John Maura, Haselbeck Florian, Dass Rupashree, Malisi Christoph, Ricca Patrizia, Dreischer Christian, Schultheiss Sebastian J, Grimm Dominik G
Technical University of Munich, Campus Straubing for Biotechnology and Sustainability, Bioinformatics, Straubing, Germany.
Weihenstephan-Triesdorf University of Applied Sciences, Bioinformatics, Straubing, Germany.
Front Plant Sci. 2022 Nov 4;13:932512. doi: 10.3389/fpls.2022.932512. eCollection 2022.
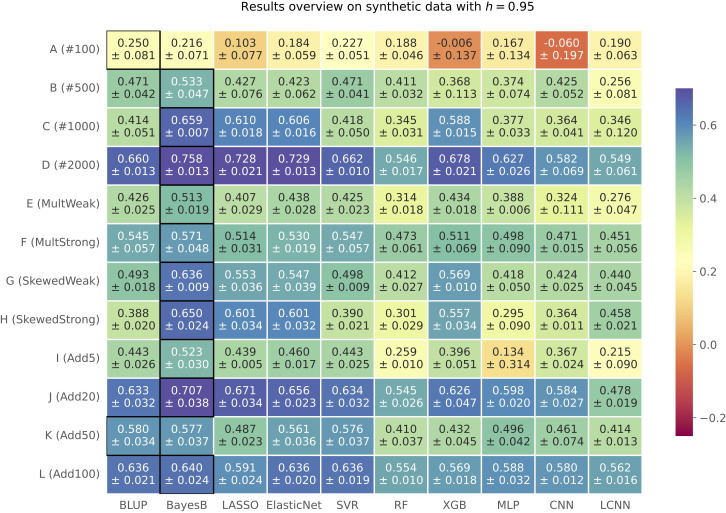
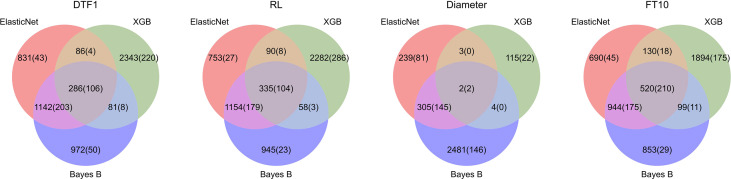
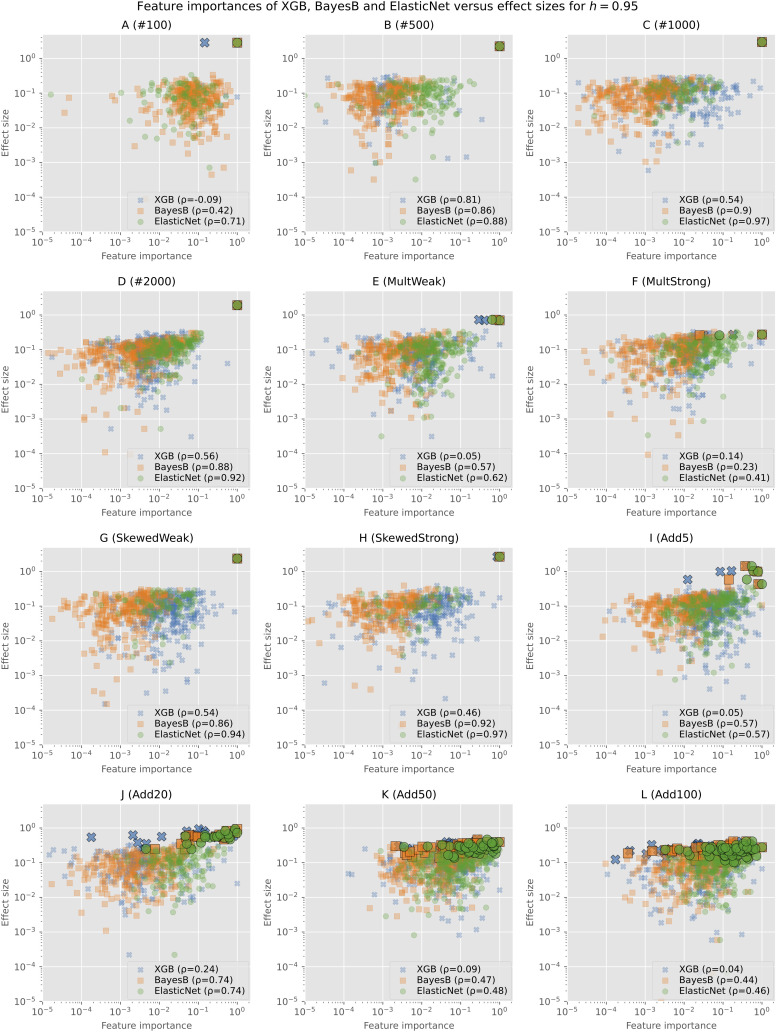
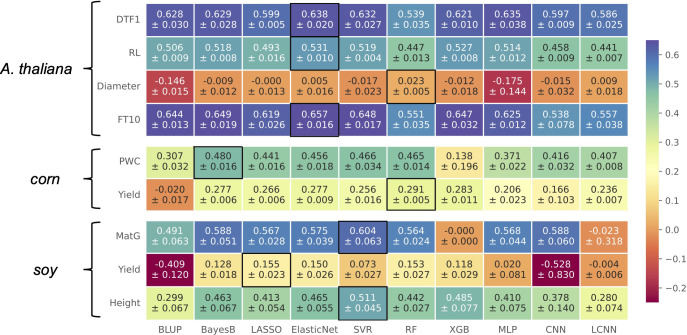
Genomic selection is an integral tool for breeders to accurately select plants directly from genotype data leading to faster and more resource-efficient breeding programs. Several prediction methods have been established in the last few years. These range from classical linear mixed models to complex non-linear machine learning approaches, such as Support Vector Regression, and modern deep learning-based architectures. Many of these methods have been extensively evaluated on different crop species with varying outcomes. In this work, our aim is to systematically compare 12 different phenotype prediction models, including basic genomic selection methods to more advanced deep learning-based techniques. More importantly, we assess the performance of these models on simulated phenotype data as well as on real-world data from and two breeding datasets from soy and corn. The synthetic phenotypic data allow us to analyze all prediction models and especially the selected markers under controlled and predefined settings. We show that Bayes B and linear regression models with sparsity constraints perform best under different simulation settings with respect to explained variance. Further, we can confirm results from other studies that there is no superiority of more complex neural network-based architectures for phenotype prediction compared to well-established methods. However, on real-world data, for which several prediction models yield comparable results with slight advantages for Elastic Net, this picture is less clear, suggesting that there is a lot of room for future research.
基因组选择是育种者直接根据基因型数据准确选择植物的一项重要工具,可带来更快且资源利用效率更高的育种计划。在过去几年中已经建立了多种预测方法。这些方法从经典的线性混合模型到复杂的非线性机器学习方法,如支持向量回归,以及基于现代深度学习的架构。其中许多方法已经在不同作物物种上进行了广泛评估,结果各异。在这项工作中,我们的目标是系统地比较12种不同的表型预测模型,包括基本的基因组选择方法到更先进的基于深度学习的技术。更重要的是,我们评估这些模型在模拟表型数据以及来自大豆和玉米的两个育种数据集的真实世界数据上的性能。合成表型数据使我们能够在受控和预定义的设置下分析所有预测模型,特别是所选标记。我们表明,贝叶斯B模型和具有稀疏性约束的线性回归模型在不同模拟设置下在解释方差方面表现最佳。此外,我们可以证实其他研究的结果,即与成熟方法相比,基于更复杂神经网络的架构在表型预测方面没有优势。然而,在真实世界数据上,几种预测模型产生了可比的结果,弹性网络略有优势,情况不太明确,这表明未来研究还有很大空间。