Collaborative Innovation Center of Henan Grain Crops, Henan Agricultural University, Zhengzhou 450046, China.
Center for Crop Genome Engineering, Henan Agricultural University, Zhengzhou 450046, China.
Nucleic Acids Res. 2022 Jul 5;50(W1):W434-W447. doi: 10.1093/nar/gkac351.
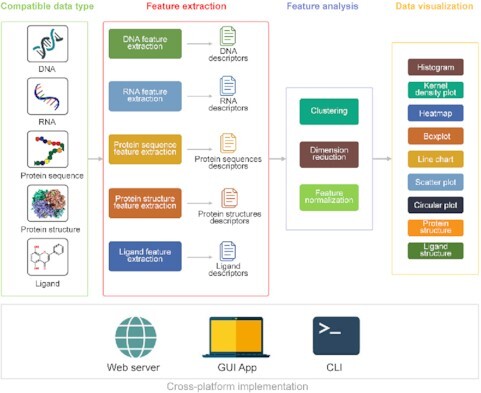
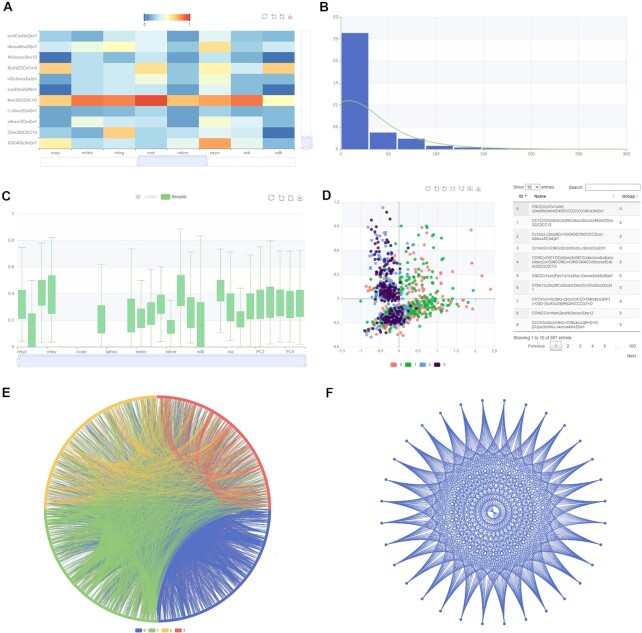
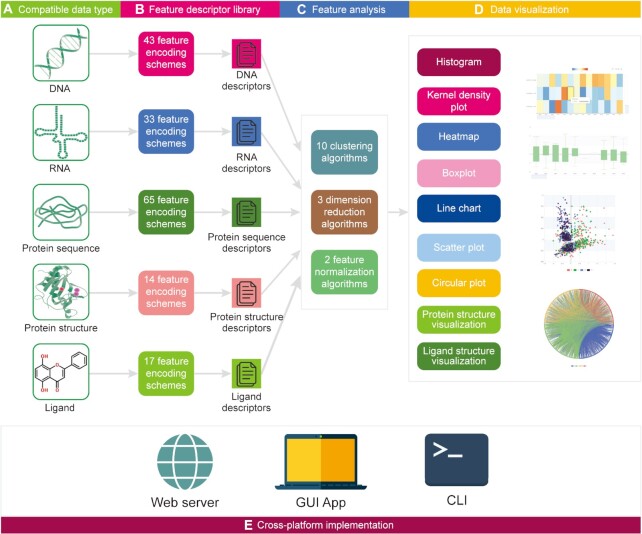
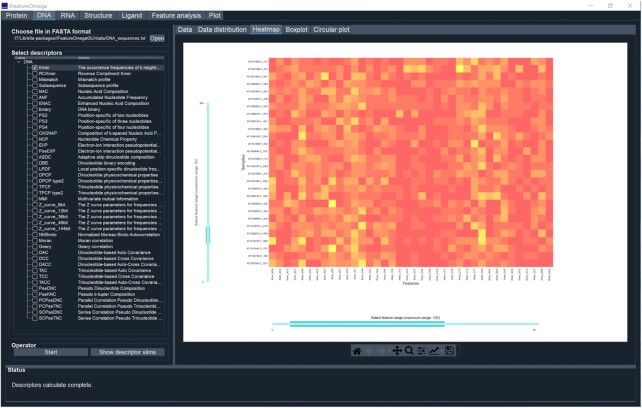
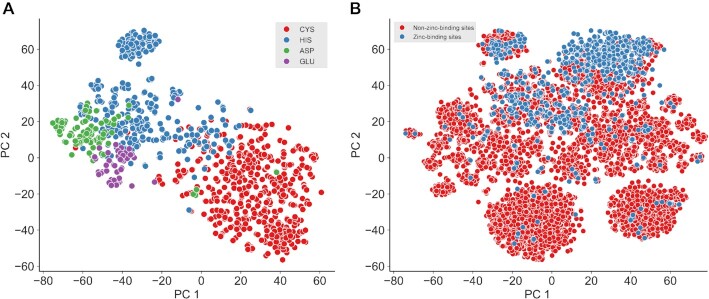
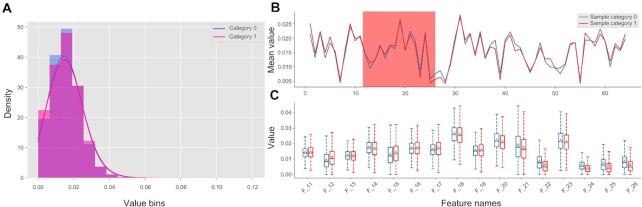
The rapid accumulation of molecular data motivates development of innovative approaches to computationally characterize sequences, structures and functions of biological and chemical molecules in an efficient, accessible and accurate manner. Notwithstanding several computational tools that characterize protein or nucleic acids data, there are no one-stop computational toolkits that comprehensively characterize a wide range of biomolecules. We address this vital need by developing a holistic platform that generates features from sequence and structural data for a diverse collection of molecule types. Our freely available and easy-to-use iFeatureOmega platform generates, analyzes and visualizes 189 representations for biological sequences, structures and ligands. To the best of our knowledge, iFeatureOmega provides the largest scope when directly compared to the current solutions, in terms of the number of feature extraction and analysis approaches and coverage of different molecules. We release three versions of iFeatureOmega including a webserver, command line interface and graphical interface to satisfy needs of experienced bioinformaticians and less computer-savvy biologists and biochemists. With the assistance of iFeatureOmega, users can encode their molecular data into representations that facilitate construction of predictive models and analytical studies. We highlight benefits of iFeatureOmega based on three research applications, demonstrating how it can be used to accelerate and streamline research in bioinformatics, computational biology, and cheminformatics areas. The iFeatureOmega webserver is freely available at http://ifeatureomega.erc.monash.edu and the standalone versions can be downloaded from https://github.com/Superzchen/iFeatureOmega-GUI/ and https://github.com/Superzchen/iFeatureOmega-CLI/.
分子数据的快速积累促使人们开发创新方法,以高效、可及和准确的方式计算生物和化学分子的序列、结构和功能。尽管有一些用于描述蛋白质或核酸数据的计算工具,但没有一个综合性的计算工具包可以全面描述广泛的生物分子。我们通过开发一个全面的平台来解决这一关键需求,该平台从序列和结构数据中生成各种分子类型的特征。我们的免费且易于使用的 iFeatureOmega 平台为多种分子类型生成生物序列、结构和配体的 189 种表示形式。据我们所知,在直接比较当前解决方案时,iFeatureOmega 在特征提取和分析方法的数量以及不同分子的覆盖范围方面提供了最大的范围。我们发布了三个版本的 iFeatureOmega,包括一个网络服务器、命令行接口和图形界面,以满足经验丰富的生物信息学家和不太精通计算机的生物学家和生物化学家的需求。有了 iFeatureOmega 的帮助,用户可以将他们的分子数据编码为表示形式,从而方便构建预测模型和分析研究。我们基于三个研究应用突出了 iFeatureOmega 的优势,展示了如何将其用于加速和简化生物信息学、计算生物学和化学信息学领域的研究。iFeatureOmega 网络服务器可免费在 http://ifeatureomega.erc.monash.edu 上使用,独立版本可从 https://github.com/Superzchen/iFeatureOmega-GUI/ 和 https://github.com/Superzchen/iFeatureOmega-CLI/ 下载。