Malaria Atlas Project, Big Data Institute, University of Oxford, Oxford, UK.
Malaria Atlas Project, Big Data Institute, University of Oxford, Oxford, UK.
Spat Spatiotemporal Epidemiol. 2022 Jun;41:100357. doi: 10.1016/j.sste.2020.100357. Epub 2020 Jul 4.
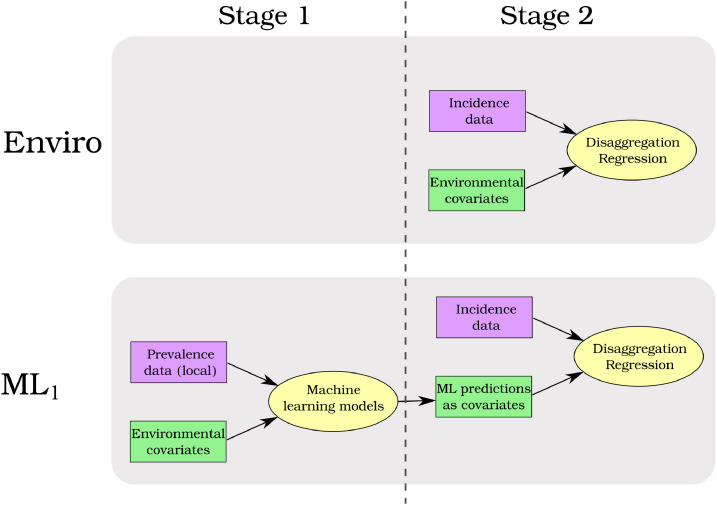
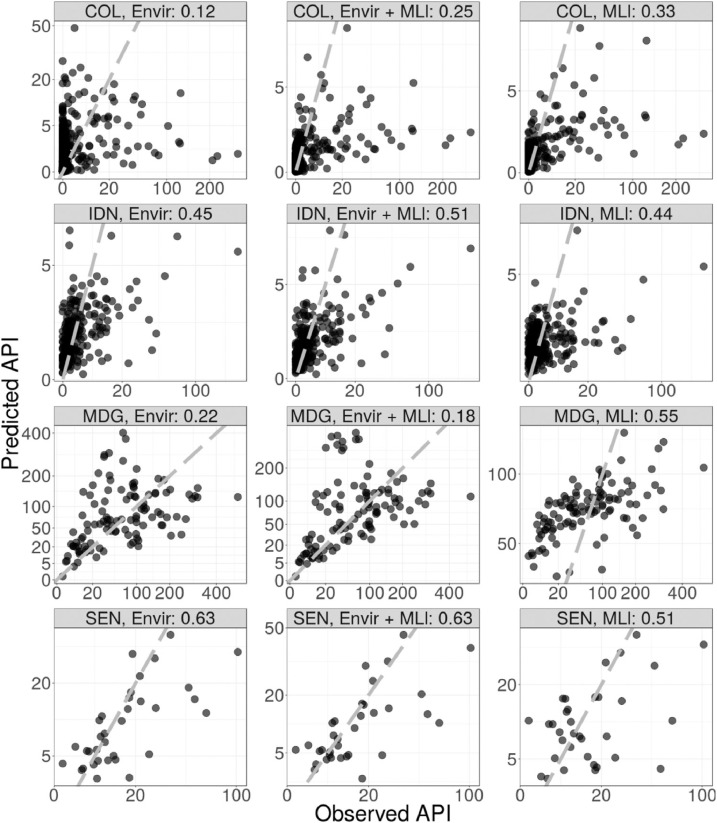
Maps of disease burden are a core tool needed for the control and elimination of malaria. Reliable routine surveillance data of malaria incidence, typically aggregated to administrative units, is becoming more widely available. Disaggregation regression is an important model framework for estimating high resolution risk maps from aggregated data. However, the aggregation of incidence over large, heterogeneous areas means that these data are underpowered for estimating complex, non-linear models. In contrast, prevalence point-surveys are directly linked to local environmental conditions but are not common in many areas of the world. Here, we train multiple non-linear, machine learning models on Plasmodium falciparum prevalence point-surveys. We then ensemble the predictions from these machine learning models with a disaggregation regression model that uses aggregated malaria incidences as response data. We find that using a disaggregation regression model to combine predictions from machine learning models improves model accuracy relative to a baseline model.
疾病负担图是控制和消除疟疾的核心工具。疟疾发病率的可靠常规监测数据(通常汇总到行政单位)越来越普及。离散回归是从聚合数据估计高分辨率风险图的重要模型框架。然而,在大的、异质的区域内对发病率进行汇总意味着这些数据对于估计复杂的非线性模型来说力量不足。相比之下,患病率点调查直接与当地的环境条件相关,但在世界上许多地区并不常见。在这里,我们在疟原虫患病率点调查上训练了多个非线性机器学习模型。然后,我们将这些机器学习模型的预测与一个离散回归模型进行集成,该模型将聚合的疟疾发病率作为响应数据。我们发现,使用离散回归模型来结合机器学习模型的预测可以提高模型的准确性,相对于基线模型而言。