Safdar Sadia, Rizwan Muhammad, Gadekallu Thippa Reddy, Javed Abdul Rehman, Rahmani Mohammad Khalid Imam, Jawad Khurram, Bhatia Surbhi
Department of Computer Science, Kinnaird College for Women, Lahore 44000, Pakistan.
School of Information Technology and Engineering, Vellore Institute of Technology, Vellore 632014, India.
Diagnostics (Basel). 2022 May 3;12(5):1134. doi: 10.3390/diagnostics12051134.
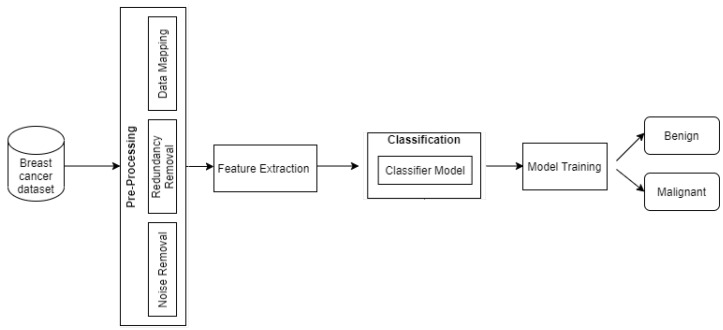
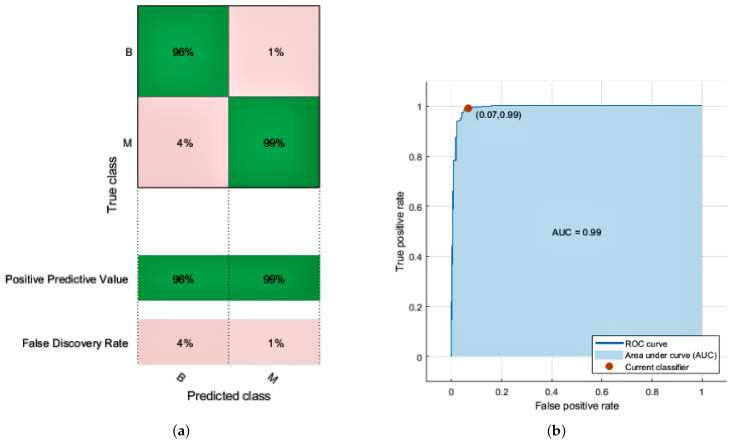
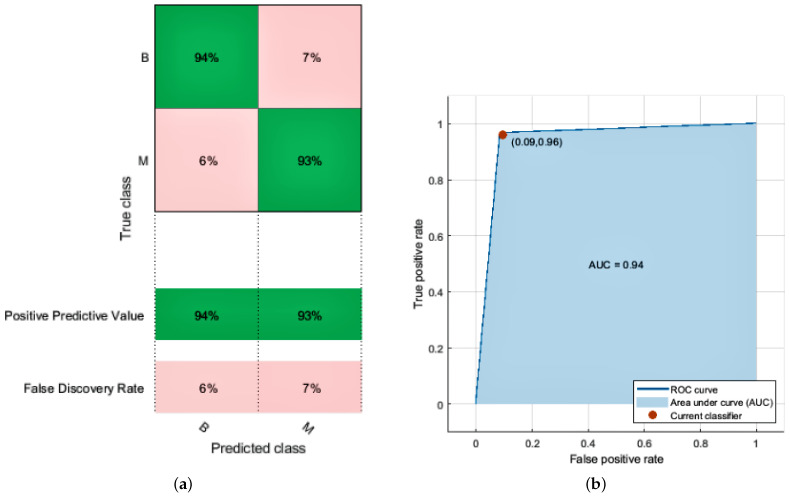
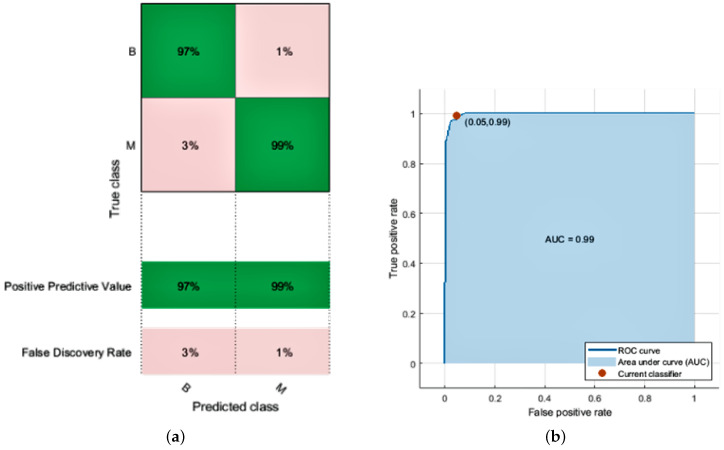
Breast cancer is one of the most widespread diseases in women worldwide. It leads to the second-largest mortality rate in women, especially in European countries. It occurs when malignant lumps that are cancerous start to grow in the breast cells. Accurate and early diagnosis can help in increasing survival rates against this disease. A computer-aided detection (CAD) system is necessary for radiologists to differentiate between normal and abnormal cell growth. This research consists of two parts; the first part involves a brief overview of the different image modalities, using a wide range of research databases to source information such as ultrasound, histography, and mammography to access various publications. The second part evaluates different machine learning techniques used to estimate breast cancer recurrence rates. The first step is to perform preprocessing, including eliminating missing values, data noise, and transformation. The dataset is divided as follows: 60% of the dataset is used for training, and the rest, 40%, is used for testing. We focus on minimizing type one false-positive rate (FPR) and type two false-negative rate (FNR) errors to improve accuracy and sensitivity. Our proposed model uses machine learning techniques such as support vector machine (SVM), logistic regression (LR), and K-nearest neighbor (KNN) to achieve better accuracy in breast cancer classification. Furthermore, we attain the highest accuracy of 97.7% with 0.01 FPR, 0.03 FNR, and an area under the ROC curve (AUC) score of 0.99. The results show that our proposed model successfully classifies breast tumors while overcoming previous research limitations. Finally, we summarize the paper with the future trends and challenges of the classification and segmentation in breast cancer detection.
乳腺癌是全球女性中最普遍的疾病之一。它导致女性中第二高的死亡率,尤其是在欧洲国家。当乳腺细胞中开始生长出癌变的恶性肿块时,乳腺癌就会发生。准确的早期诊断有助于提高对抗这种疾病的生存率。计算机辅助检测(CAD)系统对于放射科医生区分正常和异常细胞生长是必要的。本研究包括两个部分;第一部分简要概述了不同的图像模态,使用广泛的研究数据库来获取信息,如超声、组织学和乳腺X线摄影,以查阅各种出版物。第二部分评估用于估计乳腺癌复发率的不同机器学习技术。第一步是进行预处理,包括消除缺失值、数据噪声和变换。数据集的划分如下:60%的数据集用于训练,其余40%用于测试。我们专注于最小化一类假阳性率(FPR)和二类假阴性率(FNR)误差,以提高准确性和敏感性。我们提出的模型使用支持向量机(SVM)、逻辑回归(LR)和K近邻(KNN)等机器学习技术,在乳腺癌分类中实现更好的准确性。此外,我们以0.01的FPR、0.03的FNR和0.99的ROC曲线下面积(AUC)得分达到了97.7%的最高准确率。结果表明,我们提出的模型成功地对乳腺肿瘤进行了分类,同时克服了先前研究的局限性。最后,我们总结了本文关于乳腺癌检测中分类和分割的未来趋势及挑战。