Yu Qiuyan, Ji Wenjie, Prihodko Lara, Ross C Wade, Anchang Julius Y, Hanan Niall P
Plant and Environmental Sciences New Mexico State University Las Cruces New Mexico USA.
Department of Geography California State University Long Beach Long Beach California USA.
Methods Ecol Evol. 2021 Nov;12(11):2117-2128. doi: 10.1111/2041-210X.13686. Epub 2021 Aug 6.
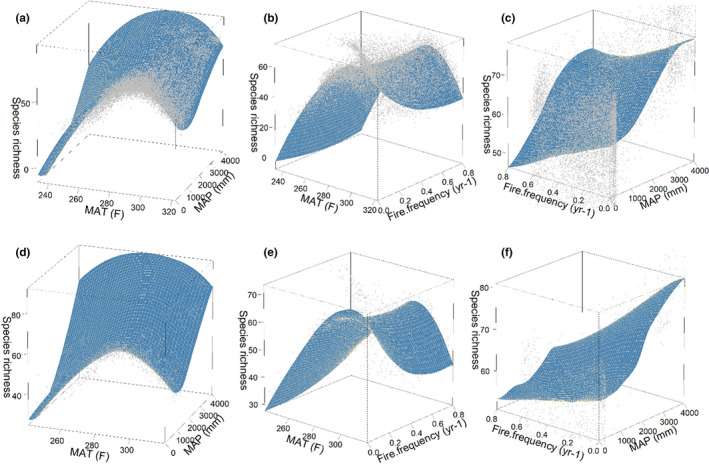
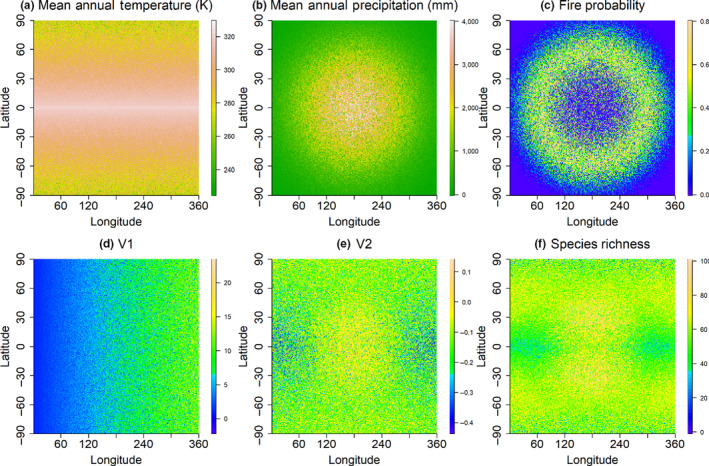
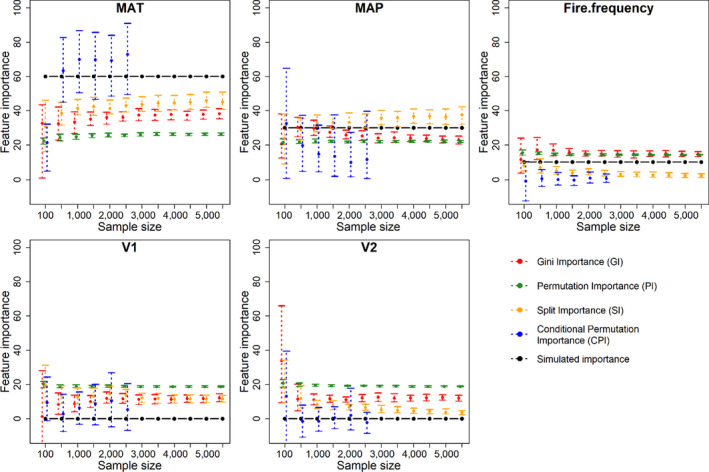
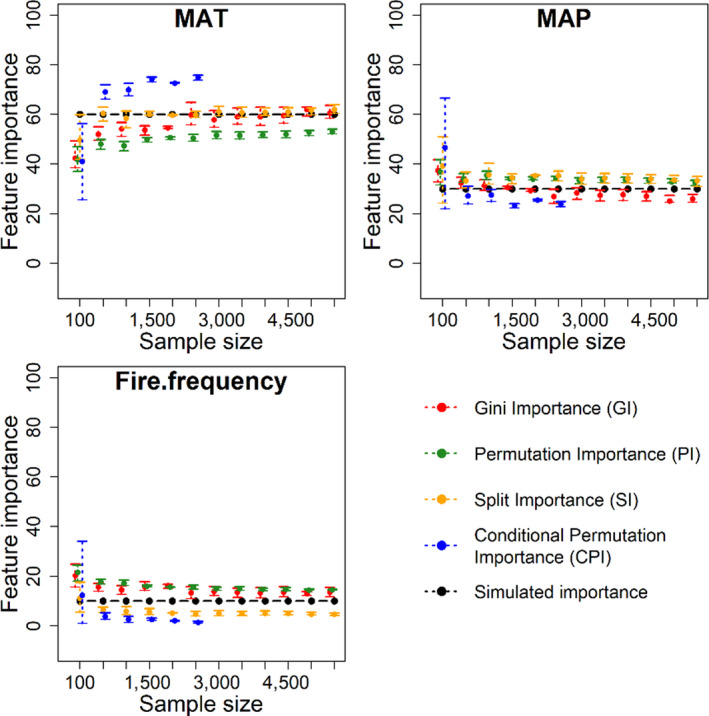
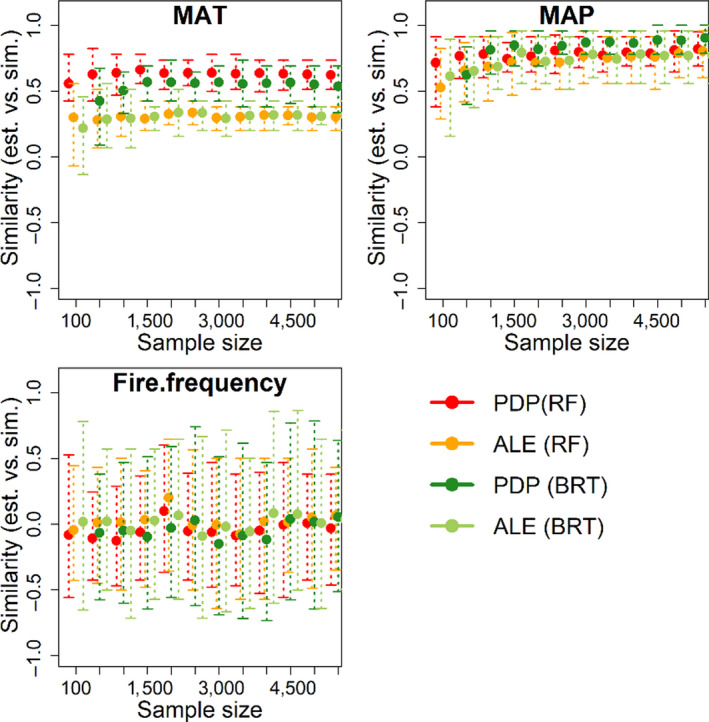
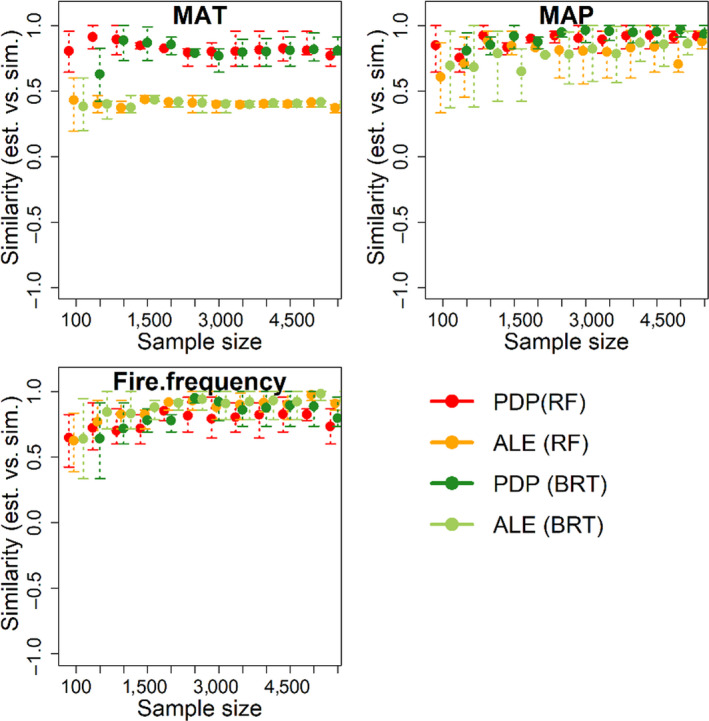
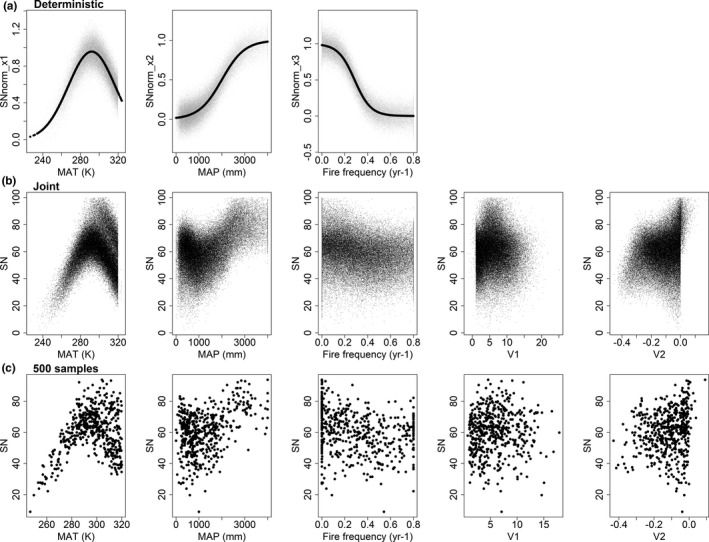
The ecological and environmental science communities have embraced machine learning (ML) for empirical modelling and prediction. However, going beyond prediction to draw insights into underlying functional relationships between response variables and environmental 'drivers' is less straightforward. Deriving ecological insights from fitted ML models requires techniques to extract the 'learning' hidden in the ML models.We revisit the theoretical background and effectiveness of four approaches for deriving insights from ML: ranking independent variable importance (Gini importance, GI; permutation importance, PI; split importance, SI; and conditional permutation importance, CPI), and two approaches for inference of bivariate functional relationships (partial dependence plots, PDP; and accumulated local effect plots, ALE). We also explore the use of a surrogate model for visualization and interpretation of complex multi-variate relationships between response variables and environmental drivers. We examine the challenges and opportunities for extracting ecological insights with these interpretation approaches. Specifically, we aim to improve interpretation of ML models by investigating how effectiveness relates to (a) interpretation algorithm, (b) sample size and (c) the presence of spurious explanatory variables.We base the analysis on simulations with known underlying functional relationships between response and predictor variables, with added white noise and the presence of correlated but non-influential variables. The results indicate that deriving ecological insight is strongly affected by interpretation algorithm and spurious variables, and moderately impacted by sample size. Removing spurious variables improves interpretation of ML models. Meanwhile, increasing sample size has limited value in the presence of spurious variables, but increasing sample size does improves performance once spurious variables are omitted. Among the four ranking methods, SI is slightly more effective than the other methods in the presence of spurious variables, while GI and SI yield higher accuracy when spurious variables are removed. PDP is more effective in retrieving underlying functional relationships than ALE, but its reliability declines sharply in the presence of spurious variables. Visualization and interpretation of the interactive effects of predictors and the response variable can be enhanced using surrogate models, including three-dimensional visualizations and use of loess planes to represent independent variable effects and interactions.Machine learning analysts should be aware that including correlated independent variables in ML models with no clear causal relationship to response variables can interfere with ecological inference. When ecological inference is important, ML models should be constructed with independent variables that have clear causal effects on response variables. While interpreting ML models for ecological inference remains challenging, we show that careful choice of interpretation methods, exclusion of spurious variables and adequate sample size can provide more and better opportunities to 'learn from machine learning'.
生态与环境科学界已采用机器学习(ML)进行实证建模和预测。然而,要超越预测去深入了解响应变量与环境“驱动因素”之间潜在的功能关系并非易事。从拟合的ML模型中得出生态见解需要运用技术来提取隐藏在ML模型中的“学习成果”。我们重新审视了从ML中得出见解的四种方法的理论背景和有效性:对自变量重要性进行排序(基尼重要性,GI;排列重要性,PI;分裂重要性,SI;以及条件排列重要性,CPI),以及两种用于推断双变量功能关系的方法(部分依赖图,PDP;以及累积局部效应图,ALE)。我们还探讨了使用替代模型来可视化和解释响应变量与环境驱动因素之间复杂的多变量关系。我们研究了使用这些解释方法提取生态见解所面临的挑战和机遇。具体而言,我们旨在通过研究有效性如何与(a)解释算法、(b)样本量以及(c)虚假解释变量的存在相关,来改进对ML模型的解释。我们的分析基于对响应变量和预测变量之间已知潜在功能关系的模拟,加入了白噪声以及相关但无影响的变量。结果表明,得出生态见解受到解释算法和虚假变量的强烈影响,样本量的影响程度适中。去除虚假变量可改善对ML模型的解释。同时,在存在虚假变量的情况下增加样本量的价值有限,但一旦省略虚假变量,增加样本量确实会提高性能。在四种排序方法中,在存在虚假变量的情况下,SI比其他方法略有效,而去除虚假变量时,GI和SI的准确性更高。PDP在检索潜在功能关系方面比ALE更有效,但在存在虚假变量时其可靠性会急剧下降。使用替代模型(包括三维可视化以及使用局部加权回归平面来表示自变量效应和相互作用)可以增强对预测变量与响应变量交互效应的可视化和解释。机器学习分析师应意识到,在与响应变量没有明确因果关系的ML模型中纳入相关自变量会干扰生态推断。当生态推断很重要时,ML模型应使用对响应变量有明确因果效应的自变量来构建。虽然为生态推断解释ML模型仍然具有挑战性,但我们表明,仔细选择解释方法、排除虚假变量以及足够的样本量可以提供更多更好的机会来“从机器学习中学习”。