Institute of Health Informatics, University College London, London, UK.
Health Data Research UK, London, UK.
J Am Med Inform Assoc. 2023 Jan 18;30(2):222-232. doi: 10.1093/jamia/ocac158.
Patient phenotype definitions based on terminologies are required for the computational use of electronic health records. Within UK primary care research databases, such definitions have typically been represented as flat lists of Read terms, but Systematized Nomenclature of Medicine-Clinical Terms (SNOMED CT) (a widely employed international reference terminology) enables the use of relationships between concepts, which could facilitate the phenotyping process. We implemented SNOMED CT-based phenotyping approaches and investigated their performance in the CPRD Aurum primary care database.
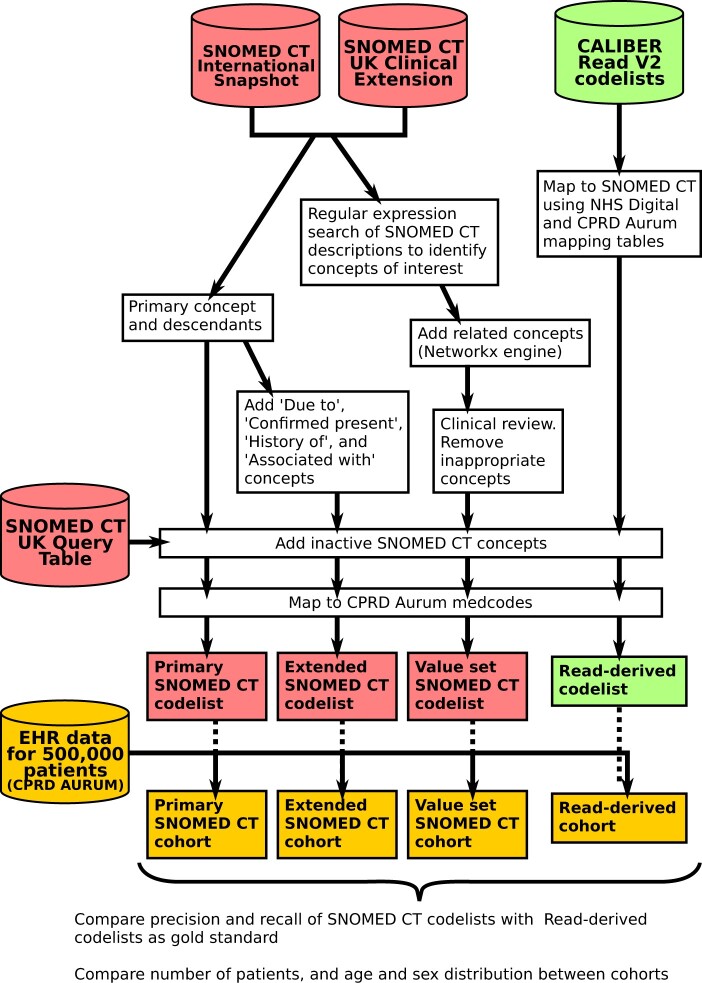
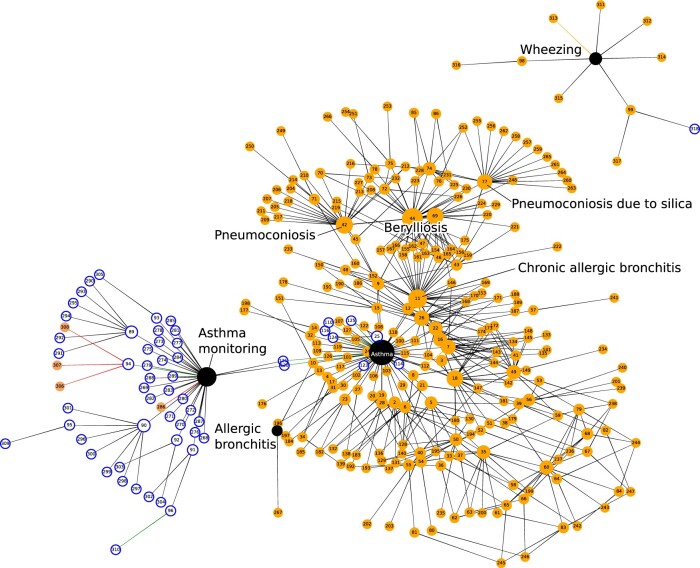
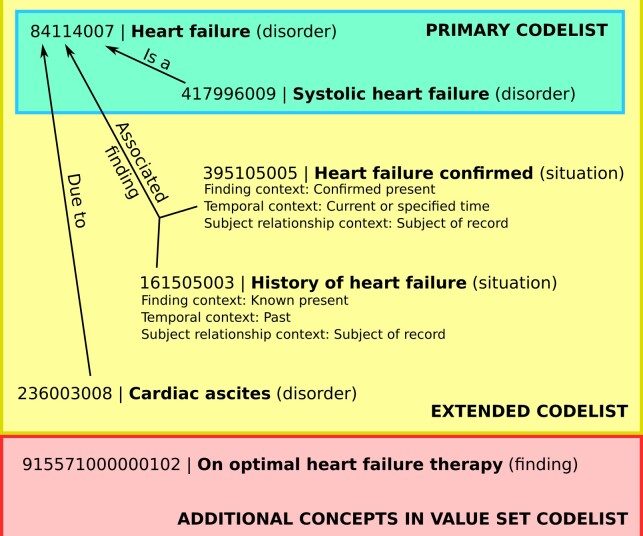
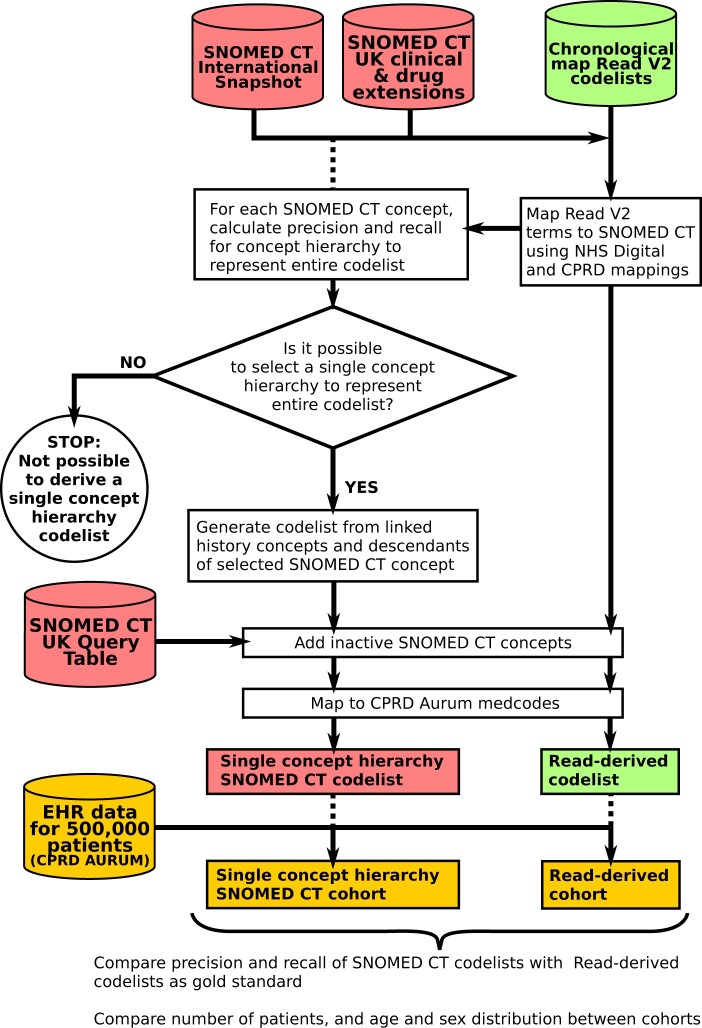
We developed SNOMED CT phenotype definitions for 3 exemplar diseases: diabetes mellitus, asthma, and heart failure, using 3 methods: "primary" (primary concept and its descendants), "extended" (primary concept, descendants, and additional relations), and "value set" (based on text searches of term descriptions). We also derived SNOMED CT codelists in a semiautomated manner for 276 disease phenotypes used in a study of health across the lifecourse. Cohorts selected using each codelist were compared to "gold standard" manually curated Read codelists in a sample of 500 000 patients from CPRD Aurum.
SNOMED CT codelists selected a similar set of patients to Read, with F1 scores exceeding 0.93, and age and sex distributions were similar. The "value set" and "extended" codelists had slightly greater recall but lower precision than "primary" codelists. We were able to represent 257 of the 276 phenotypes by a single concept hierarchy, and for 135 phenotypes, the F1 score was greater than 0.9.
SNOMED CT provides an efficient way to define disease phenotypes, resulting in similar patient populations to manually curated codelists.
基于术语的患者表型定义对于电子健康记录的计算使用是必需的。在英国初级保健研究数据库中,此类定义通常表示为 Read 术语的平面列表,但系统命名法医学临床术语(SNOMED CT)(一种广泛使用的国际参考术语)允许使用概念之间的关系,这可以促进表型过程。我们实施了基于 SNOMED CT 的表型方法,并在 CPRD Aurum 初级保健数据库中研究了它们的性能。
我们使用 3 种方法为 3 个范例疾病(糖尿病、哮喘和心力衰竭)开发了基于 SNOMED CT 的表型定义:“主要”(主要概念及其后代)、“扩展”(主要概念、后代和其他关系)和“值集”(基于术语描述的文本搜索)。我们还以半自动方式为在生命过程中跨健康研究中使用的 276 种疾病表型派生了 SNOMED CT 编码列表。使用每个编码列表选择的队列与 CPRD Aurum 中 500 000 名患者的“黄金标准”手动整理的 Read 编码列表进行了比较。
SNOMED CT 编码列表选择了与 Read 相似的患者集,F1 分数超过 0.93,年龄和性别分布相似。“值集”和“扩展”编码列表的召回率略高,但精度低于“主要”编码列表。我们能够用单个概念层次结构表示 276 种表型中的 257 种,对于 135 种表型,F1 分数大于 0.9。
SNOMED CT 提供了一种定义疾病表型的有效方法,导致与手动整理的编码列表相似的患者群体。