School of Nursing & Health Studies, University of Washington Bothell, Bothell, Washington, United States of America.
The Department of Electrical and Computer Engineering, Automation and Systems Research Institute, Seoul National University, Seoul, Korea.
PLoS One. 2022 Jul 29;17(7):e0272330. doi: 10.1371/journal.pone.0272330. eCollection 2022.
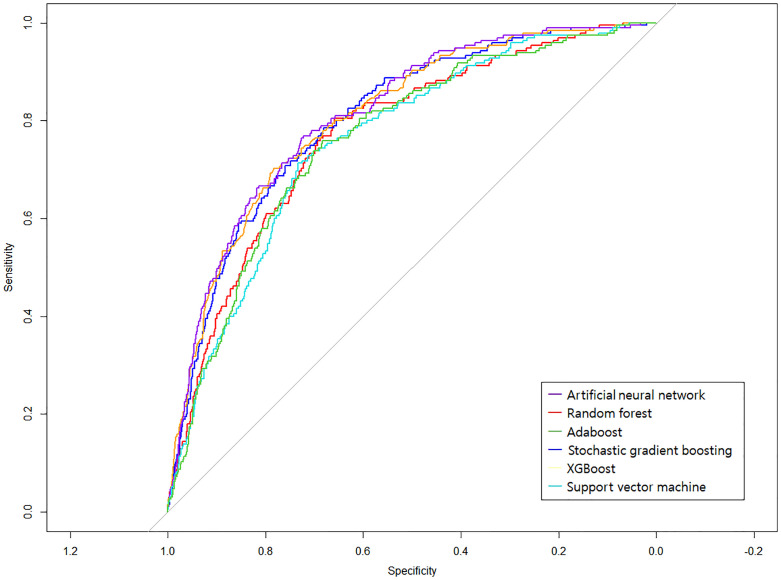
We aimed to develop prediction models for depression among U.S. adults with hypertension using various machine learning (ML) approaches. Moreover, we analyzed the mechanisms of the developed models. This cross-sectional study included 8,628 adults with hypertension (11.3% with depression) from the National Health and Nutrition Examination Survey (2011-2020). We selected several significant features using feature selection methods to build the models. Data imbalance was managed with random down-sampling. Six different ML classification methods implemented in the R package caret-artificial neural network, random forest, AdaBoost, stochastic gradient boosting, XGBoost, and support vector machine-were employed with 10-fold cross-validation for predictions. Model performance was assessed by examining the area under the receiver operating characteristic curve (AUC), accuracy, precision, sensitivity, specificity, and F1-score. For an interpretable algorithm, we used the variable importance evaluation function in caret. Of all classification models, artificial neural network trained with selected features (n = 30) achieved the highest AUC (0.813) and specificity (0.780) in predicting depression. Support vector machine predicted depression with the highest accuracy (0.771), precision (0.969), sensitivity (0.774), and F1-score (0.860). The most frequent and important features contributing to the models included the ratio of family income to poverty, triglyceride level, white blood cell count, age, sleep disorder status, the presence of arthritis, hemoglobin level, marital status, and education level. In conclusion, ML algorithms performed comparably in predicting depression among hypertensive populations. Furthermore, the developed models shed light on variables' relative importance, paving the way for further clinical research.
我们旨在使用各种机器学习 (ML) 方法为美国高血压成年人开发抑郁预测模型。此外,我们还分析了所开发模型的机制。这项横断面研究包括来自国家健康和营养检查调查(2011-2020 年)的 8628 名高血压成年人(11.3%患有抑郁症)。我们使用特征选择方法选择了几个重要特征来构建模型。通过随机降采样处理数据不平衡。在 R 包 caret-artificial neural network、random forest、AdaBoost、stochastic gradient boosting、XGBoost 和 support vector machine 中实现了六种不同的 ML 分类方法,并使用 10 倍交叉验证进行预测。通过检查接收器操作特征曲线下的面积 (AUC)、准确性、精度、敏感性、特异性和 F1 分数来评估模型性能。对于可解释的算法,我们在 caret 中使用了变量重要性评估函数。在所有分类模型中,使用所选特征训练的人工神经网络(n=30)在预测抑郁方面的 AUC(0.813)和特异性(0.780)最高。支持向量机预测抑郁的准确性(0.771)、精度(0.969)、敏感性(0.774)和 F1 分数(0.860)最高。对模型贡献最大的最常见和最重要的特征包括家庭收入与贫困的比例、甘油三酯水平、白细胞计数、年龄、睡眠障碍状况、关节炎的存在、血红蛋白水平、婚姻状况和教育水平。总之,ML 算法在预测高血压人群中的抑郁方面表现相当。此外,所开发的模型揭示了变量的相对重要性,为进一步的临床研究铺平了道路。