University of the West of England, Department of Social Sciences, Bristol, UK.
Aston University, School of Psychology, College of Health & Life Sciences, Birmingham, UK.
J Vis. 2022 Jul 11;22(8):18. doi: 10.1167/jov.22.8.18.
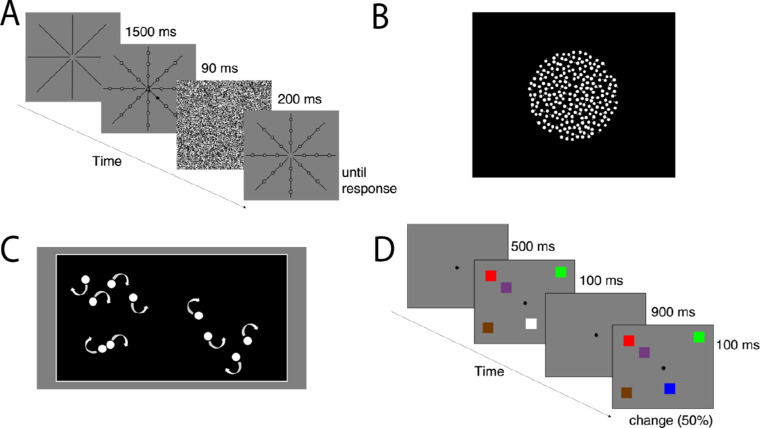
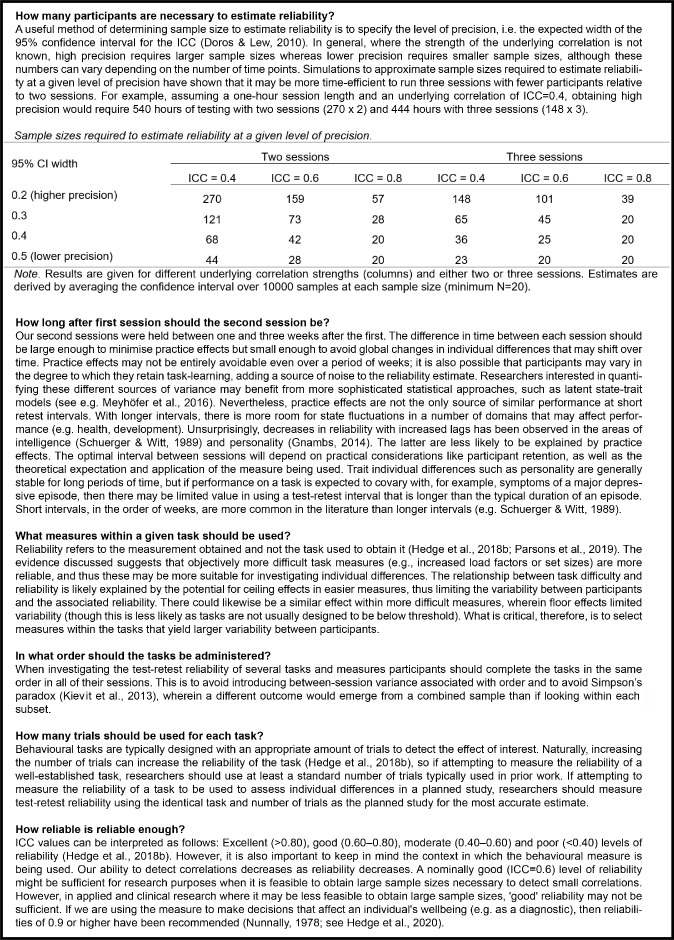
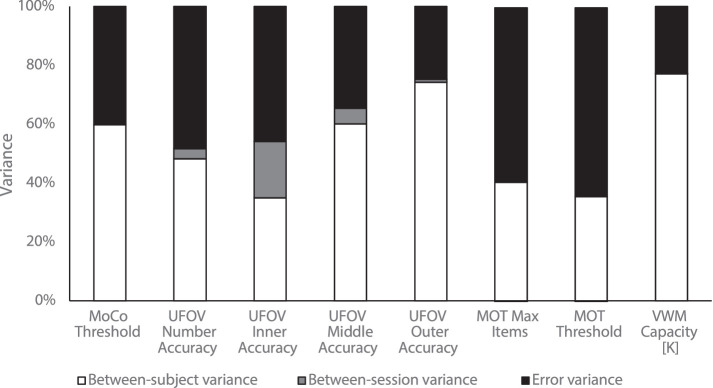
Research in perception and attention has typically sought to evaluate cognitive mechanisms according to the average response to a manipulation. Recently, there has been a shift toward appreciating the value of individual differences and the insight gained by exploring the impacts of between-participant variation on human cognition. However, a recent study suggests that many robust, well-established cognitive control tasks suffer from surprisingly low levels of test-retest reliability (Hedge, Powell, & Sumner, 2018b). We tested a large sample of undergraduate students (n = 160) in two sessions (separated by 1-3 weeks) on four commonly used tasks in vision science. We implemented measures that spanned a range of perceptual and attentional processes, including motion coherence (MoCo), useful field of view (UFOV), multiple-object tracking (MOT), and visual working memory (VWM). Intraclass correlations ranged from good to poor, suggesting that some task measures are more suitable for assessing individual differences than others. VWM capacity (intraclass correlation coefficient [ICC] = 0.77), MoCo threshold (ICC = 0.60), UFOV middle accuracy (ICC = 0.60), and UFOV outer accuracy (ICC = 0.74) showed good-to-excellent reliability. Other measures, namely the maximum number of items tracked in MOT (ICC = 0.41) and UFOV number accuracy (ICC = 0.48), showed moderate reliability; the MOT threshold (ICC = 0.36) and UFOV inner accuracy (ICC = 0.30) showed poor reliability. In this paper, we present these results alongside a summary of reliabilities estimated previously for other vision science tasks. We then offer useful recommendations for evaluating test-retest reliability when considering a task for use in evaluating individual differences.
研究感知和注意力通常试图根据对操作的平均反应来评估认知机制。最近,人们越来越重视个体差异的价值,并通过探索参与者之间的变化对人类认知的影响来获得洞察力。然而,最近的一项研究表明,许多强大的、成熟的认知控制任务的测试-重测信度(test-retest reliability)都出人意料地低(Hedge、Powell 和 Sumner,2018b)。我们在两个(间隔 1-3 周)会话中对 160 名大学生进行了四项常用视觉科学任务的测试。我们实施了一系列跨越感知和注意力过程的措施,包括运动连贯性(MoCo)、有效视野(UFOV)、多目标跟踪(MOT)和视觉工作记忆(VWM)。组内相关系数范围从好到差,这表明一些任务测量更适合评估个体差异。VWM 容量(组内相关系数 [ICC] = 0.77)、MoCo 阈值(ICC = 0.60)、UFOV 中间准确性(ICC = 0.60)和 UFOV 外部准确性(ICC = 0.74)显示出良好到优秀的可靠性。其他措施,即 MOT 中跟踪的最大项目数(ICC = 0.41)和 UFOV 数字准确性(ICC = 0.48)显示出中等可靠性;MOT 阈值(ICC = 0.36)和 UFOV 内部准确性(ICC = 0.30)显示出较差的可靠性。在本文中,我们提供了这些结果,并总结了以前为其他视觉科学任务估计的可靠性。然后,我们在考虑将任务用于评估个体差异时,提供了评估测试-重测可靠性的有用建议。