Li Mingchen, Kang Liqi, Xiong Yi, Wang Yu Guang, Fan Guisheng, Tan Pan, Hong Liang
Shanghai National Center for Applied Mathematics (SJTU Center), & Institute of Natural Sciences, Shanghai Jiao Tong University, Shanghai, 200240, China.
School of Information Science and Engineering, East China University of Science and Technology, Shanghai, 200240, China.
J Cheminform. 2023 Feb 3;15(1):12. doi: 10.1186/s13321-023-00688-x.
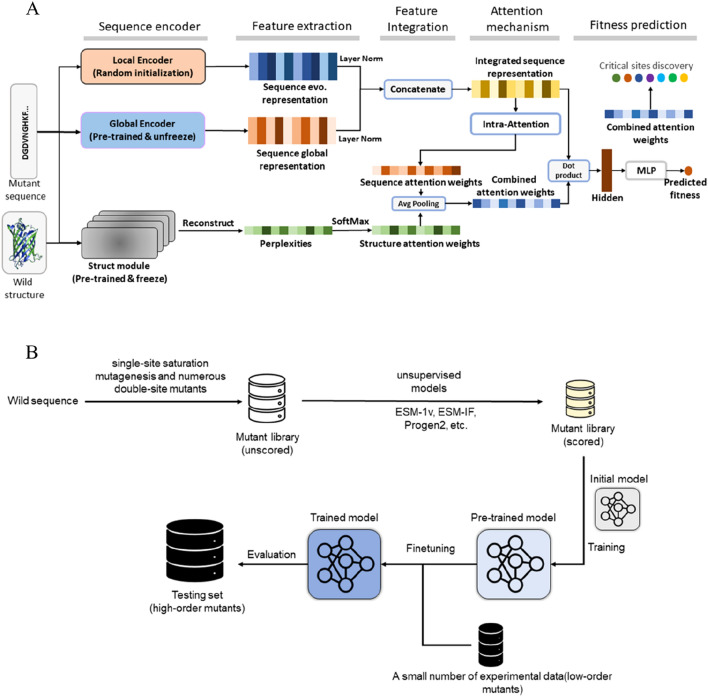
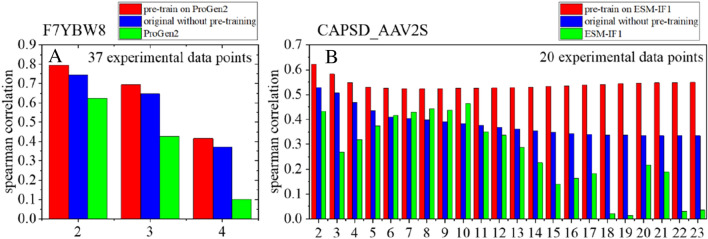
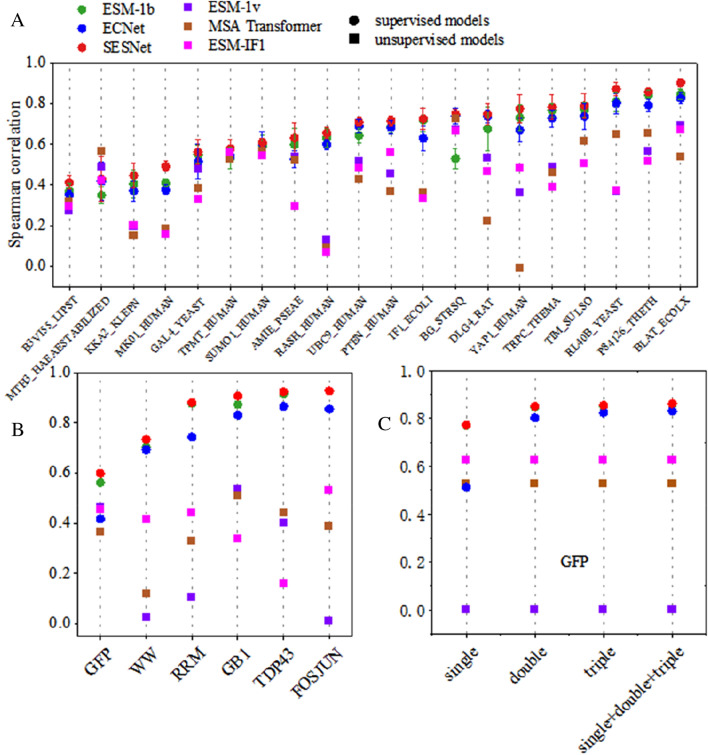
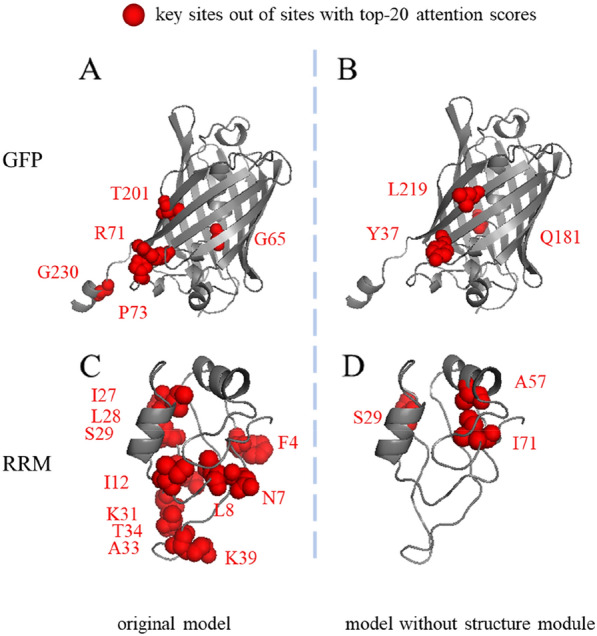
Deep learning has been widely used for protein engineering. However, it is limited by the lack of sufficient experimental data to train an accurate model for predicting the functional fitness of high-order mutants. Here, we develop SESNet, a supervised deep-learning model to predict the fitness for protein mutants by leveraging both sequence and structure information, and exploiting attention mechanism. Our model integrates local evolutionary context from homologous sequences, the global evolutionary context encoding rich semantic from the universal protein sequence space and the structure information accounting for the microenvironment around each residue in a protein. We show that SESNet outperforms state-of-the-art models for predicting the sequence-function relationship on 26 deep mutational scanning datasets. More importantly, we propose a data augmentation strategy by leveraging the data from unsupervised models to pre-train our model. After that, our model can achieve strikingly high accuracy in prediction of the fitness of protein mutants, especially for the higher order variants (> 4 mutation sites), when finetuned by using only a small number of experimental mutation data (< 50). The strategy proposed is of great practical value as the required experimental effort, i.e., producing a few tens of experimental mutation data on a given protein, is generally affordable by an ordinary biochemical group and can be applied on almost any protein.
深度学习已广泛应用于蛋白质工程。然而,它受到缺乏足够实验数据的限制,无法训练出一个准确的模型来预测高阶突变体的功能适应性。在此,我们开发了SESNet,这是一种监督式深度学习模型,通过利用序列和结构信息并运用注意力机制来预测蛋白质突变体的适应性。我们的模型整合了来自同源序列的局部进化背景、从通用蛋白质序列空间编码丰富语义的全局进化背景以及考虑蛋白质中每个残基周围微环境的结构信息。我们表明,在26个深度突变扫描数据集上,SESNet在预测序列-功能关系方面优于现有最先进的模型。更重要的是,我们提出了一种数据增强策略,通过利用来自无监督模型的数据对我们的模型进行预训练。在此之后,当仅使用少量实验突变数据(<50个)进行微调时,我们的模型在预测蛋白质突变体的适应性方面能够达到极高的准确率,特别是对于高阶变体(>4个突变位点)。所提出的策略具有很大的实用价值,因为所需的实验工作量,即在给定蛋白质上生成几十条实验突变数据,通常是普通生化小组能够承受的,并且几乎可以应用于任何蛋白质。