Rehabilitation and Prevention Center, Heart Vascular Stroke Institute, Samsung Medical Center, Sungkyunkwan University School of Medicine, Seoul, Korea.
Department of Biomedical Engineering, Seoul National University College of Medicine, Seoul, Korea.
J Korean Med Sci. 2022 May 9;37(18):e144. doi: 10.3346/jkms.2022.37.e144.
There are limited data on the accuracy of cloud-based speech recognition (SR) open application programming interfaces (APIs) for medical terminology. This study aimed to evaluate the medical term recognition accuracy of current available cloud-based SR open APIs in Korean.
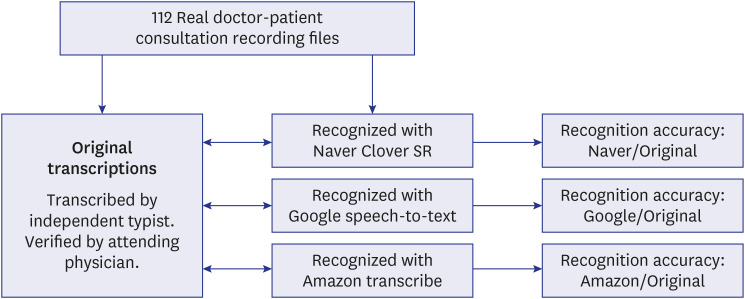
We analyzed the SR accuracy of currently available cloud-based SR open APIs using real doctor-patient conversation recordings collected from an outpatient clinic at a large tertiary medical center in Korea. For each original and SR transcription, we analyzed the accuracy rate of each cloud-based SR open API (i.e., the number of medical terms in the SR transcription per number of medical terms in the original transcription).
A total of 112 doctor-patient conversation recordings were converted with three cloud-based SR open APIs (Naver Clova SR from Naver Corporation; Google Speech-to-Text from Alphabet Inc.; and Amazon Transcribe from Amazon), and each transcription was compared. Naver Clova SR (75.1%) showed the highest accuracy with the recognition of medical terms compared to the other open APIs (Google Speech-to-Text, 50.9%, < 0.001; Amazon Transcribe, 57.9%, < 0.001), and Amazon Transcribe demonstrated higher recognition accuracy compared to Google Speech-to-Text ( < 0.001). In the sub-analysis, Naver Clova SR showed the highest accuracy in all areas according to word classes, but the accuracy of words longer than five characters showed no statistical differences (Naver Clova SR, 52.6%; Google Speech-to-Text, 56.3%; Amazon Transcribe, 36.6%).
Among three current cloud-based SR open APIs, Naver Clova SR which manufactured by Korean company showed highest accuracy of medical terms in Korean, compared to Google Speech-to-Text and Amazon Transcribe. Although limitations are existing in the recognition of medical terminology, there is a lot of rooms for improvement of this promising technology by combining strengths of each SR engines.
目前关于云语音识别(SR)开放应用程序接口(API)在医学术语方面的准确性数据有限。本研究旨在评估当前可用的基于云的 SR 开放 API 在韩语中的医学术语识别准确性。
我们使用从韩国一家大型三级医疗中心的门诊收集的真实医患对话记录,分析了当前可用的基于云的 SR 开放 API 的 SR 准确性。对于每个原始和 SR 转录本,我们分析了每个基于云的 SR 开放 API 的准确率(即,SR 转录本中的医学术语数量与原始转录本中的医学术语数量之比)。
共有 112 份医患对话记录通过三个基于云的 SR 开放 API(Naver Corporation 的 Naver Clova SR;Alphabet Inc. 的 Google Speech-to-Text;以及 Amazon 的 Amazon Transcribe)进行了转换,并且比较了每个转录本。与其他开放 API 相比,Naver Clova SR(75.1%)在医学术语识别方面的准确性最高(Google Speech-to-Text,50.9%,<0.001;Amazon Transcribe,57.9%,<0.001),并且 Amazon Transcribe 比 Google Speech-to-Text 的识别准确率更高(<0.001)。在亚组分析中,Naver Clova SR 在所有词类中均表现出最高的准确性,但五个字符以上的单词准确性没有统计学差异(Naver Clova SR,52.6%;Google Speech-to-Text,56.3%;Amazon Transcribe,36.6%)。
在三种当前的基于云的 SR 开放 API 中,韩国公司制造的 Naver Clova SR 在韩语中的医学术语识别准确性最高,其次是 Google Speech-to-Text 和 Amazon Transcribe。尽管在医学术语识别方面存在局限性,但通过结合每个 SR 引擎的优势,这项很有前途的技术仍有很大的改进空间。