Department of Biostatistics, Epidemiology and Informatics, University of Pennsylvania Perelman School of Medicine, 423 Guardian Drive, Philadelphia, PA, 19104, USA.
Department of Biostatistics, Harvard T.H. Chan School of Public Health, Harvard University, Boston, MA, USA.
Sci Rep. 2022 Jun 30;12(1):11073. doi: 10.1038/s41598-022-14029-9.
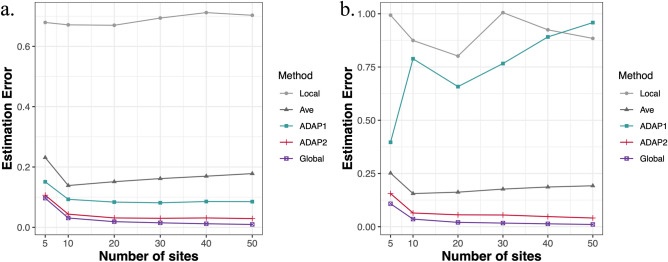
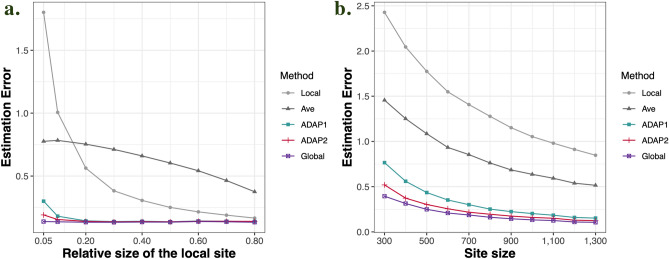
Integrating data across institutions can improve learning efficiency. To integrate data efficiently while protecting privacy, we propose A one-shot, summary-statistics-based, Distributed Algorithm for fitting Penalized (ADAP) regression models across multiple datasets. ADAP utilizes patient-level data from a lead site and incorporates the first-order (ADAP1) and second-order gradients (ADAP2) of the objective function from collaborating sites to construct a surrogate objective function at the lead site, where model fitting is then completed with proper regularizations applied. We evaluate the performance of the proposed method using both simulation and a real-world application to study risk factors for opioid use disorder (OUD) using 15,000 patient data from the OneFlorida Clinical Research Consortium. Our results show that ADAP performs nearly the same as the pooled estimator but achieves higher estimation accuracy and better variable selection than the local and average estimators. Moreover, ADAP2 successfully handles heterogeneity in covariate distributions.
跨机构整合数据可以提高学习效率。为了在保护隐私的同时高效地整合数据,我们提出了一种基于单样本、汇总统计的、适用于跨多个数据集的惩罚(ADAP)回归模型的分布式算法。ADAP 利用来自主导站点的患者水平数据,并结合协作站点的目标函数的一阶(ADAP1)和二阶梯度(ADAP2)来构建主导站点的替代目标函数,然后在适当的正则化应用下完成模型拟合。我们使用模拟和真实应用来评估所提出方法的性能,以使用来自 OneFlorida 临床研究联盟的 15000 名患者数据研究阿片类药物使用障碍(OUD)的风险因素。我们的结果表明,ADAP 的性能几乎与汇总估计器相同,但比本地和平均估计器具有更高的估计准确性和更好的变量选择。此外,ADAP2 成功处理了协变量分布的异质性。