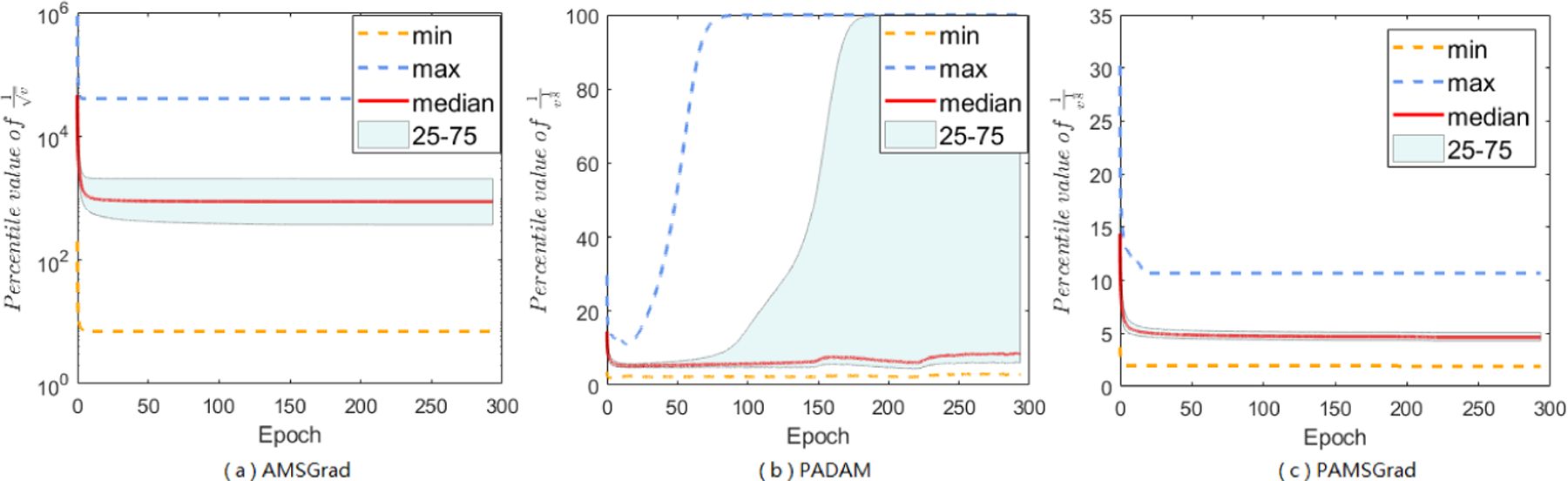
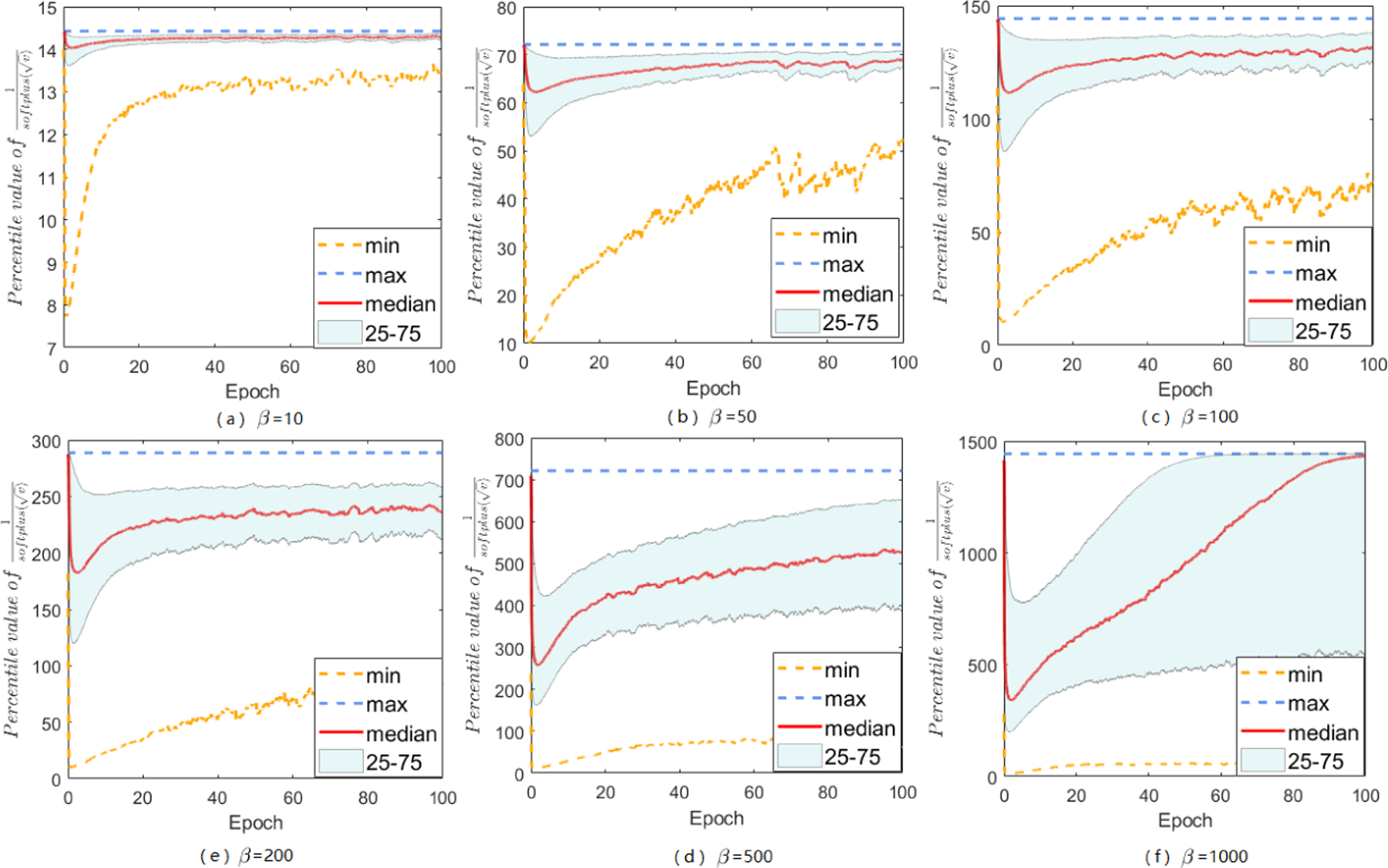
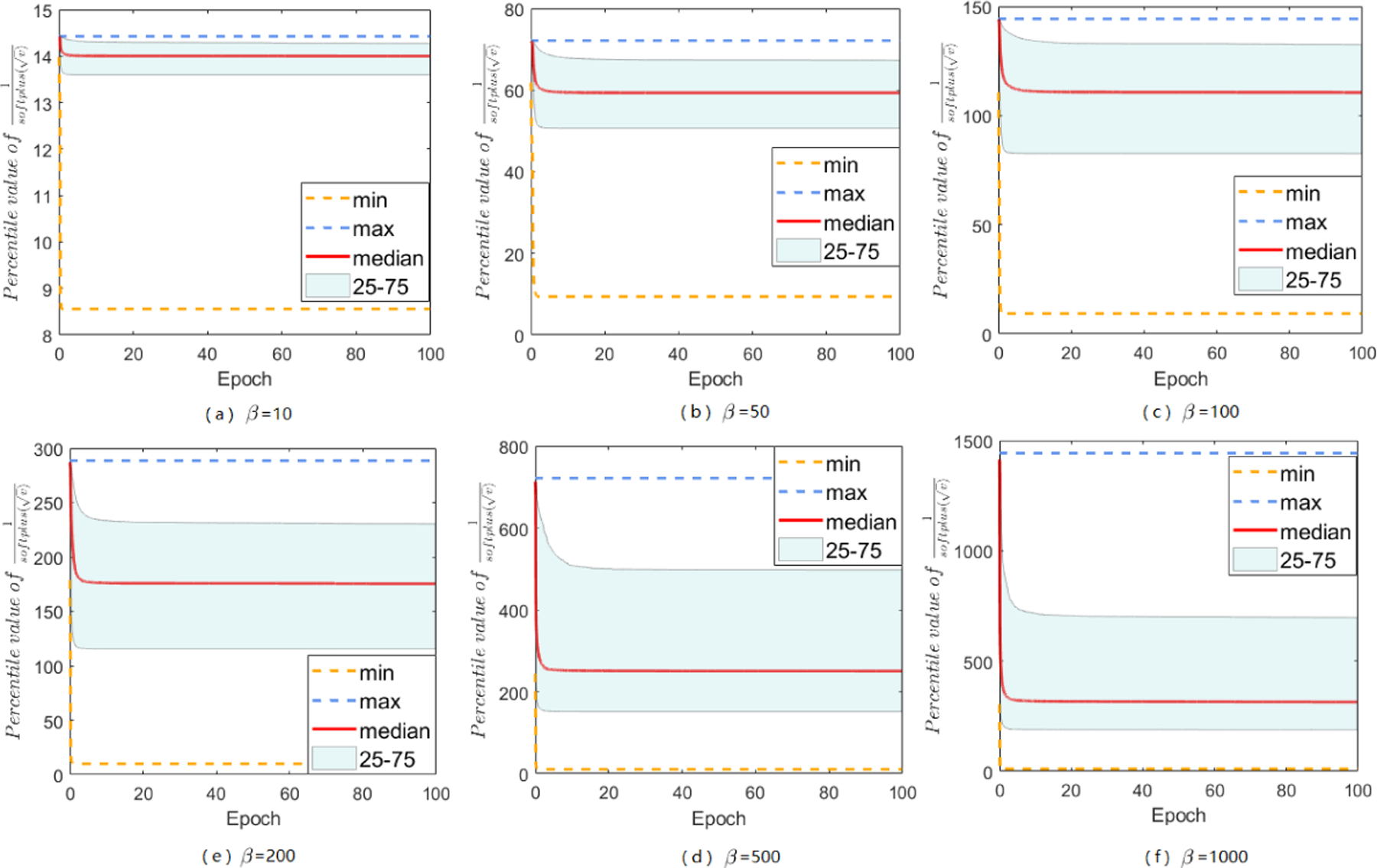
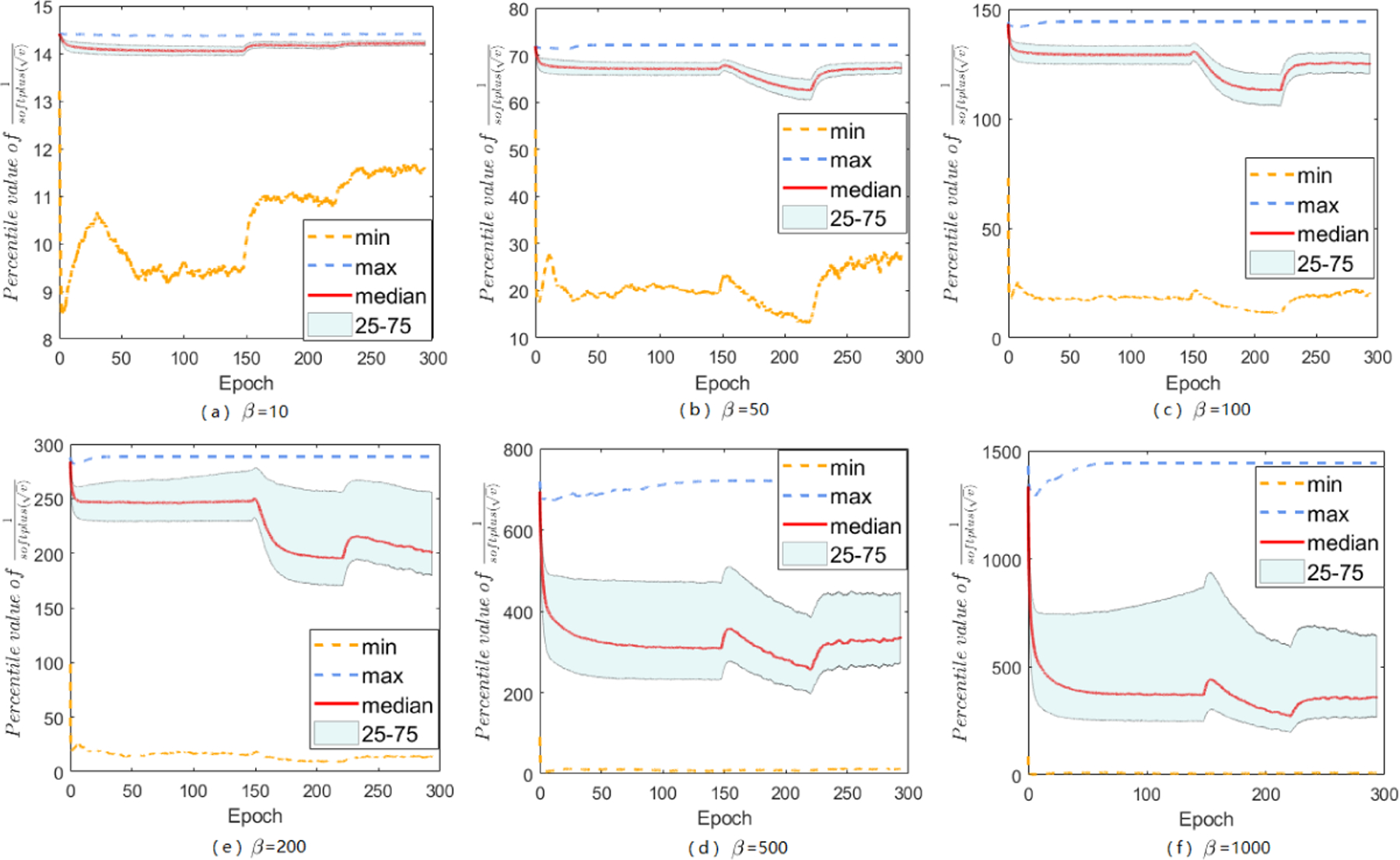
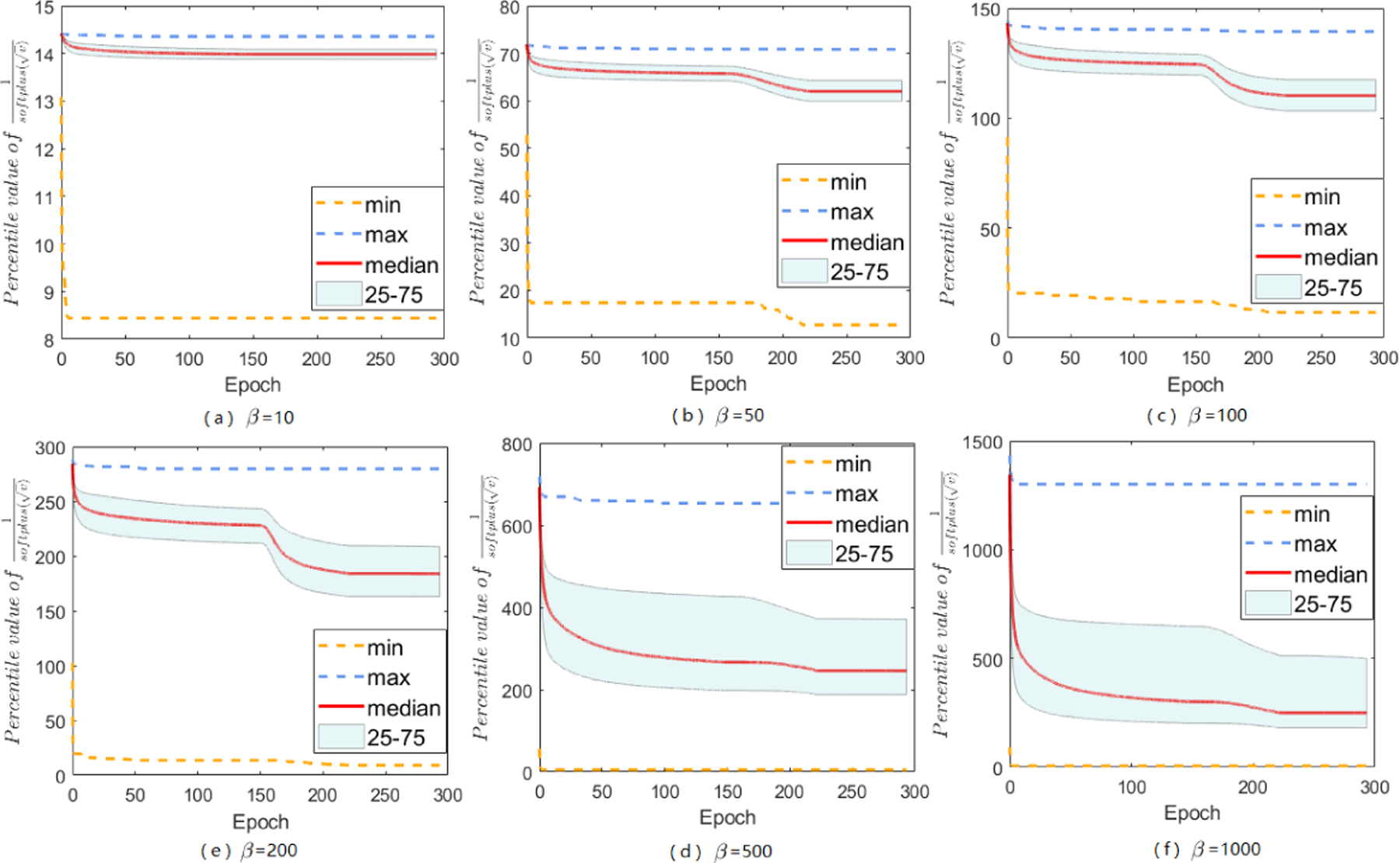
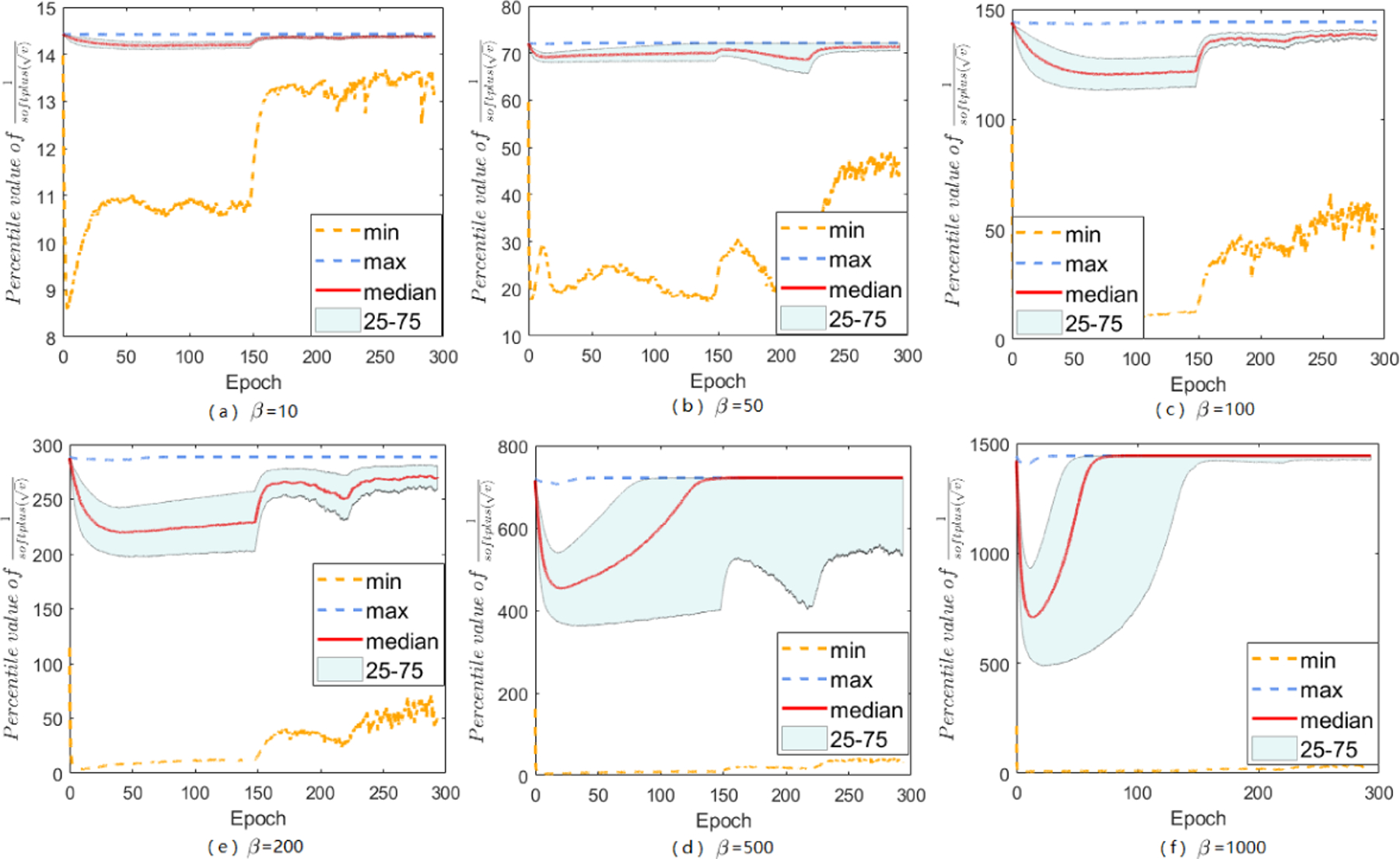
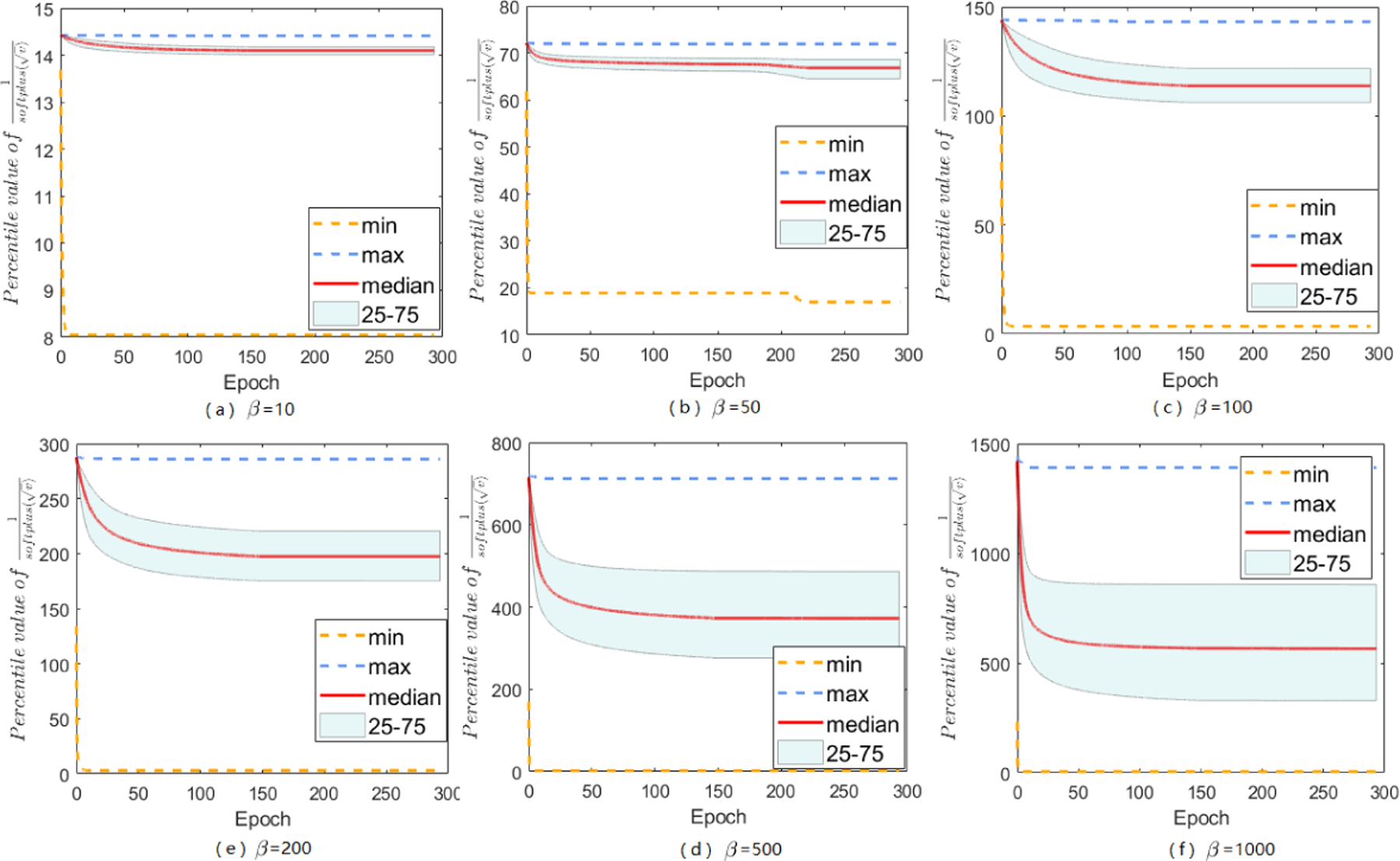
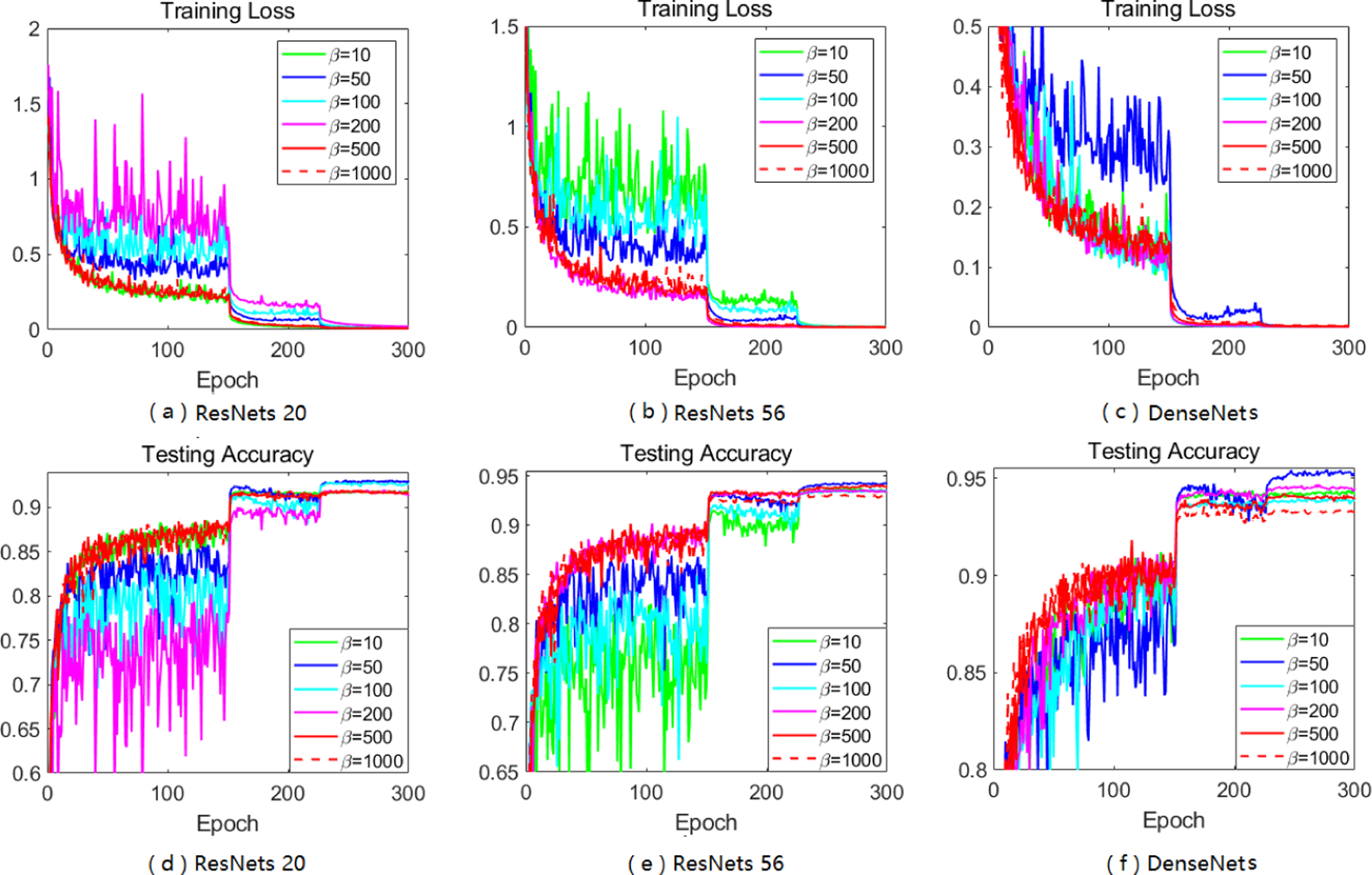
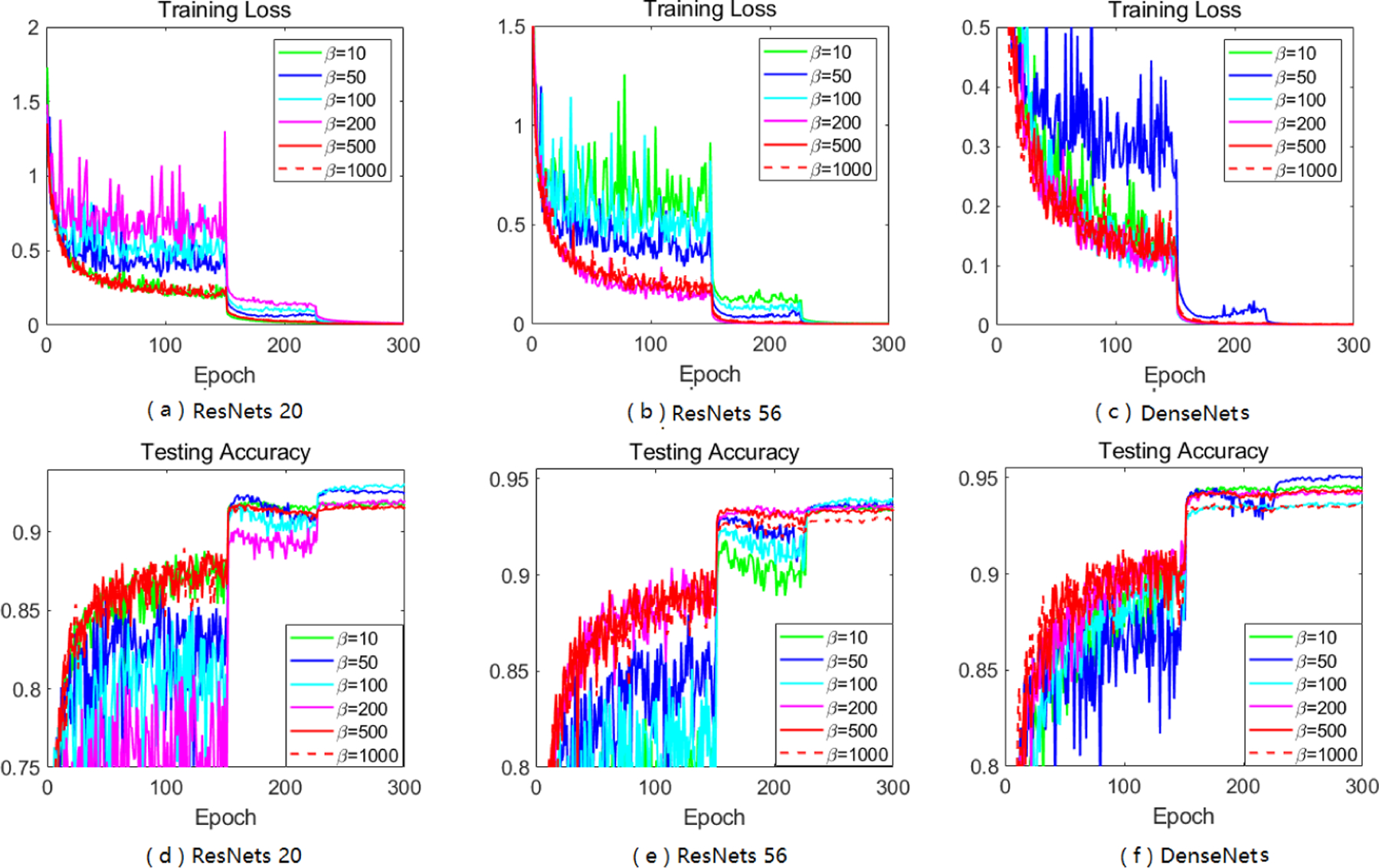
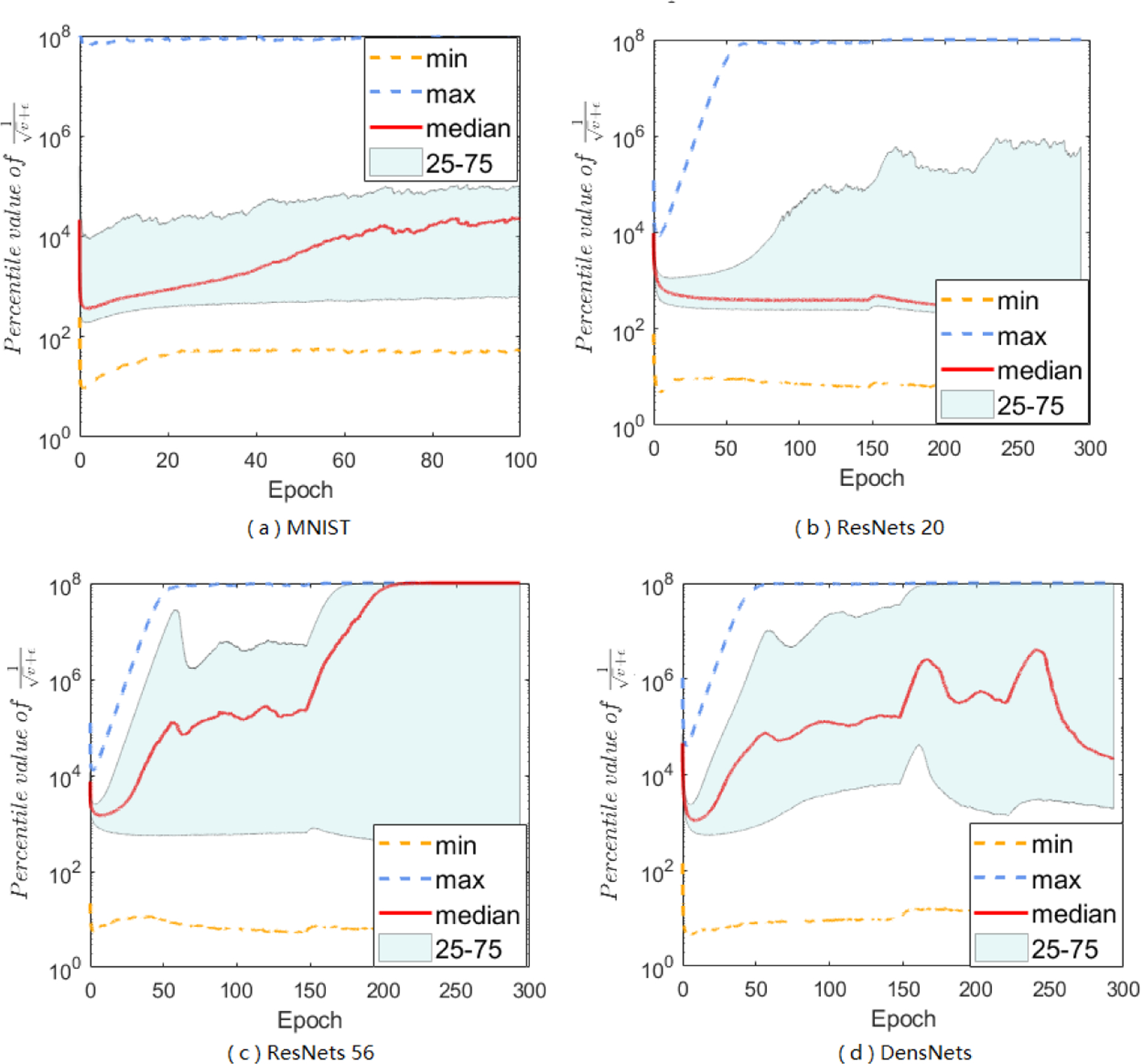
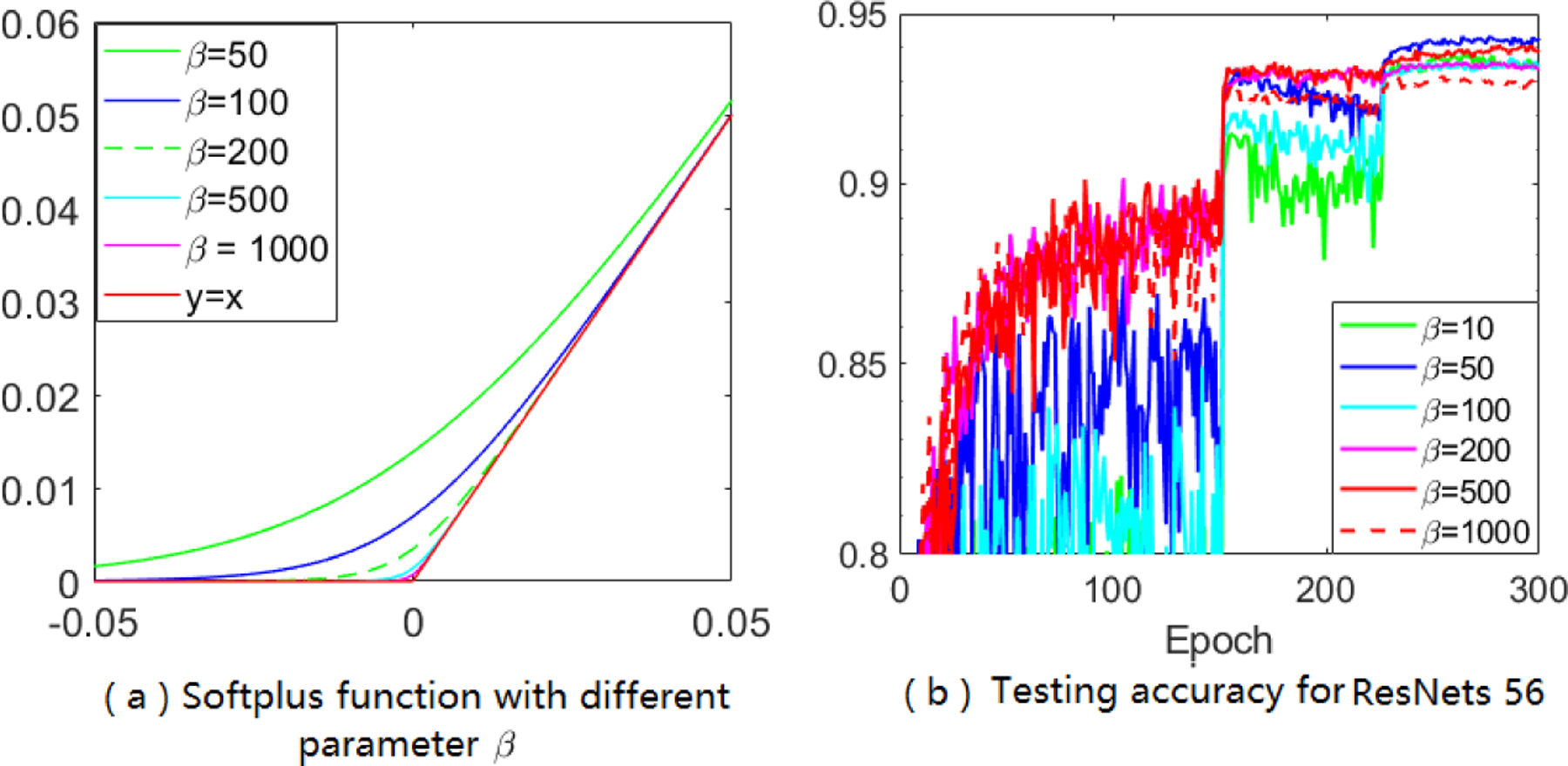
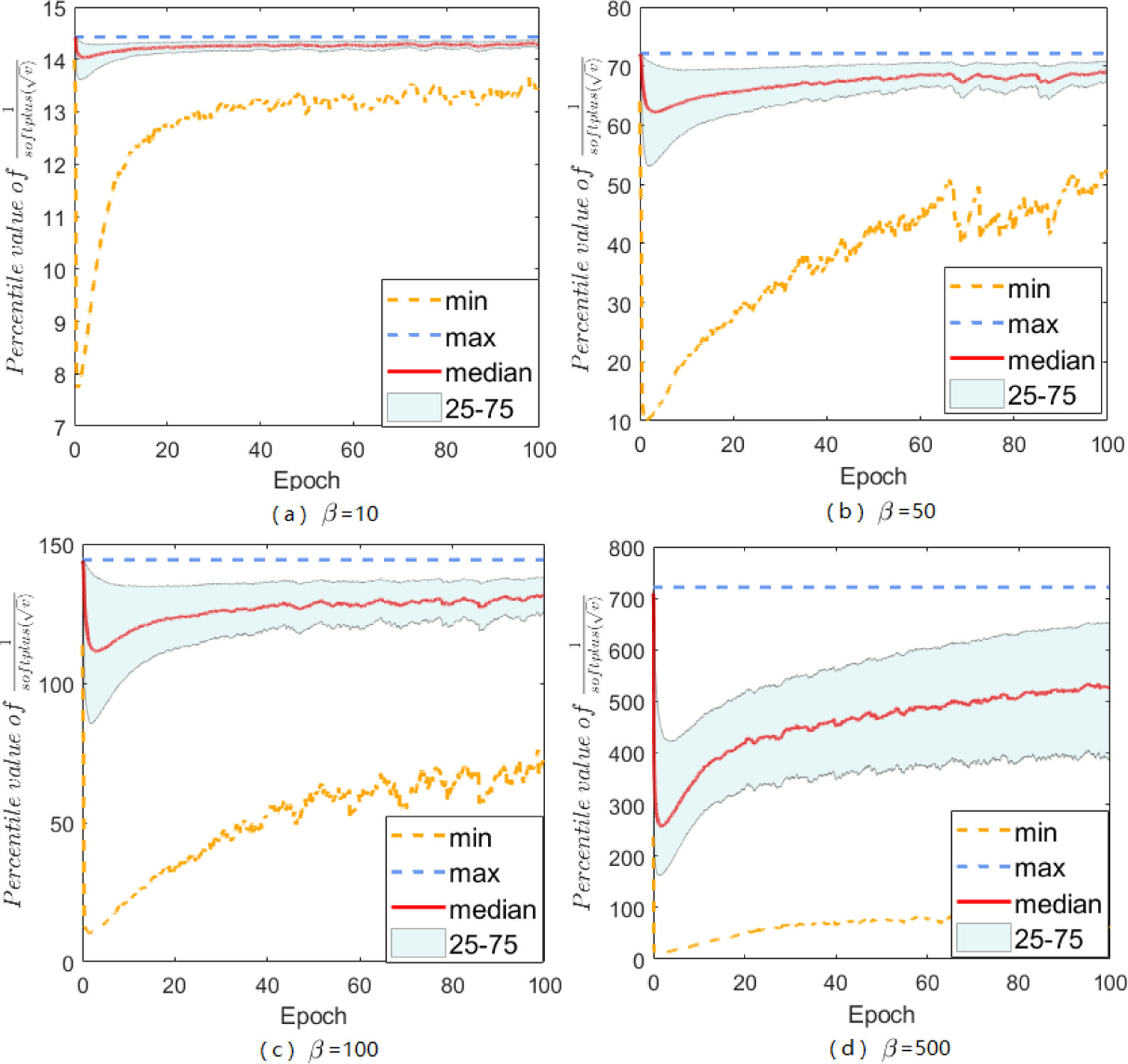
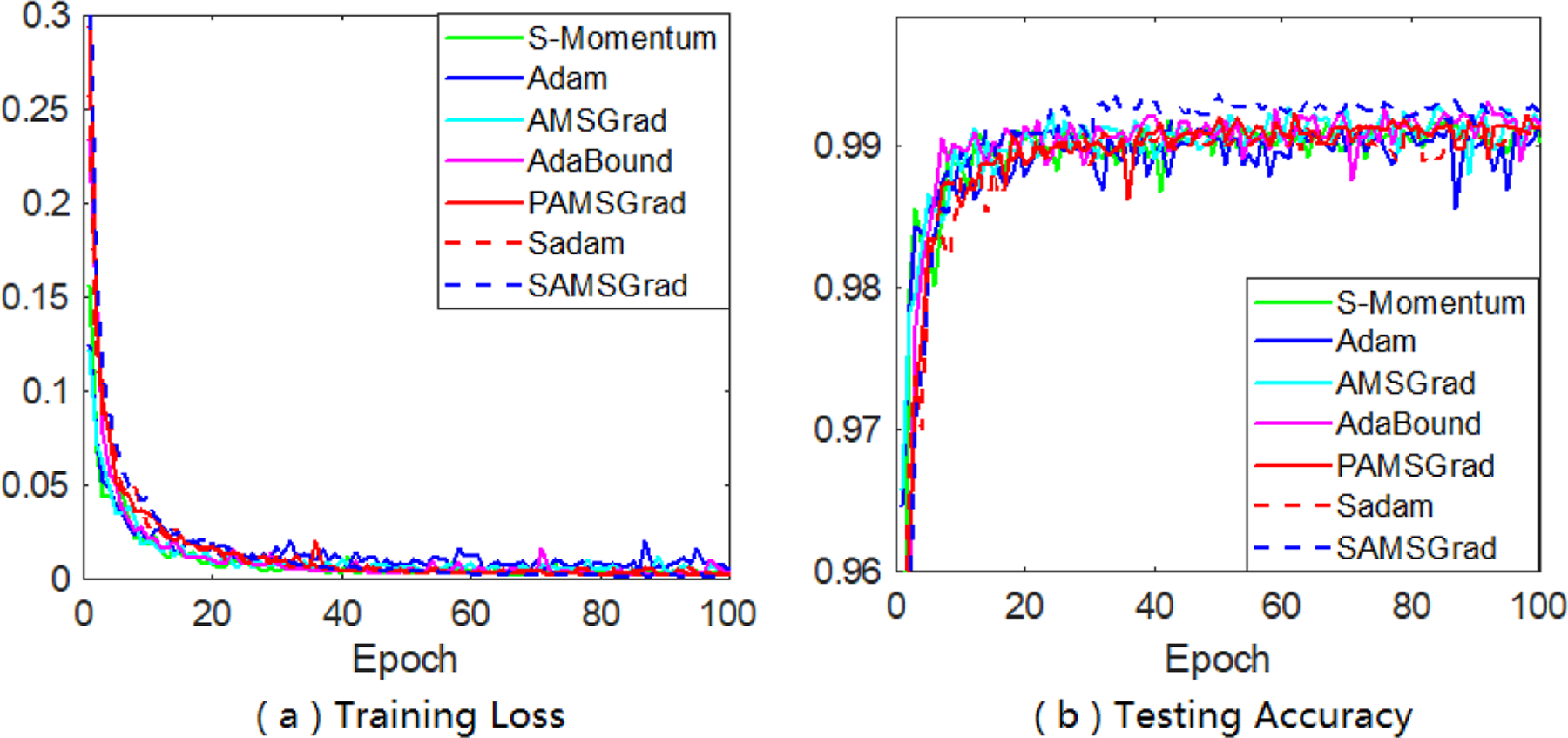
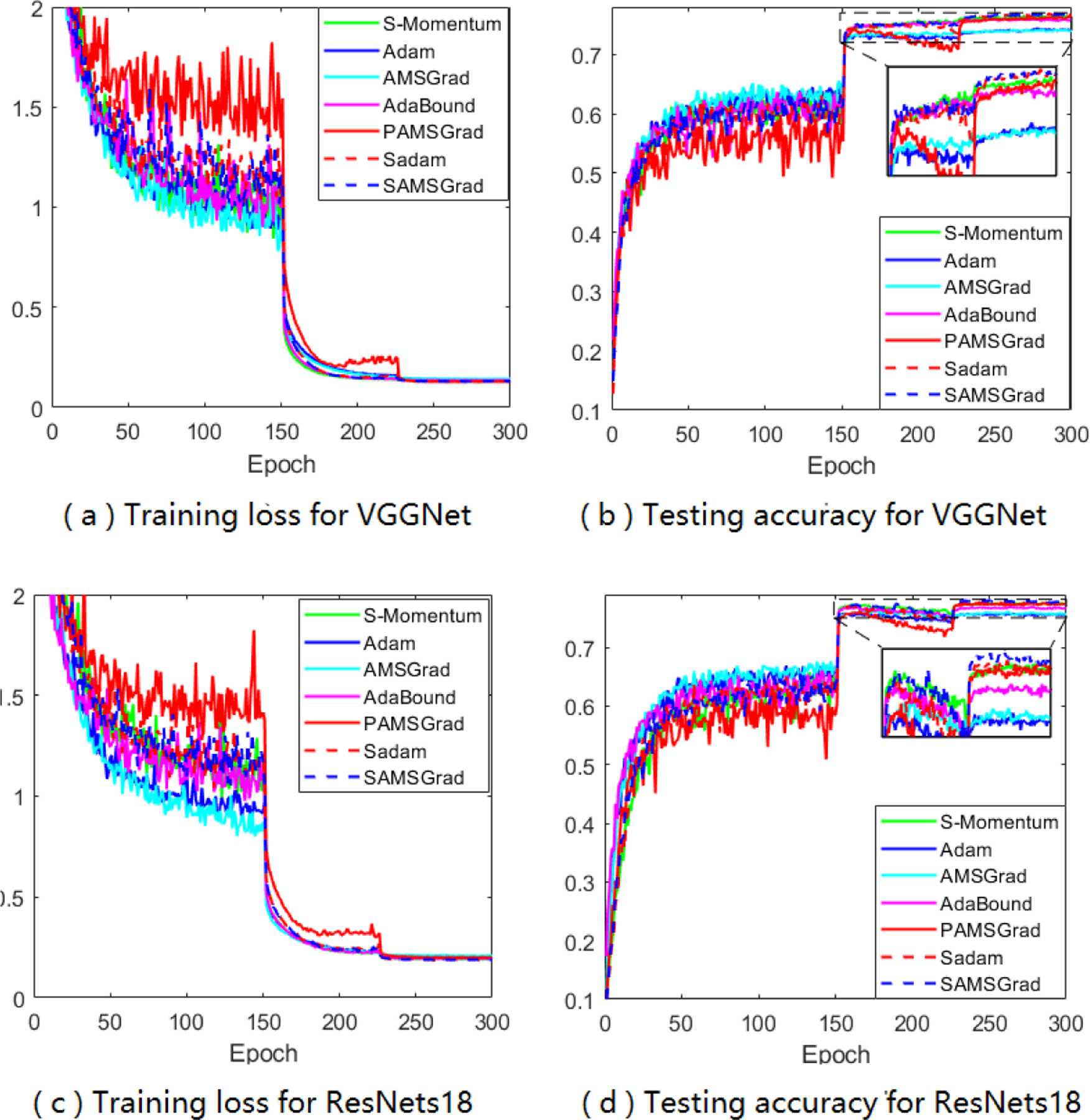
Adaptive gradient methods (AGMs) have become popular in optimizing the nonconvex problems in deep learning area. We revisit AGMs and identify that the adaptive learning rate (A-LR) used by AGMs varies significantly across the dimensions of the problem over epochs (i.e., anisotropic scale), which may lead to issues in convergence and generalization. All existing modified AGMs actually represent efforts in revising the A-LR. Theoretically, we provide a new way to analyze the convergence of AGMs and prove that the convergence rate of Adam also depends on its hyper-parameter є, which has been overlooked previously. Based on these two facts, we propose a new AGM by calibrating the A-LR with an activation () function, resulting in the Sadam and SAMSGrad methods. We further prove that these algorithms enjoy better convergence speed under nonconvex, non-strongly convex, and Polyak-Łojasiewicz conditions compared with Adam. Empirical studies support our observation of the anisotropic A-LR and show that the proposed methods outperform existing AGMs and generalize even better than S-Momentum in multiple deep learning tasks.
自适应梯度方法(AGMs)在优化深度学习领域的非凸问题中变得很流行。我们重新审视了AGMs,并发现AGMs所使用的自适应学习率(A-LR)在各个时期的问题维度上(即各向异性尺度)变化显著,这可能会导致收敛和泛化方面的问题。所有现有的改进AGMs实际上都是在努力修正A-LR。从理论上讲,我们提供了一种新的方法来分析AGMs的收敛性,并证明Adam的收敛速度也取决于其超参数є,这一点在之前被忽视了。基于这两个事实,我们通过用激活()函数校准A-LR提出了一种新的AGM,从而得到了Sadam和SAMSGrad方法。我们进一步证明,与Adam相比,这些算法在非凸、非强凸和Polyak-Łojasiewicz条件下具有更好的收敛速度。实证研究支持了我们对各向异性A-LR的观察,并表明所提出的方法在多个深度学习任务中优于现有的AGMs,甚至比S-Momentum具有更好的泛化能力。