Department of Biomedical Informatics, Columbia University, New York, NY, United States; Medical Informatics Services, NewYork-Presbyterian Hospital, New York, NY, United States.
Department of Biomedical Informatics, Columbia University, New York, NY, United States.
J Biomed Inform. 2019 Aug;96:103253. doi: 10.1016/j.jbi.2019.103253. Epub 2019 Jul 17.
Implementing clinical phenotypes across a network is labor intensive and potentially error prone. Use of a common data model may facilitate the process.
Electronic Medical Records and Genomics (eMERGE) sites implemented the Observational Health Data Sciences and Informatics (OHDSI) Observational Medical Outcomes Partnership (OMOP) Common Data Model across their electronic health record (EHR)-linked DNA biobanks. Two previously implemented eMERGE phenotypes were converted to OMOP and implemented across the network.
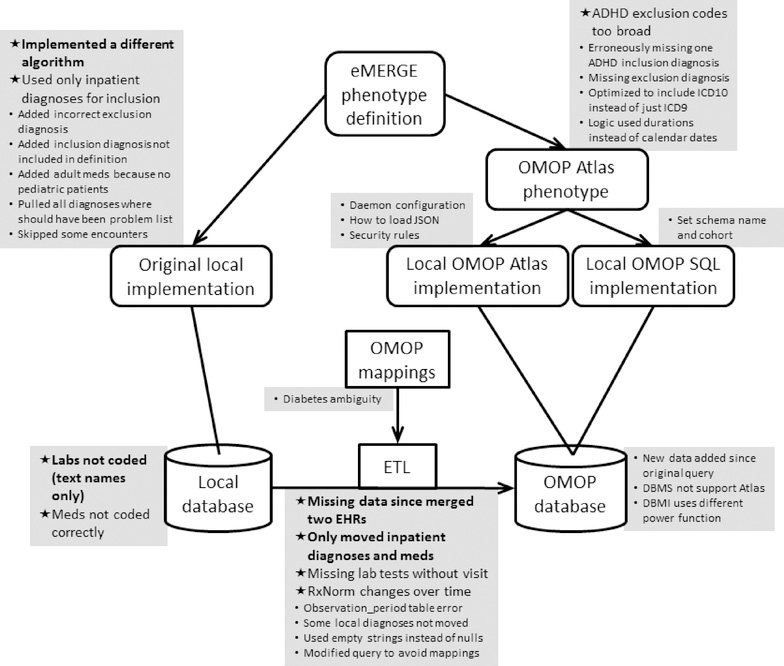
It was feasible to implement the common data model across sites, with laboratory data producing the greatest challenge due to local encoding. Sites were then able to execute the OMOP phenotype in less than one day, as opposed to weeks of effort to manually implement an eMERGE phenotype in their bespoke research EHR databases. Of the sites that could compare the current OMOP phenotype implementation with the original eMERGE phenotype implementation, specific agreement ranged from 100% to 43%, with disagreements due to the original phenotype, the OMOP phenotype, changes in data, and issues in the databases. Using the OMOP query as a standard comparison revealed differences in the original implementations despite starting from the same definitions, code lists, flowcharts, and pseudocode.
Using a common data model can dramatically speed phenotype implementation at the cost of having to populate that data model, though this will produce a net benefit as the number of phenotype implementations increases. Inconsistencies among the implementations of the original queries point to a potential benefit of using a common data model so that actual phenotype code and logic can be shared, mitigating human error in reinterpretation of a narrative phenotype definition.
在网络中实现临床表型既耗费人力,又容易出错。使用通用数据模型可能会简化这一过程。
电子病历和基因组学(eMERGE)站点在其电子健康记录(EHR)链接的 DNA 生物库中实施了观察性健康数据科学和信息学(OHDSI)观察性医疗结果伙伴关系(OMOP)通用数据模型。将之前实施的两个 eMERGE 表型转换为 OMOP 并在网络中实施。
在站点之间实施通用数据模型是可行的,由于本地编码,实验室数据带来了最大的挑战。然后,站点能够在不到一天的时间内执行 OMOP 表型,而不是在其定制的研究 EHR 数据库中手动实施 eMERGE 表型所需的数周时间。在能够比较当前 OMOP 表型实施与原始 eMERGE 表型实施的站点中,特定一致性范围为 100%至 43%,不一致的原因是原始表型、OMOP 表型、数据变化和数据库问题。使用 OMOP 查询作为标准比较揭示了尽管从相同的定义、代码列表、流程图和伪代码开始,但原始实施中的差异。
使用通用数据模型可以极大地加快表型实施的速度,但需要填充该数据模型,尽管随着表型实施数量的增加,这将产生净收益。原始查询实施中的不一致性表明使用通用数据模型可能具有潜在的益处,因为可以共享实际的表型代码和逻辑,从而减轻对叙述表型定义的重新解释中的人为错误。