Khurshid Shaan, Reeder Christopher, Harrington Lia X, Singh Pulkit, Sarma Gopal, Friedman Samuel F, Di Achille Paolo, Diamant Nathaniel, Cunningham Jonathan W, Turner Ashby C, Lau Emily S, Haimovich Julian S, Al-Alusi Mostafa A, Wang Xin, Klarqvist Marcus D R, Ashburner Jeffrey M, Diedrich Christian, Ghadessi Mercedeh, Mielke Johanna, Eilken Hanna M, McElhinney Alice, Derix Andrea, Atlas Steven J, Ellinor Patrick T, Philippakis Anthony A, Anderson Christopher D, Ho Jennifer E, Batra Puneet, Lubitz Steven A
Division of Cardiology, Massachusetts General Hospital, Boston, MA, USA.
Cardiovascular Research Center, Massachusetts General Hospital, Boston, MA, USA.
NPJ Digit Med. 2022 Apr 8;5(1):47. doi: 10.1038/s41746-022-00590-0.
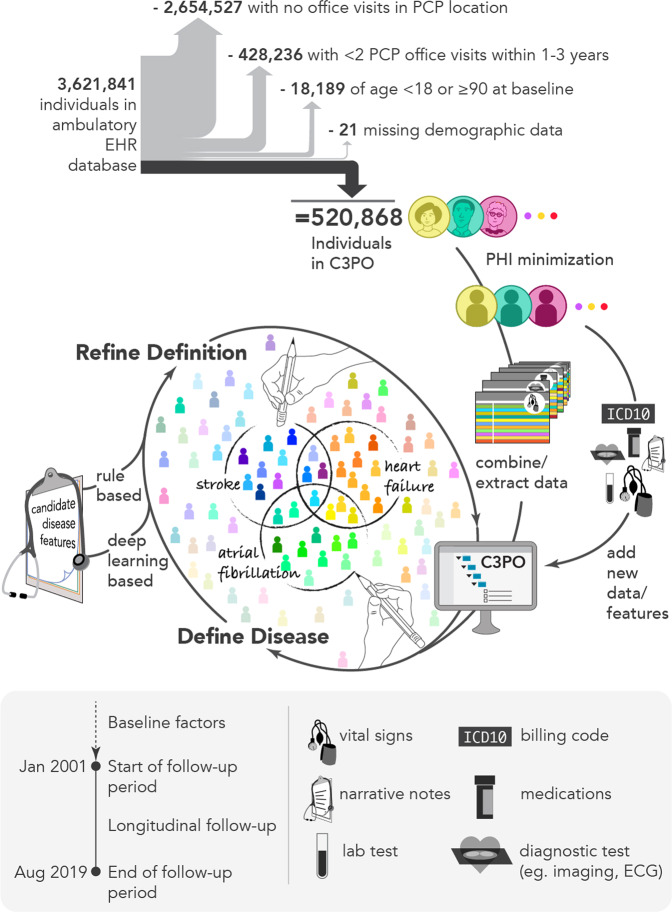
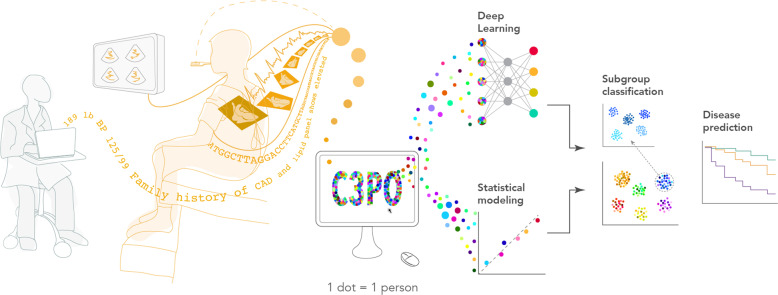
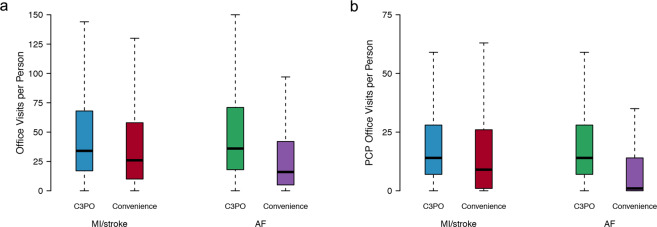
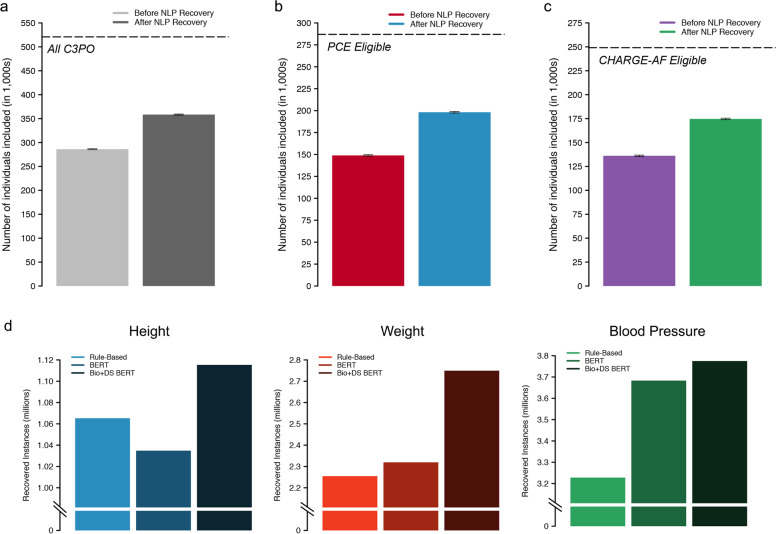
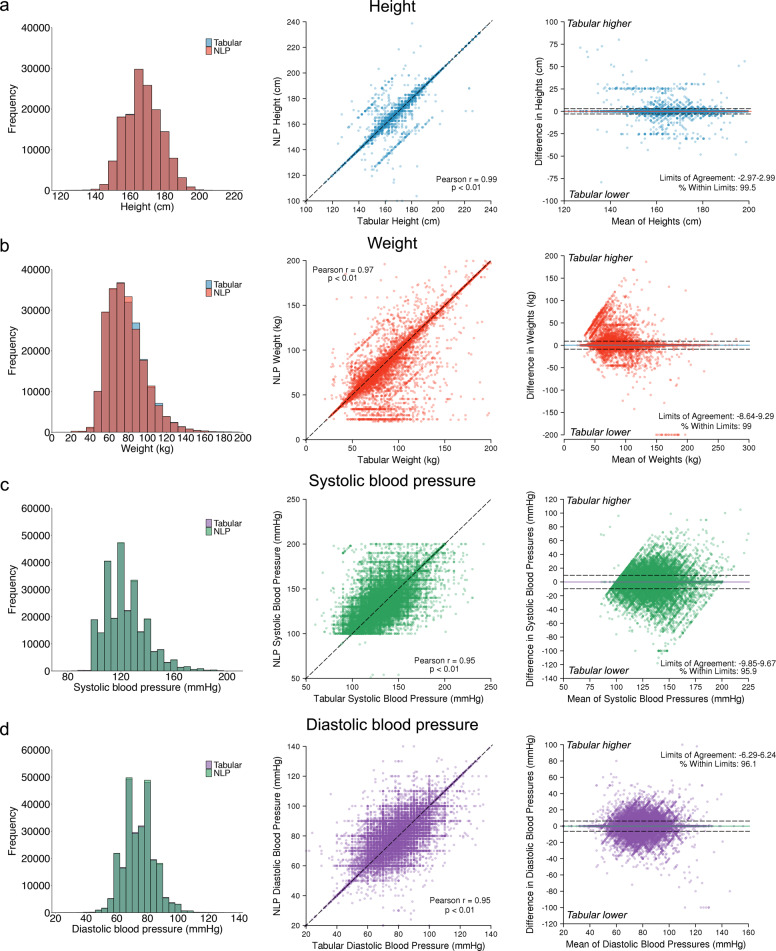
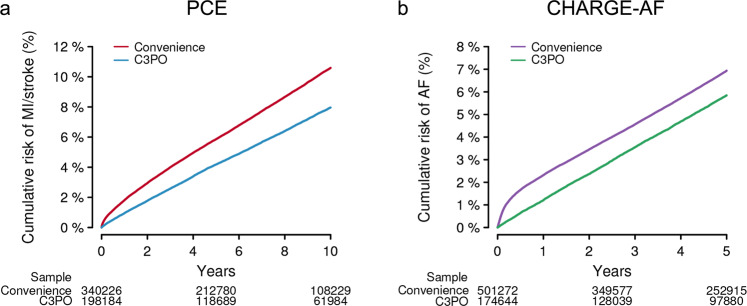
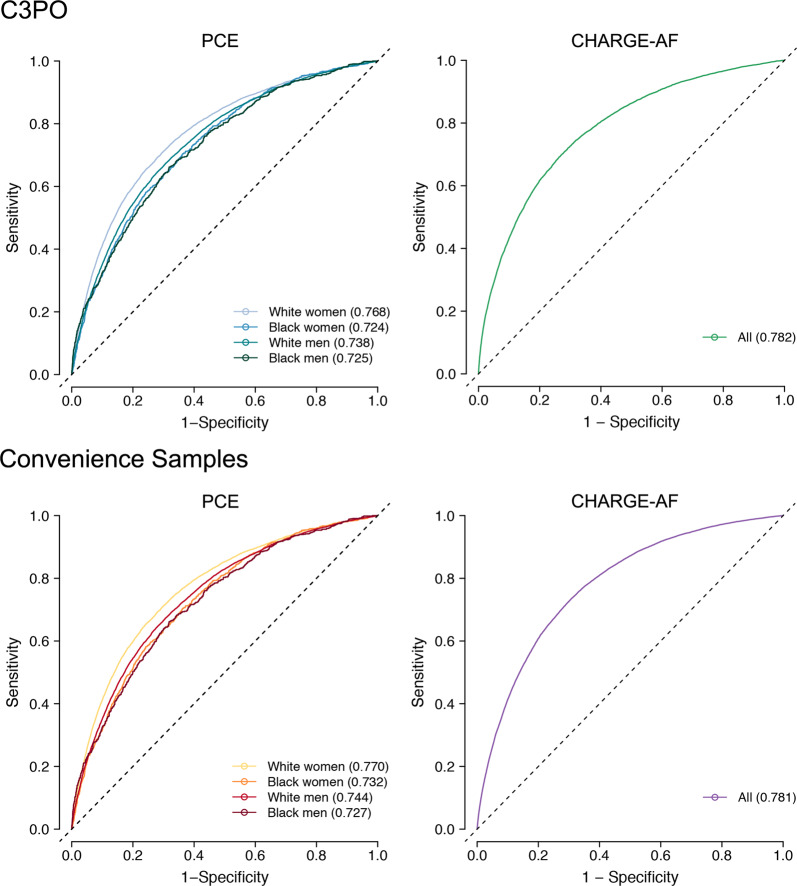
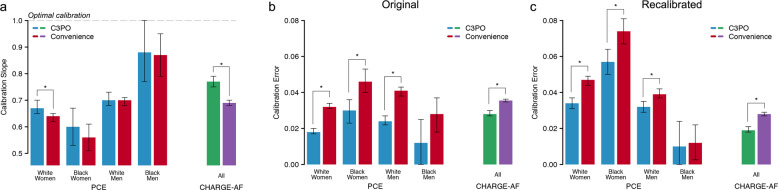
Electronic health record (EHR) datasets are statistically powerful but are subject to ascertainment bias and missingness. Using the Mass General Brigham multi-institutional EHR, we approximated a community-based cohort by sampling patients receiving longitudinal primary care between 2001-2018 (Community Care Cohort Project [C3PO], n = 520,868). We utilized natural language processing (NLP) to recover vital signs from unstructured notes. We assessed the validity of C3PO by deploying established risk models for myocardial infarction/stroke and atrial fibrillation. We then compared C3PO to Convenience Samples including all individuals from the same EHR with complete data, but without a longitudinal primary care requirement. NLP reduced the missingness of vital signs by 31%. NLP-recovered vital signs were highly correlated with values derived from structured fields (Pearson r range 0.95-0.99). Atrial fibrillation and myocardial infarction/stroke incidence were lower and risk models were better calibrated in C3PO as opposed to the Convenience Samples (calibration error range for myocardial infarction/stroke: 0.012-0.030 in C3PO vs. 0.028-0.046 in Convenience Samples; calibration error for atrial fibrillation 0.028 in C3PO vs. 0.036 in Convenience Samples). Sampling patients receiving regular primary care and using NLP to recover missing data may reduce bias and maximize generalizability of EHR research.
电子健康记录(EHR)数据集具有强大的统计功能,但存在确诊偏倚和数据缺失问题。利用麻省总医院布莱根分院的多机构电子健康记录,我们通过对2001年至2018年间接受纵向初级保健的患者进行抽样,近似得到了一个基于社区的队列(社区护理队列项目 [C3PO],n = 520,868)。我们利用自然语言处理(NLP)从非结构化记录中恢复生命体征。我们通过部署已建立的心肌梗死/中风和心房颤动风险模型来评估C3PO的有效性。然后,我们将C3PO与便利样本进行比较,便利样本包括来自同一电子健康记录的所有具有完整数据但无纵向初级保健要求的个体。自然语言处理将生命体征的缺失率降低了31%。通过自然语言处理恢复的生命体征与从结构化字段得出的值高度相关(皮尔逊r范围为0.95 - 0.99)。与便利样本相比,C3PO中的心房颤动和心肌梗死/中风发病率较低,风险模型校准效果更好(心肌梗死/中风的校准误差范围:C3PO中为0.012 - 0.030,便利样本中为0.028 - 0.046;心房颤动的校准误差,C3PO中为0.028,便利样本中为0.036)。对接受常规初级保健的患者进行抽样并使用自然语言处理来恢复缺失数据,可能会减少偏倚并使电子健康记录研究的可推广性最大化。