Geneseeq Research Institute, Nanjing Geneseeq Technology Inc., Nanjing, 210000, Jiangsu, China.
Department of Liver Surgery and Transplantation, Liver Cancer Institute, Zhongshan Hospital, Fudan University, Shanghai, 200032, China.
Mol Cancer. 2022 Jun 11;21(1):129. doi: 10.1186/s12943-022-01594-w.
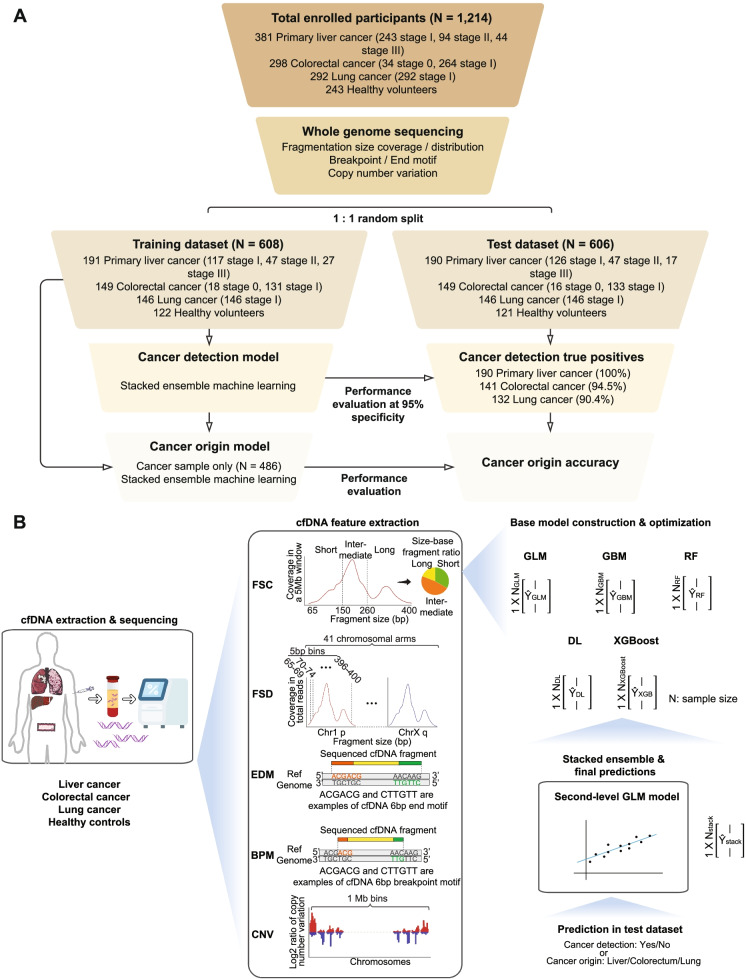
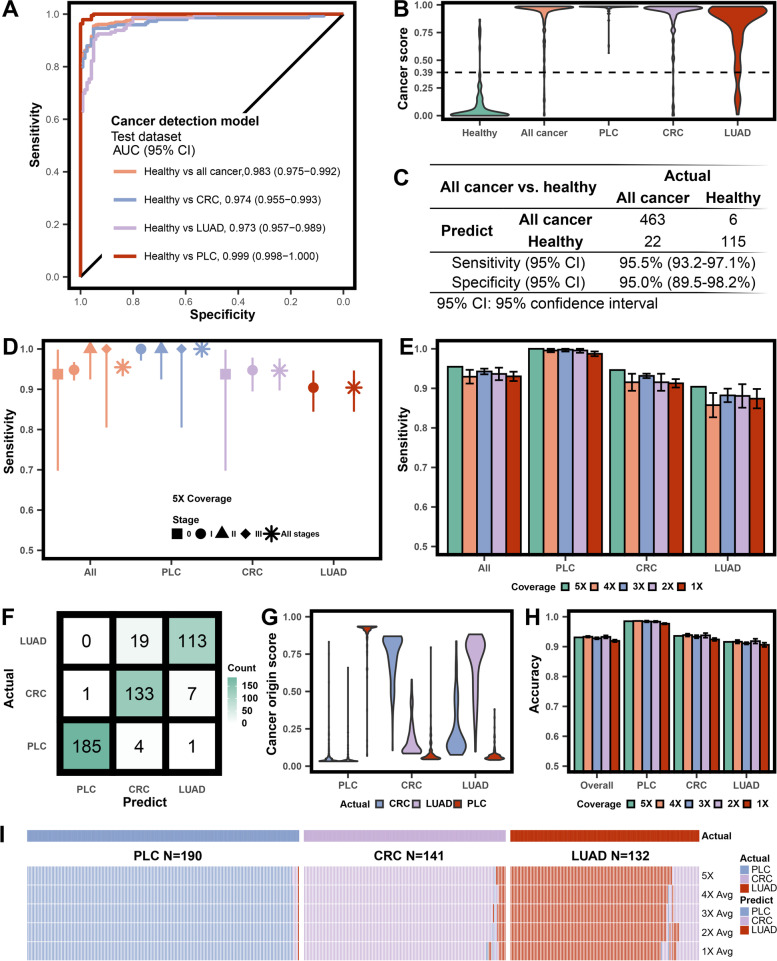
Early detection can benefit cancer patients with more effective treatments and better prognosis, but existing early screening tests are limited, especially for multi-cancer detection. This study investigated the most prevalent and lethal cancer types, including primary liver cancer (PLC), colorectal adenocarcinoma (CRC), and lung adenocarcinoma (LUAD). Leveraging the emerging cell-free DNA (cfDNA) fragmentomics, we developed a robust machine learning model for multi-cancer early detection. 1,214 participants, including 381 PLC, 298 CRC, 292 LUAD patients, and 243 healthy volunteers, were enrolled. The majority of patients (N = 971) were at early stages (stage 0, N = 34; stage I, N = 799). The participants were randomly divided into a training cohort and a test cohort in a 1:1 ratio while maintaining the ratio for the major histology subtypes. An ensemble stacked machine learning approach was developed using multiple plasma cfDNA fragmentomic features. The model was trained solely in the training cohort and then evaluated in the test cohort. Our model showed an Area Under the Curve (AUC) of 0.983 for differentiating cancer patients from healthy individuals. At 95.0% specificity, the sensitivity of detecting all cancer reached 95.5%, while 100%, 94.6%, and 90.4% for PLC, CRC, and LUAD, individually. The cancer origin model demonstrated an overall 93.1% accuracy for predicting cancer origin in the test cohort (97.4%, 94.3%, and 85.6% for PLC, CRC, and LUAD, respectively). Our model sensitivity is consistently high for early-stage and small-size tumors. Furthermore, its detection and origin classification power remained superior when reducing sequencing depth to 1× (cancer detection: ≥ 91.5% sensitivity at 95.0% specificity; cancer origin: ≥ 91.6% accuracy). In conclusion, we have incorporated plasma cfDNA fragmentomics into the ensemble stacked model and established an ultrasensitive assay for multi-cancer early detection, shedding light on developing cancer early screening in clinical practice.
早期发现可以使癌症患者受益于更有效的治疗和更好的预后,但现有的早期筛查测试有限,特别是对于多种癌症的检测。本研究调查了最常见和最致命的癌症类型,包括原发性肝癌(PLC)、结直肠癌(CRC)和肺腺癌(LUAD)。利用新兴的无细胞游离 DNA(cfDNA)片段组学,我们开发了一种用于多种癌症早期检测的强大机器学习模型。共纳入 1214 名参与者,包括 381 名 PLC 患者、298 名 CRC 患者、292 名 LUAD 患者和 243 名健康志愿者。大多数患者(N=971)处于早期阶段(0 期,N=34;I 期,N=799)。参与者以 1:1 的比例随机分为训练队列和测试队列,同时保持主要组织学亚型的比例。使用多种血浆 cfDNA 片段组学特征开发了集成堆叠机器学习方法。该模型仅在训练队列中进行训练,然后在测试队列中进行评估。我们的模型在区分癌症患者和健康个体方面表现出 0.983 的曲线下面积(AUC)。在特异性为 95.0%时,检测所有癌症的敏感性达到 95.5%,而分别为 100%、94.6%和 90.4%,用于 PLC、CRC 和 LUAD。癌症起源模型在测试队列中对癌症起源的预测总体准确率为 93.1%(分别为 PLC、CRC 和 LUAD 的 97.4%、94.3%和 85.6%)。我们的模型对早期和小肿瘤的敏感性始终很高。此外,当测序深度降低至 1×时,其检测和起源分类能力仍然优越(癌症检测:特异性为 95.0%时,敏感性≥91.5%;癌症起源:准确性≥91.6%)。总之,我们将血浆 cfDNA 片段组学纳入集成堆叠模型,并建立了一种超灵敏的多种癌症早期检测方法,为临床实践中开发癌症早期筛查提供了思路。