MRC/CSO Social and Public Health Sciences Unit, University of Glasgow, Berkeley Square, 99 Berkeley Street, Glasgow, G3 7HR, UK.
UCL Great Ormond Street Institute of Child Health, UCL, London, UK.
Eur J Epidemiol. 2022 Dec;37(12):1215-1224. doi: 10.1007/s10654-022-00934-w. Epub 2022 Nov 5.
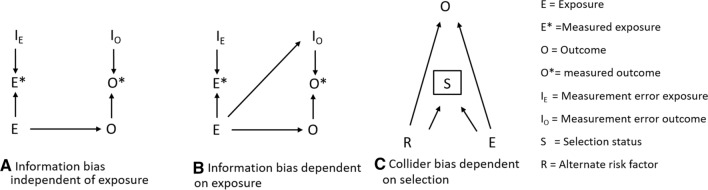
Linked administrative data offer a rich source of information that can be harnessed to describe patterns of disease, understand their causes and evaluate interventions. However, administrative data are primarily collected for operational reasons such as recording vital events for legal purposes, and planning, provision and monitoring of services. The processes involved in generating and linking administrative datasets may generate sources of bias that are often not adequately considered by researchers. We provide a framework describing these biases, drawing on our experiences of using the 100 Million Brazilian Cohort (100MCohort) which contains records of more than 131 million people whose families applied for social assistance between 2001 and 2018. Datasets for epidemiological research were derived by linking the 100MCohort to health-related databases such as the Mortality Information System and the Hospital Information System. Using the framework, we demonstrate how selection and misclassification biases may be introduced in three different stages: registering and recording of people's life events and use of services, linkage across administrative databases, and cleaning and coding of variables from derived datasets. Finally, we suggest eight recommendations which may reduce biases when analysing data from administrative sources.
关联行政数据提供了丰富的信息来源,可以用来描述疾病模式,了解其病因,并评估干预措施。然而,行政数据主要是出于操作目的而收集的,例如为法律目的记录重要事件,以及规划、提供和监测服务。在生成和关联行政数据集的过程中,可能会产生研究人员通常没有充分考虑的偏差来源。我们提供了一个描述这些偏差的框架,借鉴了我们使用 1 亿巴西队列(100MCohort)的经验,该队列包含了超过 1.31 亿人的记录,他们的家庭在 2001 年至 2018 年期间申请了社会援助。用于流行病学研究的数据集是通过将 100MCohort 与健康相关的数据库(如死亡率信息系统和医院信息系统)链接而得出的。使用该框架,我们展示了选择和分类错误偏差可能在三个不同阶段引入:记录和记录人们的生命事件和服务的使用,跨行政数据库的链接,以及从派生数据集中清理和编码变量。最后,我们提出了八项建议,这些建议可能会减少分析行政来源数据时的偏差。