Department of Epidemiology and Biostatistics, University of California, San Francisco, CA.
London School of Hygiene and Tropical Medicine, London, UK; Division of Biostatistics. School of Public Health, University of California, Berkeley, CA.
Ann Epidemiol. 2023 Jan;77:24-30. doi: 10.1016/j.annepidem.2022.10.010. Epub 2022 Nov 1.
Capture-recapture methods estimate the size of hidden populations by leveraging the proportion of overlap of the population on independent lists. Log-linear modeling relaxes the assumption of list independence, but best model selection criteria remain uncertain. Incorrect model selection can deliver incorrect and even implausible size estimates.
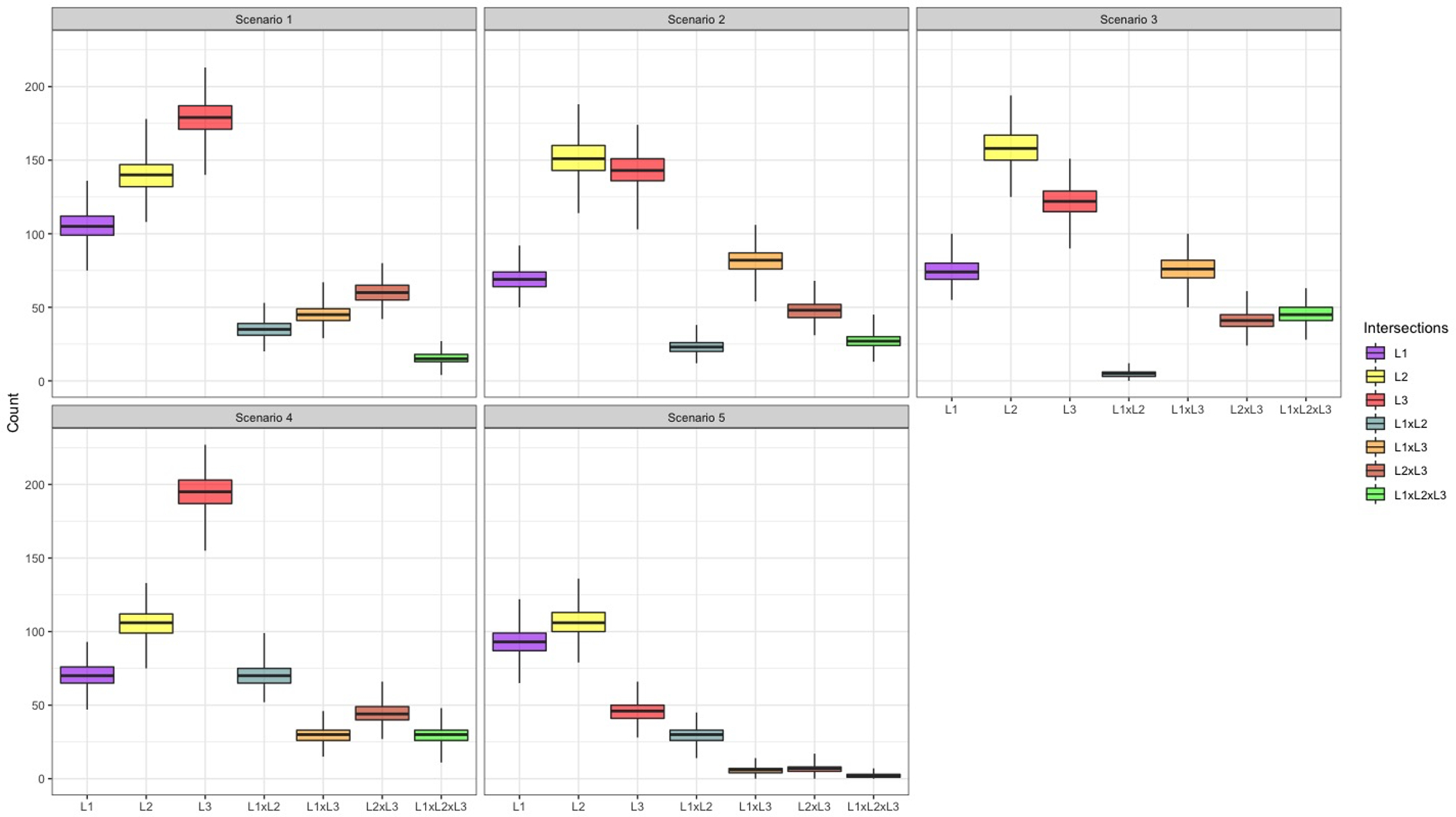
We used simulations to model when capture-recapture methods deliver biased or unbiased estimates and compare model selection criteria. Simulations included five scenarios for list dependence among three incomplete lists of population of interest. We compared metrics of log-linear model selection, accuracy, and precision. We also compared log-linear model performance to the decomposable graph approach (a Bayesian model average), the sparse multiple systems estimation (SparseMSE) approach that accounts for zero or low cell counts, and the Sample Coverage approach.
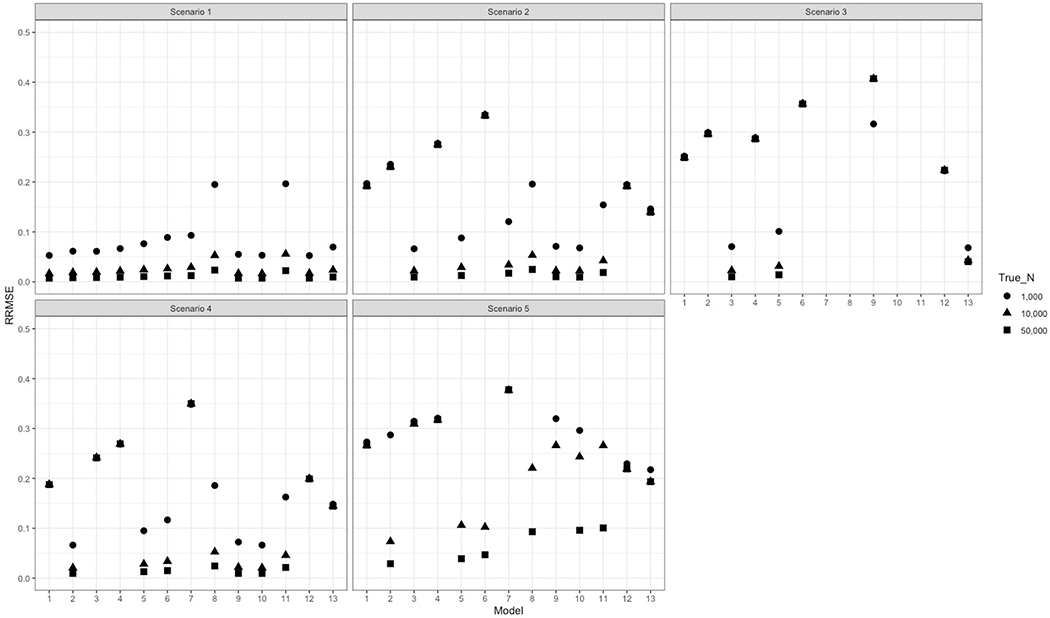
Log-linear models selected by Akaike's information criterion (AIC) calculated accurate population size estimates in all scenarios except for those with sparse or zero cell counts. In these scenarios, the decomposable graph and the Sample Coverage models produced more accurate size estimates.
Conventional capture-recapture model selection fails with sparse cell counts. This naïve approach to model selection should be replaced with the implementation of multiple different models in order triangulate the truth in real-world applications.
捕获-再捕获方法通过利用人口在独立列表上的重叠比例来估计隐藏人口的规模。对数线性模型放宽了列表独立性的假设,但最佳模型选择标准仍不确定。不正确的模型选择可能会导致不正确甚至不合理的规模估计。
我们使用模拟来模拟捕获-再捕获方法何时提供有偏或无偏的估计,并比较模型选择标准。模拟包括三种不完全的感兴趣人群列表之间的五种列表依赖情况。我们比较了对数线性模型选择、准确性和精度的指标。我们还比较了对数线性模型与可分解图方法(贝叶斯模型平均)、稀疏多系统估计(SparseMSE)方法(考虑零或低细胞计数)和样本覆盖方法的性能。
除了稀疏或零细胞计数的情况外,基于 Akaike 信息准则(AIC)选择的对数线性模型在所有情况下都能准确估计人口规模。在这些情况下,可分解图和样本覆盖模型产生了更准确的规模估计。
在稀疏的细胞计数情况下,传统的捕获-再捕获模型选择失败。这种简单的模型选择方法应该用多种不同模型的实现来替代,以便在实际应用中确定真相。