Department of Computer Science, Johannes Gutenberg University Mainz, Mainz, Germany.
BMC Bioinformatics. 2023 Feb 14;24(1):45. doi: 10.1186/s12859-023-05166-7.
Recent years have seen a surge of novel neural network architectures for the integration of multi-omics data for prediction. Most of the architectures include either encoders alone or encoders and decoders, i.e., autoencoders of various sorts, to transform multi-omics data into latent representations. One important parameter is the depth of integration: the point at which the latent representations are computed or merged, which can be either early, intermediate, or late. The literature on integration methods is growing steadily, however, close to nothing is known about the relative performance of these methods under fair experimental conditions and under consideration of different use cases.
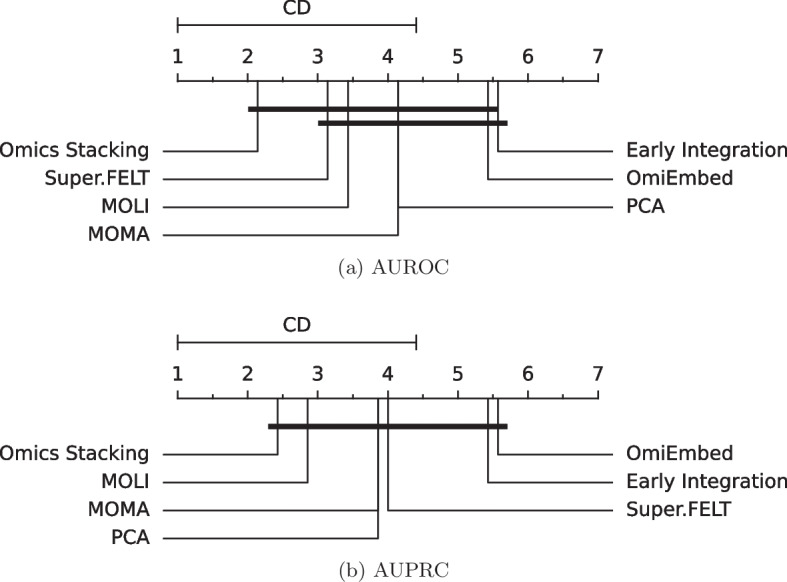
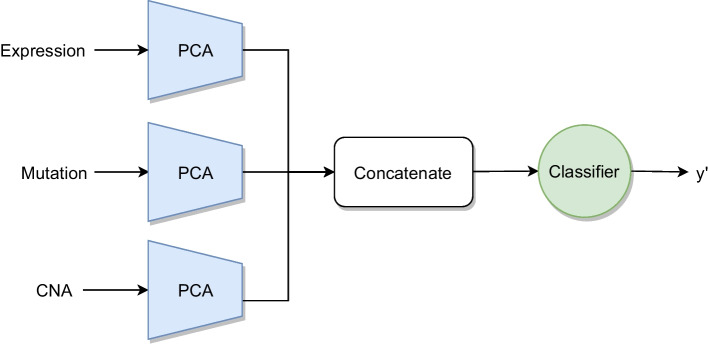
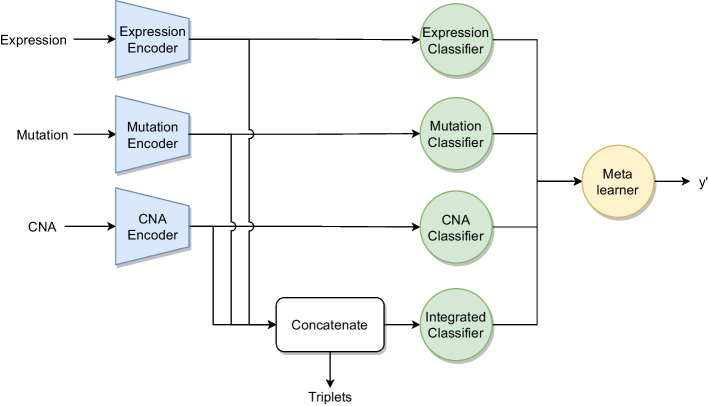
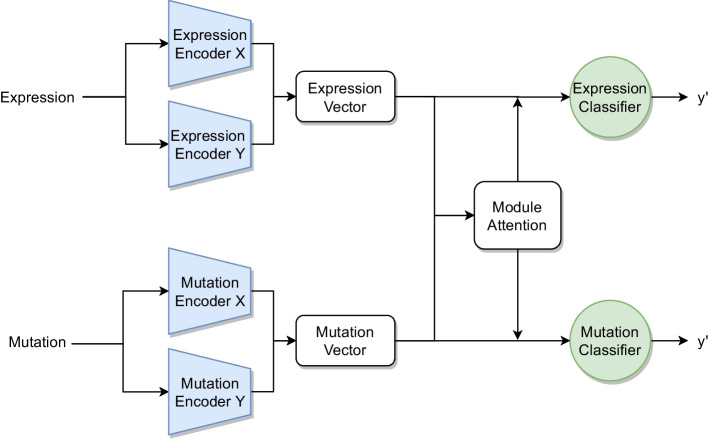
We developed a comparison framework that trains and optimizes multi-omics integration methods under equal conditions. We incorporated early integration, PCA and four recently published deep learning methods: MOLI, Super.FELT, OmiEmbed, and MOMA. Further, we devised a novel method, Omics Stacking, that combines the advantages of intermediate and late integration. Experiments were conducted on a public drug response data set with multiple omics data (somatic point mutations, somatic copy number profiles and gene expression profiles) that was obtained from cell lines, patient-derived xenografts, and patient samples. Our experiments confirmed that early integration has the lowest predictive performance. Overall, architectures that integrate triplet loss achieved the best results. Statistical differences can, overall, rarely be observed, however, in terms of the average ranks of methods, Super.FELT is consistently performing best in a cross-validation setting and Omics Stacking best in an external test set setting.
We recommend researchers to follow fair comparison protocols, as suggested in the paper. When faced with a new data set, Super.FELT is a good option in the cross-validation setting as well as Omics Stacking in the external test set setting. Statistical significances are hardly observable, despite trends in the algorithms' rankings. Future work on refined methods for transfer learning tailored for this domain may improve the situation for external test sets. The source code of all experiments is available under https://github.com/kramerlab/Multi-Omics_analysis.
近年来,出现了许多用于整合多组学数据进行预测的新型神经网络架构。大多数架构都包含编码器,或者编码器和解码器,即各种类型的自动编码器,将多组学数据转换为潜在表示。一个重要的参数是整合的深度:计算或合并潜在表示的点,可以是早期、中期或晚期。关于整合方法的文献正在稳步增加,然而,在公平的实验条件下,以及在考虑不同用例的情况下,几乎没有人知道这些方法的相对性能。
我们开发了一个比较框架,可以在同等条件下训练和优化多组学整合方法。我们纳入了早期整合、PCA 以及最近发表的四种深度学习方法:MOLI、Super.FELT、OmiEmbed 和 MOMA。此外,我们设计了一种新的方法,Omics Stacking,它结合了中期和晚期整合的优势。实验是在一个具有多个组学数据(体细胞点突变、体细胞拷贝数谱和基因表达谱)的公共药物反应数据集上进行的,这些数据是从细胞系、患者来源的异种移植物和患者样本中获得的。我们的实验证实早期整合的预测性能最低。总体而言,整合三重损失的架构取得了最佳结果。然而,在统计上,总体上很少观察到差异,但是在方法的平均排名方面,Super.FELT 在交叉验证设置中表现最好,而 Omics Stacking 在外部测试集设置中表现最好。
我们建议研究人员遵循本文中建议的公平比较协议。当面对新数据集时,Super.FELT 在交叉验证设置中是一个不错的选择,而 Omics Stacking 在外部测试集设置中也是如此。尽管算法排名存在趋势,但统计显著性几乎难以观察到。针对该领域的改进的迁移学习方法的未来工作可能会改善外部测试集的情况。所有实验的源代码可在 https://github.com/kramerlab/Multi-Omics_analysis 获得。