IEEE Trans Med Imaging. 2023 Jul;42(7):1932-1943. doi: 10.1109/TMI.2022.3233574. Epub 2023 Jun 30.
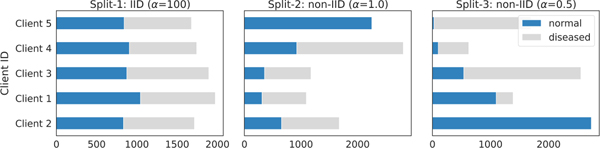
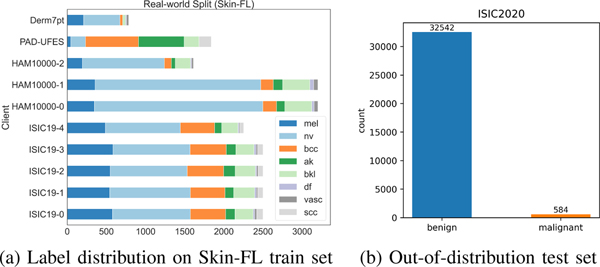
The collection and curation of large-scale medical datasets from multiple institutions is essential for training accurate deep learning models, but privacy concerns often hinder data sharing. Federated learning (FL) is a promising solution that enables privacy-preserving collaborative learning among different institutions, but it generally suffers from performance deterioration due to heterogeneous data distributions and a lack of quality labeled data. In this paper, we present a robust and label-efficient self-supervised FL framework for medical image analysis. Our method introduces a novel Transformer-based self-supervised pre-training paradigm that pre-trains models directly on decentralized target task datasets using masked image modeling, to facilitate more robust representation learning on heterogeneous data and effective knowledge transfer to downstream models. Extensive empirical results on simulated and real-world medical imaging non-IID federated datasets show that masked image modeling with Transformers significantly improves the robustness of models against various degrees of data heterogeneity. Notably, under severe data heterogeneity, our method, without relying on any additional pre-training data, achieves an improvement of 5.06%, 1.53% and 4.58% in test accuracy on retinal, dermatology and chest X-ray classification compared to the supervised baseline with ImageNet pre-training. In addition, we show that our federated self-supervised pre-training methods yield models that generalize better to out-of-distribution data and perform more effectively when fine-tuning with limited labeled data, compared to existing FL algorithms. The code is available at https://github.com/rui-yan/SSL-FL.
从多个机构收集和整理大规模的医疗数据集对于训练准确的深度学习模型至关重要,但隐私问题常常阻碍数据共享。联邦学习(FL)是一种有前途的解决方案,它可以在不同的机构之间实现隐私保护的协作学习,但由于数据分布的异质性和缺乏高质量的标记数据,它通常会受到性能下降的影响。在本文中,我们提出了一种用于医学图像分析的健壮和标签高效的自监督联邦学习框架。我们的方法引入了一种新颖的基于 Transformer 的自监督预训练范例,该范例直接在分散的目标任务数据上使用掩蔽图像建模进行预训练,以促进对异质数据的更健壮的表示学习和有效知识转移到下游模型。在模拟和真实世界的医学成像非 IID 联邦数据集上的广泛实证结果表明,使用 Transformer 的掩蔽图像建模显著提高了模型对各种程度的数据异质性的鲁棒性。值得注意的是,在严重的数据异质性下,我们的方法无需依赖任何额外的预训练数据,与使用 ImageNet 预训练的监督基线相比,在视网膜、皮肤科和胸部 X 射线分类的测试准确性上分别提高了 5.06%、1.53%和 4.58%。此外,我们还表明,与现有的 FL 算法相比,我们的联邦自监督预训练方法产生的模型在对分布外数据的泛化能力更好,并且在使用有限的标记数据进行微调时效果更好。代码可在 https://github.com/rui-yan/SSL-FL 上获得。