School of Computing and Information Systems, University of Melbourne, Melbourne, Australia.
Mohamed bin Zayed University of Artificial Intelligence, Abu Dhabi, United Arab Emirates.
J Med Internet Res. 2023 Mar 13;25:e35568. doi: 10.2196/35568.
Assessment of the quality of medical evidence available on the web is a critical step in the preparation of systematic reviews. Existing tools that automate parts of this task validate the quality of individual studies but not of entire bodies of evidence and focus on a restricted set of quality criteria.
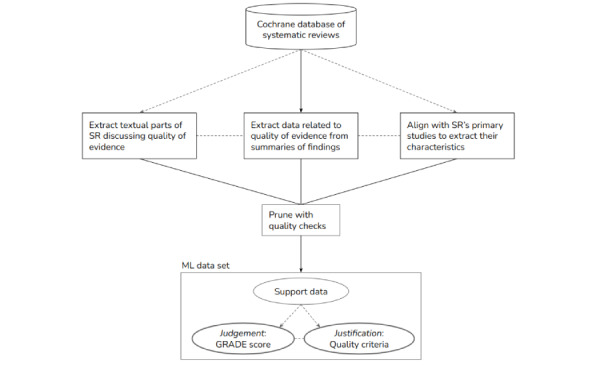
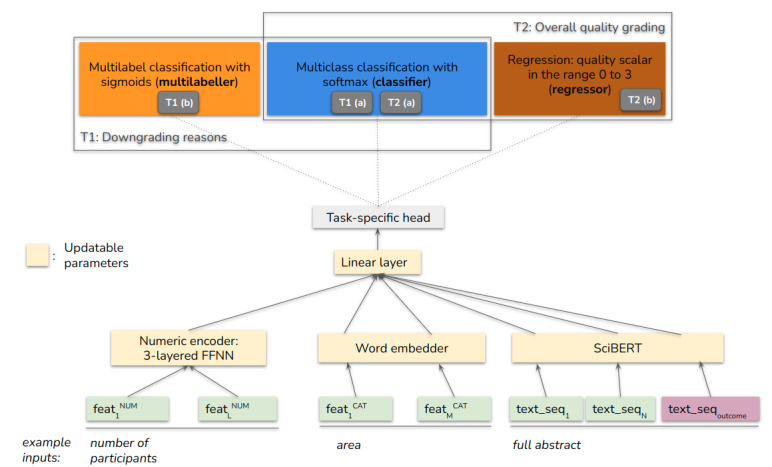
We proposed a quality assessment task that provides an overall quality rating for each body of evidence (BoE), as well as finer-grained justification for different quality criteria according to the Grading of Recommendation, Assessment, Development, and Evaluation formalization framework. For this purpose, we constructed a new data set and developed a machine learning baseline system (EvidenceGRADEr).
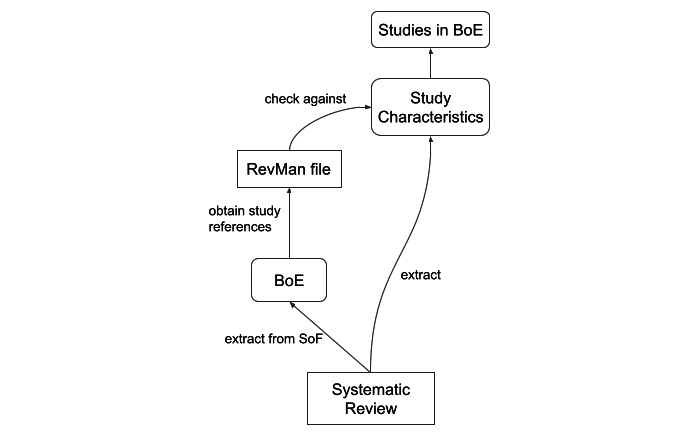
We algorithmically extracted quality-related data from all summaries of findings found in the Cochrane Database of Systematic Reviews. Each BoE was defined by a set of population, intervention, comparison, and outcome criteria and assigned a quality grade (high, moderate, low, or very low) together with quality criteria (justification) that influenced that decision. Different statistical data, metadata about the review, and parts of the review text were extracted as support for grading each BoE. After pruning the resulting data set with various quality checks, we used it to train several neural-model variants. The predictions were compared against the labels originally assigned by the authors of the systematic reviews.
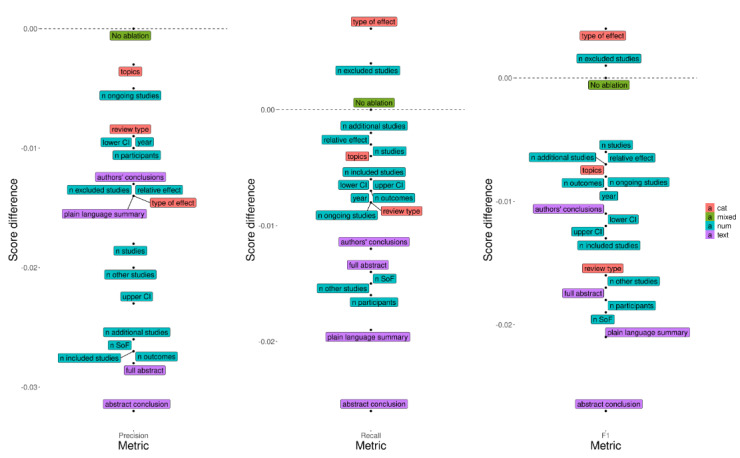
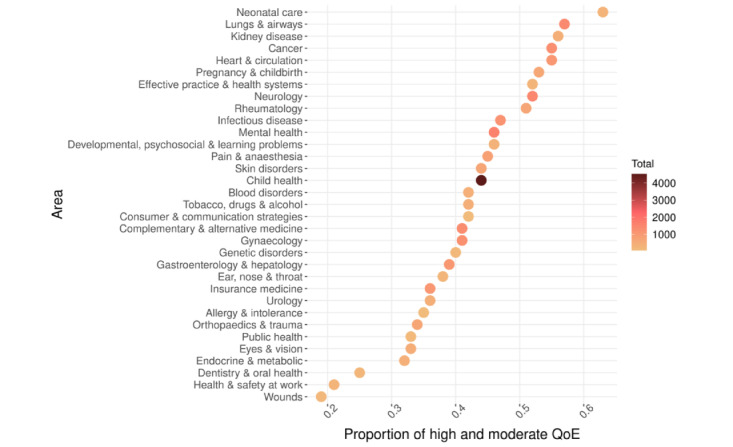
Our quality assessment data set, Cochrane Database of Systematic Reviews Quality of Evidence, contains 13,440 instances, or BoEs labeled for quality, originating from 2252 systematic reviews published on the internet from 2002 to 2020. On the basis of a 10-fold cross-validation, the best neural binary classifiers for quality criteria detected risk of bias at 0.78 F (P=.68; R=0.92) and imprecision at 0.75 F (P=.66; R=0.86), while the performance on inconsistency, indirectness, and publication bias criteria was lower (F in the range of 0.3-0.4). The prediction of the overall quality grade into 1 of the 4 levels resulted in 0.5 F. When casting the task as a binary problem by merging the Grading of Recommendation, Assessment, Development, and Evaluation classes (high+moderate vs low+very low-quality evidence), we attained 0.74 F. We also found that the results varied depending on the supporting information that is provided as an input to the models.
Different factors affect the quality of evidence in the context of systematic reviews of medical evidence. Some of these (risk of bias and imprecision) can be automated with reasonable accuracy. Other quality dimensions such as indirectness, inconsistency, and publication bias prove more challenging for machine learning, largely because they are much rarer. This technology could substantially reduce reviewer workload in the future and expedite quality assessment as part of evidence synthesis.
评估网络上可用的医学证据的质量是系统评价准备工作的关键步骤。现有的自动化部分任务的工具可验证单个研究的质量,但不能验证整个证据体的质量,并且仅关注有限数量的质量标准。
我们提出了一项质量评估任务,可为每个证据体(BoE)提供整体质量评级,并根据推荐评估发展和评估(Grading of Recommendation,Assessment,Development,and Evaluation)正式化框架,为不同的质量标准提供更细粒度的理由。为此,我们构建了一个新的数据集并开发了一个机器学习基线系统(EvidenceGRADEr)。
我们从 Cochrane 系统评价数据库中的所有发现摘要中自动提取与质量相关的数据。每个 BoE 由一组人群、干预、比较和结局标准定义,并根据 Grading of Recommendation,Assessment,Development,and Evaluation 决策框架分配质量等级(高、中、低或极低)以及影响该决策的质量标准(理由)。提取了不同的统计数据、有关综述的元数据和部分综述文本,作为对每个 BoE 进行评分的依据。在使用各种质量检查对生成的数据进行修剪后,我们使用它来训练多个神经网络模型变体。将预测结果与系统评价作者最初分配的标签进行比较。
我们的质量评估数据集 Cochrane 系统评价证据质量包含 13440 个实例,即根据 2002 年至 2020 年在互联网上发表的 2252 篇系统评价对质量进行了标记的 BoE。基于 10 折交叉验证,用于检测偏倚风险的最佳二元神经网络分类器的质量标准为 0.78 F(P=.68;R=0.92),用于检测不精确性的质量标准为 0.75 F(P=.66;R=0.86),而不一致性、间接性和发表偏倚标准的性能较低(F 值在 0.3 到 0.4 之间)。将整体质量等级预测为 4 个等级中的 1 个等级的结果为 0.5 F。当将任务作为二元问题处理,通过合并推荐评估发展和评估(Grading of Recommendation,Assessment,Development,and Evaluation)类别(高质量+中质量与低质量+极低质量证据)时,我们达到了 0.74 F。我们还发现,结果因提供给模型的支持信息而有所不同。
在医学证据系统评价的背景下,不同因素会影响证据的质量。其中一些(偏倚风险和不精确性)可以通过合理的准确性进行自动化处理。其他质量维度,如间接性、不一致性和发表偏倚,对机器学习来说证明更具挑战性,这在很大程度上是因为它们更为罕见。这项技术未来可以大大减轻审查员的工作量,并加快证据综合过程中的质量评估。