School of Computer Science and Technology, Beijing Institute of Technology, Beijing 100081, China.
Sensors (Basel). 2022 Apr 12;22(8):2950. doi: 10.3390/s22082950.
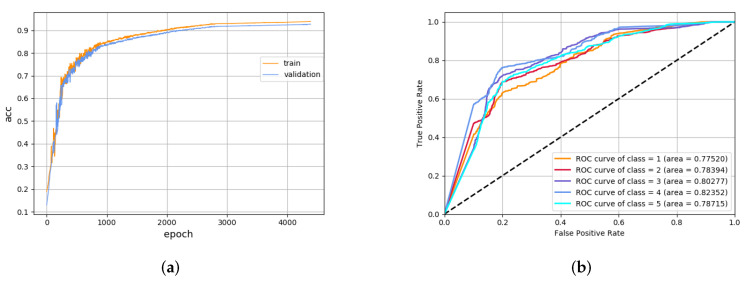
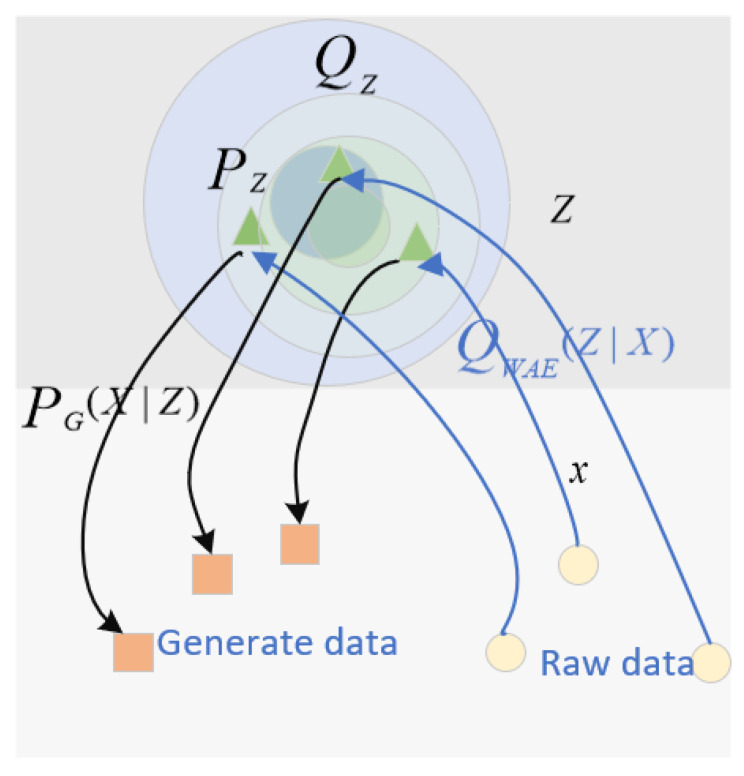
With the exponential growth of data, solving classification or regression tasks by mining time series data has become a research hotspot. Commonly used methods include machine learning, artificial neural networks, and so on. However, these methods only extract the continuous or discrete features of sequences, which have the drawbacks of low information utilization, poor robustness, and computational complexity. To solve these problems, this paper innovatively uses Wasserstein distance instead of Kullback-Leibler divergence and uses it to construct an autoencoder to learn discrete features of time series. Then, a hidden Markov model is used to learn the continuous features of the sequence. Finally, stacking is used to ensemble the two models to obtain the final model. This paper experimentally verifies that the ensemble model has lower computational complexity and is close to state-of-the-art classification accuracy.
随着数据的指数级增长,通过挖掘时间序列数据来解决分类或回归任务已成为研究热点。常用的方法包括机器学习、人工神经网络等。然而,这些方法仅提取序列的连续或离散特征,存在信息利用率低、鲁棒性差和计算复杂度高的缺点。为了解决这些问题,本文创新性地使用 Wasserstein 距离代替 Kullback-Leibler 散度,并使用它构建自动编码器来学习时间序列的离散特征。然后,使用隐马尔可夫模型学习序列的连续特征。最后,使用堆叠将两个模型集成在一起,以获得最终模型。本文通过实验验证了集成模型具有较低的计算复杂度,并接近最新的分类精度。