Department of Biological Engineering, Massachusetts Institute of Technology, Cambridge, MA, USA.
Computer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, MA, USA.
Bioinformatics. 2022 Jun 24;38(Suppl 1):i395-i403. doi: 10.1093/bioinformatics/btac263.
Advances in bioimaging now permit in situ proteomic characterization of cell-cell interactions in complex tissues, with important applications across a spectrum of biological problems from development to disease. These methods depend on selection of antibodies targeting proteins that are expressed specifically in particular cell types. Candidate marker proteins are often identified from single-cell transcriptomic data, with variable rates of success, in part due to divergence between expression levels of proteins and the genes that encode them. In principle, marker identification could be improved by using existing databases of immunohistochemistry for thousands of antibodies in human tissue, such as the Human Protein Atlas. However, these data lack detailed annotations of the types of cells in each image.
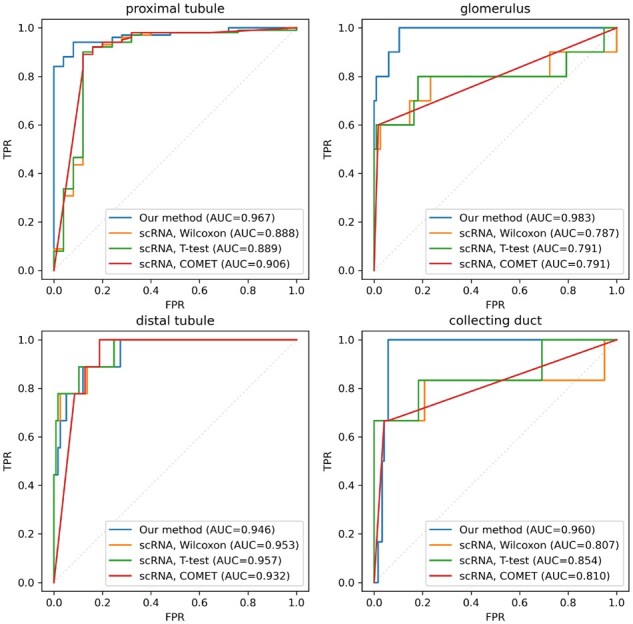
We develop a method to predict cell type specificity of protein markers from unlabeled images. We train a convolutional neural network with a self-supervised objective to generate embeddings of the images. Using non-linear dimensionality reduction, we observe that the model clusters images according to cell types and anatomical regions for which the stained proteins are specific. We then use estimates of cell type specificity derived from an independent single-cell transcriptomics dataset to train an image classifier, without requiring any human labelling of images. Our scheme demonstrates superior classification of known proteomic markers in kidney compared to selection via single-cell transcriptomics.
Code and trained model are available at www.github.com/murphy17/HPA-SimCLR.
Supplementary data are available at Bioinformatics online.
生物成像技术的进步现在允许在复杂组织中对细胞间相互作用进行原位蛋白质组学特征分析,在从发育到疾病的一系列生物学问题中都有重要的应用。这些方法依赖于选择针对特定细胞类型特异性表达的蛋白质的抗体。候选标记蛋白通常是从单细胞转录组数据中识别出来的,成功率不一,部分原因是蛋白质表达水平与编码它们的基因之间存在差异。原则上,通过使用现有的人组织中数千种抗体的免疫组织化学数据库(如人类蛋白质图谱),可以改善标记物的识别。然而,这些数据缺乏对每张图像中细胞类型的详细注释。
我们开发了一种从未标记图像预测蛋白质标记物细胞类型特异性的方法。我们使用自我监督的目标训练卷积神经网络,以生成图像的嵌入。通过非线性降维,我们观察到该模型根据染色蛋白特异性的细胞类型和解剖区域对图像进行聚类。然后,我们使用来自独立的单细胞转录组学数据集的细胞类型特异性估计值来训练图像分类器,而无需对图像进行任何人工标记。与通过单细胞转录组学选择相比,我们的方案在肾脏中对已知蛋白质组学标记物的分类表现出更高的性能。
代码和训练模型可在 www.github.com/murphy17/HPA-SimCLR 上获得。
补充数据可在生物信息学在线获得。