Department of Computer Science, University of Pretoria, Pretoria, South Africa.
AstraZeneca, London, United Kingdom.
PLoS One. 2022 Jun 9;17(6):e0267714. doi: 10.1371/journal.pone.0267714. eCollection 2022.
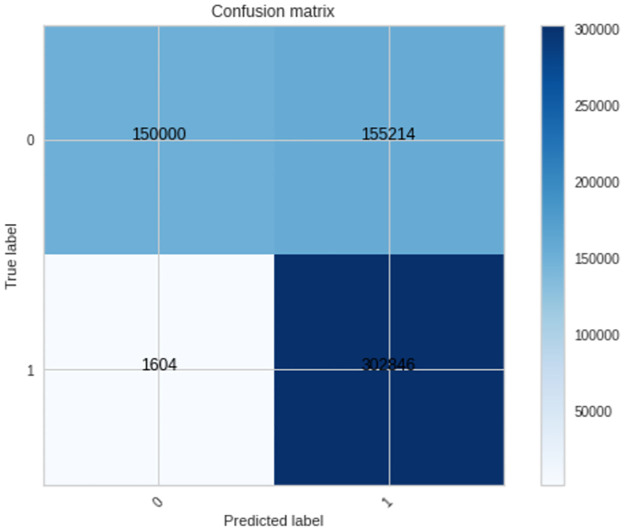
One of the most precise methods to detect prostate cancer is by evaluation of a stained biopsy by a pathologist under a microscope. Regions of the tissue are assessed and graded according to the observed histological pattern. However, this is not only laborious, but also relies on the experience of the pathologist and tends to suffer from the lack of reproducibility of biopsy outcomes across pathologists. As a result, computational approaches are being sought and machine learning has been gaining momentum in the prediction of the Gleason grade group. To date, machine learning literature has addressed this problem by using features from magnetic resonance imaging images, whole slide images, tissue microarrays, gene expression data, and clinical features. However, there is a gap with regards to predicting the Gleason grade group using DNA sequences as the only input source to the machine learning models. In this work, using whole genome sequence data from South African prostate cancer patients, an application of machine learning and biological experiments were combined to understand the challenges that are associated with the prediction of the Gleason grade group. A series of machine learning binary classifiers (XGBoost, LSTM, GRU, LR, RF) were created only relying on DNA sequences input features. All the models were not able to adequately discriminate between the DNA sequences of the studied Gleason grade groups (Gleason grade group 1 and 5). However, the models were further evaluated in the prediction of tumor DNA sequences from matched-normal DNA sequences, given DNA sequences as the only input source. In this new problem, the models performed acceptably better than before with the XGBoost model achieving the highest accuracy of 74 ± 01, F1 score of 79 ± 01, recall of 99 ± 0.0, and precision of 66 ± 0.1.
检测前列腺癌最精确的方法之一是通过病理学家在显微镜下评估染色活检。根据观察到的组织学模式评估和分级组织区域。然而,这不仅费力,而且还依赖于病理学家的经验,并且往往容易受到不同病理学家之间活检结果缺乏可重复性的影响。因此,人们正在寻求计算方法,机器学习在预测格里森等级组方面也越来越受到关注。迄今为止,机器学习文献已经通过使用磁共振成像图像、全幻灯片图像、组织微阵列、基因表达数据和临床特征的特征来解决这个问题。然而,在使用 DNA 序列作为机器学习模型的唯一输入源来预测格里森等级组方面,仍然存在差距。在这项工作中,使用南非前列腺癌患者的全基因组序列数据,将机器学习和生物实验相结合,以了解与预测格里森等级组相关的挑战。仅依赖于 DNA 序列输入特征,创建了一系列机器学习二进制分类器(XGBoost、LSTM、GRU、LR、RF)。所有模型都不能充分区分研究的格里森等级组(格里森等级组 1 和 5)的 DNA 序列。然而,在仅使用 DNA 序列作为输入源的情况下,进一步评估了这些模型在预测肿瘤 DNA 序列与匹配正常 DNA 序列之间的性能。在这个新问题中,与之前相比,这些模型的表现要好得多,其中 XGBoost 模型的准确率最高,为 74±0.1,F1 得分为 79±0.1,召回率为 99±0.0,精度为 66±0.1。