Park Seyoung, Xu Hao, Zhao Hongyu
Department of Statistics, Sungkyunkwan University, Seoul, Korea.
Department of Biostatistics, Yale School of Public Health, New Haven, CT.
J Am Stat Assoc. 2021;116(533):14-26. doi: 10.1080/01621459.2020.1730853. Epub 2020 Mar 19.
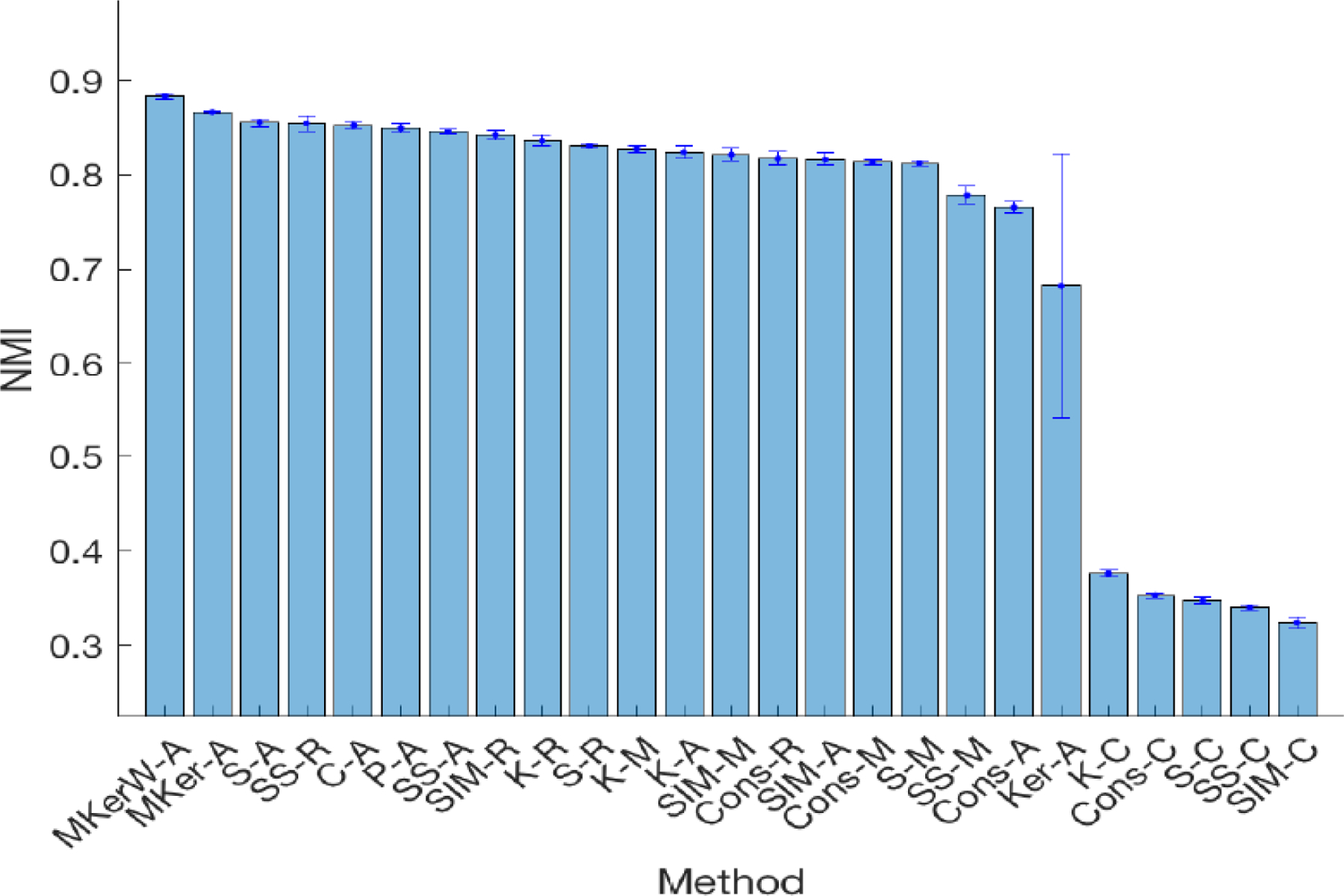
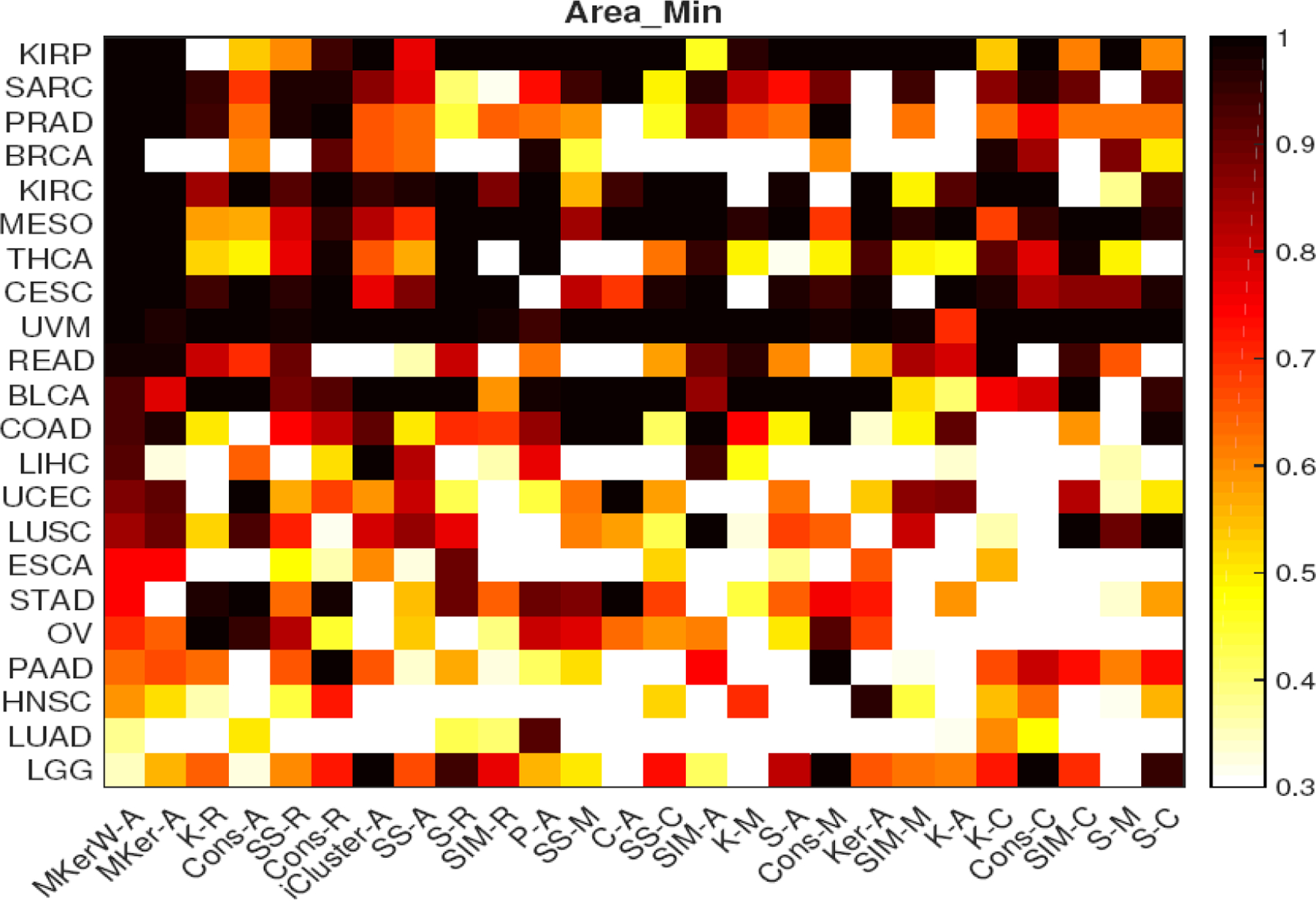
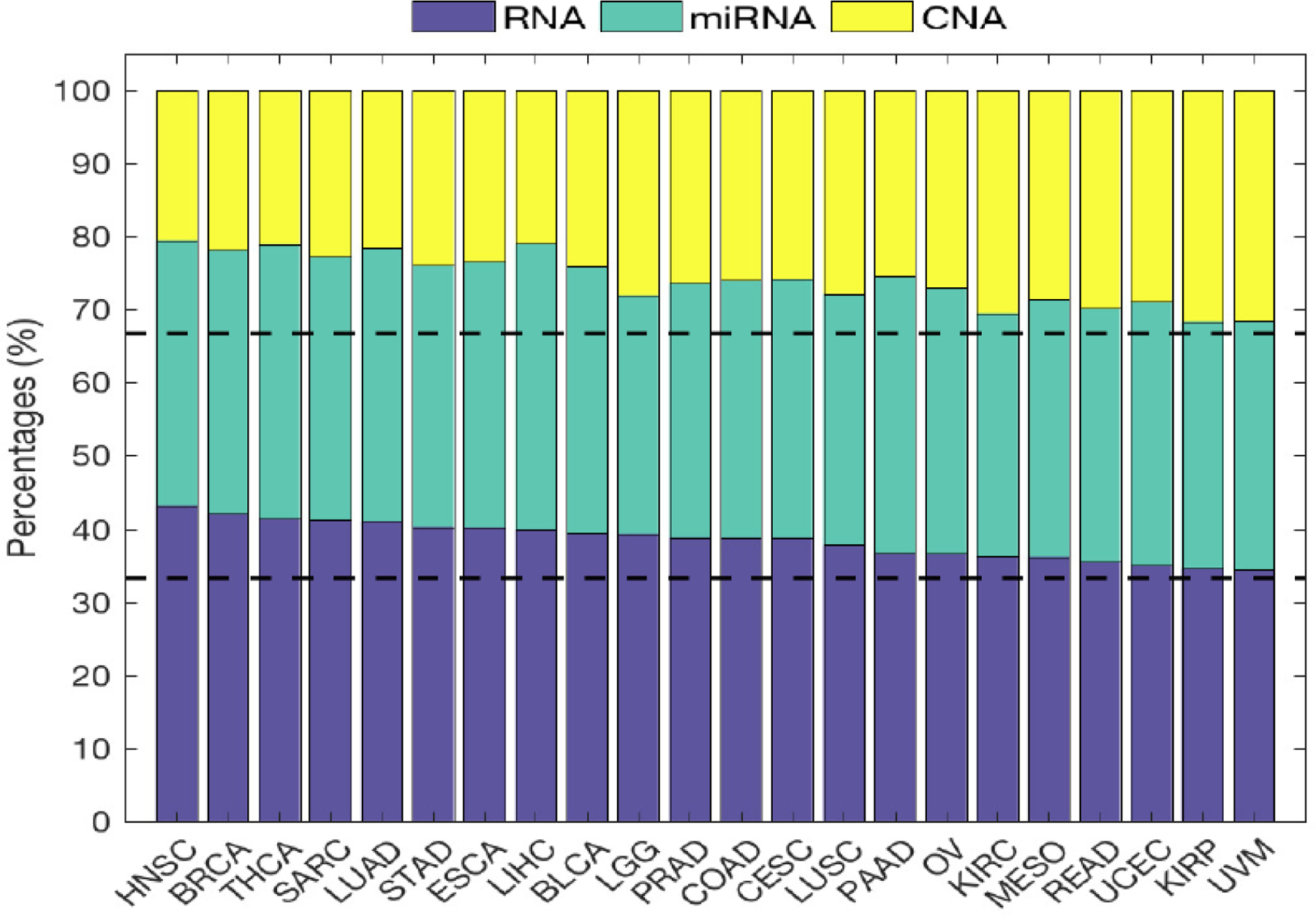
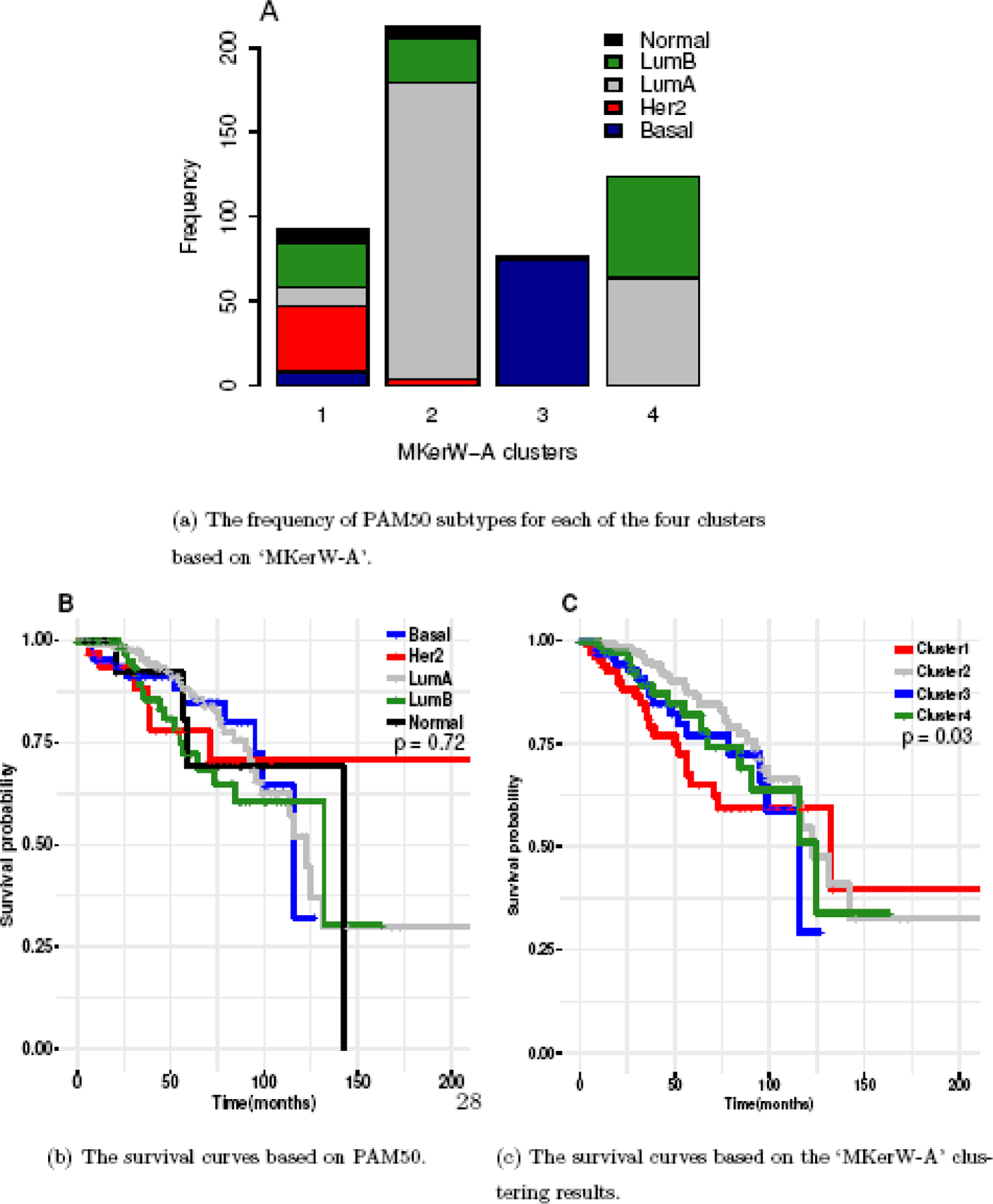
Advances in high-throughput genomic technologies coupled with large-scale studies including The Cancer Genome Atlas (TCGA) project have generated rich resources of diverse types of omics data to better understand cancer etiology and treatment responses. Clustering patients into subtypes with similar disease etiologies and/or treatment responses using multiple omics data types has the potential to improve the precision of clustering than using a single data type. However, in practice, patient clustering is still mostly based on a single type of omics data or ad hoc integration of clustering results from individual data types, leading to potential loss of information. By treating each omics data type as a different informative representation from patients, we propose a novel multi-view spectral clustering framework to integrate different omics data types measured from the same subject. We learn the weight of each data type as well as a similarity measure between patients via a non-convex optimization framework. We solve the proposed non-convex problem iteratively using the ADMM algorithm and show the convergence of the algorithm. The accuracy and robustness of the proposed clustering method is studied both in theory and through various synthetic data. When our method is applied to the TCGA data, the patient clusters inferred by our method show more significant differences in survival times between clusters than those inferred from existing clustering methods.
高通量基因组技术的进步,再加上包括癌症基因组图谱(TCGA)项目在内的大规模研究,已经产生了丰富的各种组学数据资源,以更好地理解癌症病因和治疗反应。与使用单一数据类型相比,使用多种组学数据类型将患者聚类为具有相似疾病病因和/或治疗反应的亚型,有可能提高聚类的精度。然而,在实践中,患者聚类仍然主要基于单一类型的组学数据或对来自单个数据类型的聚类结果进行临时整合,从而导致潜在的信息丢失。通过将每种组学数据类型视为来自患者的不同信息表示,我们提出了一种新颖的多视图谱聚类框架,以整合从同一受试者测量的不同组学数据类型。我们通过一个非凸优化框架学习每种数据类型的权重以及患者之间的相似性度量。我们使用交替方向乘子法(ADMM)算法迭代求解所提出的非凸问题,并证明了该算法的收敛性。我们从理论和各种合成数据方面研究了所提出的聚类方法的准确性和鲁棒性。当我们的方法应用于TCGA数据时,我们的方法推断出的患者聚类在聚类之间的生存时间上显示出比现有聚类方法推断出的聚类更显著的差异。