Department of Petroleum Engineering, Amirkabir University of Technology (Tehran Polytechnic), 424 Hafez Avenue, Box 15875-4413, Tehran, 1591634311, Iran.
Sci Rep. 2023 Jan 30;13(1):1666. doi: 10.1038/s41598-023-28770-2.
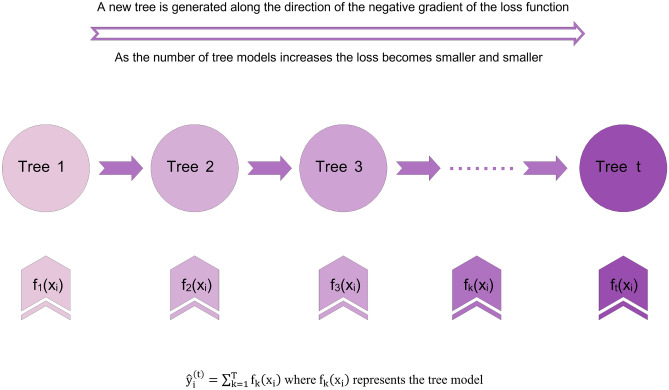
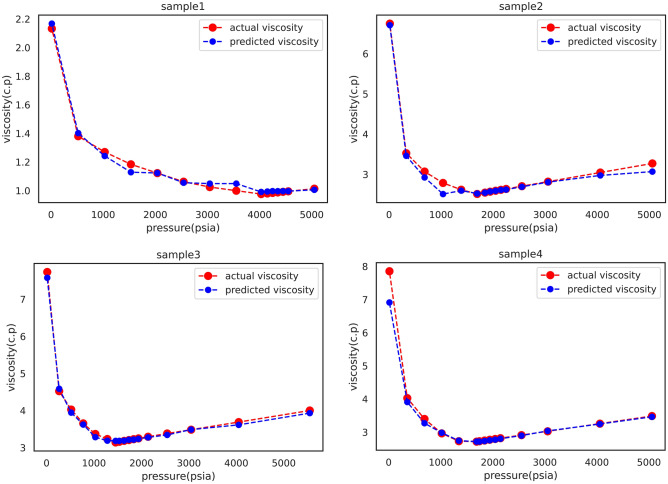
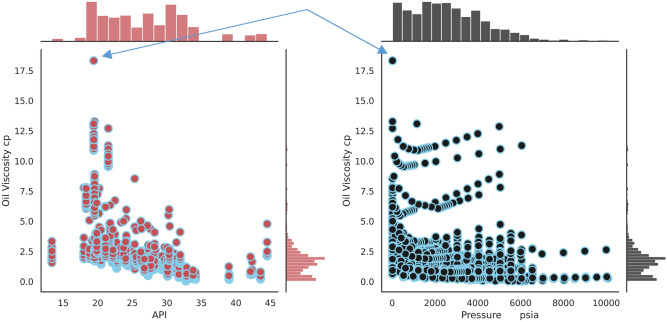
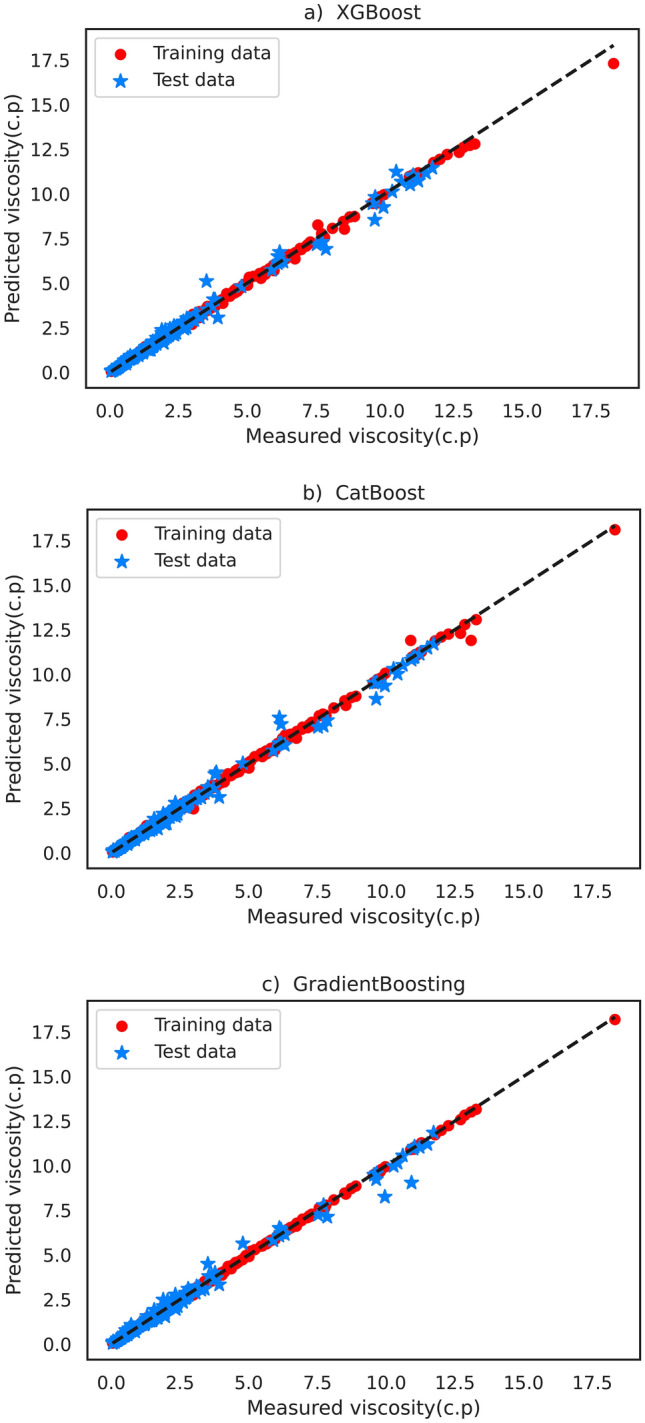
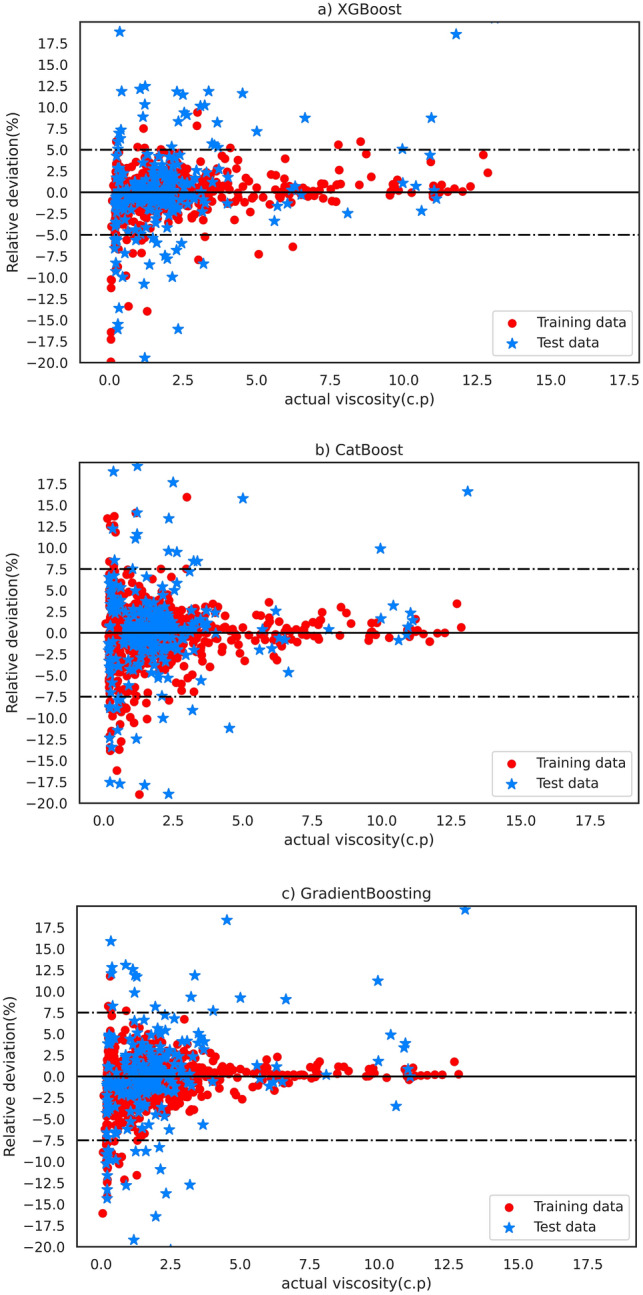
Oil viscosity plays a prominent role in all areas of petroleum engineering, such as simulating reservoirs, predicting production rate, evaluating oil well performance, and even planning for thermal enhanced oil recovery (EOR) that involves fluid flow calculations. Experimental methods of determining oil viscosity, such as the rotational viscometer, are more accurate than other methods. The compositional method can also properly estimate oil viscosity. However, the composition of oil should be determined experimentally, which is costly and time-consuming. Therefore, the occasional inaccessibility of experimental data may make it inevitable to look for convenient methods for fast and accurate prediction of oil viscosity. Hence, in this study, the error in viscosity prediction has been minimized by taking into account the amount of dissolved gas in oil (solution gas-oil ratio: R) as a representative of oil composition along with other conventional black oil features including temperature, pressure, and API gravity by employing recently developed machine learning methods based on the gradient boosting decision tree (GBDT): extreme gradient boosting (XGBoost), CatBoost, and GradientBoosting. Moreover, the advantage of the proposed method lies in its independence to input viscosity data in each pressure region/stage. The results were then compared with well-known correlations and machine-learning methods employing the black oil approach applying least square support vector machine (LSSVM) and compositional approach implementing decision trees (DTs). XGBoost is offered as the best method with its greater precision and lower error. It provides an overall average absolute relative deviation (AARD) of 1.968% which has reduced the error of the compositional method by half and the black oil method (saturated region) by five times. This shows the proper viscosity prediction and corroborates the applied method's performance.
油的黏度在石油工程的各个领域都起着重要作用,例如模拟油藏、预测产量、评估油井性能,甚至规划涉及流体流动计算的热采提高采收率(EOR)。用于确定油黏度的实验方法,如旋转黏度计,比其他方法更准确。组成方法也可以正确估计油的黏度。然而,油的组成需要通过实验来确定,这既昂贵又耗时。因此,在某些情况下,无法获得实验数据可能会导致我们不得不寻找方便的方法来快速准确地预测油的黏度。因此,在这项研究中,通过考虑油中溶解气的量(溶解气油比:R)作为油组成的代表,结合其他常规的黑油特征,包括温度、压力和 API 度,利用基于梯度提升决策树(GBDT)的最新开发的机器学习方法,最大限度地减少了黏度预测中的误差:极端梯度提升(XGBoost)、CatBoost 和梯度提升。此外,该方法的优点在于它可以独立于输入每个压力区域/阶段的黏度数据。然后将结果与著名的关联和机器学习方法进行比较,这些方法采用黑油方法(使用最小二乘支持向量机(LSSVM))和基于决策树(DTs)的组成方法。XGBoost 被认为是最好的方法,因为它具有更高的精度和更低的误差。它提供了 1.968%的整体平均绝对相对偏差(AARD),将组成方法的误差降低了一半,将黑油方法(饱和区域)的误差降低了五倍。这表明了适当的黏度预测,并证实了所应用方法的性能。