Wikle Christopher K, Datta Abhirup, Hari Bhava Vyasa, Boone Edward L, Sahoo Indranil, Kavila Indulekha, Castruccio Stefano, Simmons Susan J, Burr Wesley S, Chang Won
Department of Statistics, University of Missouri, Columbia, Missouri, USA.
Department of Biostatistics, Johns Hopkins University, Baltimore, Maryland, USA.
Environmetrics. 2023 Feb;34(1). doi: 10.1002/env.2772. Epub 2022 Oct 25.
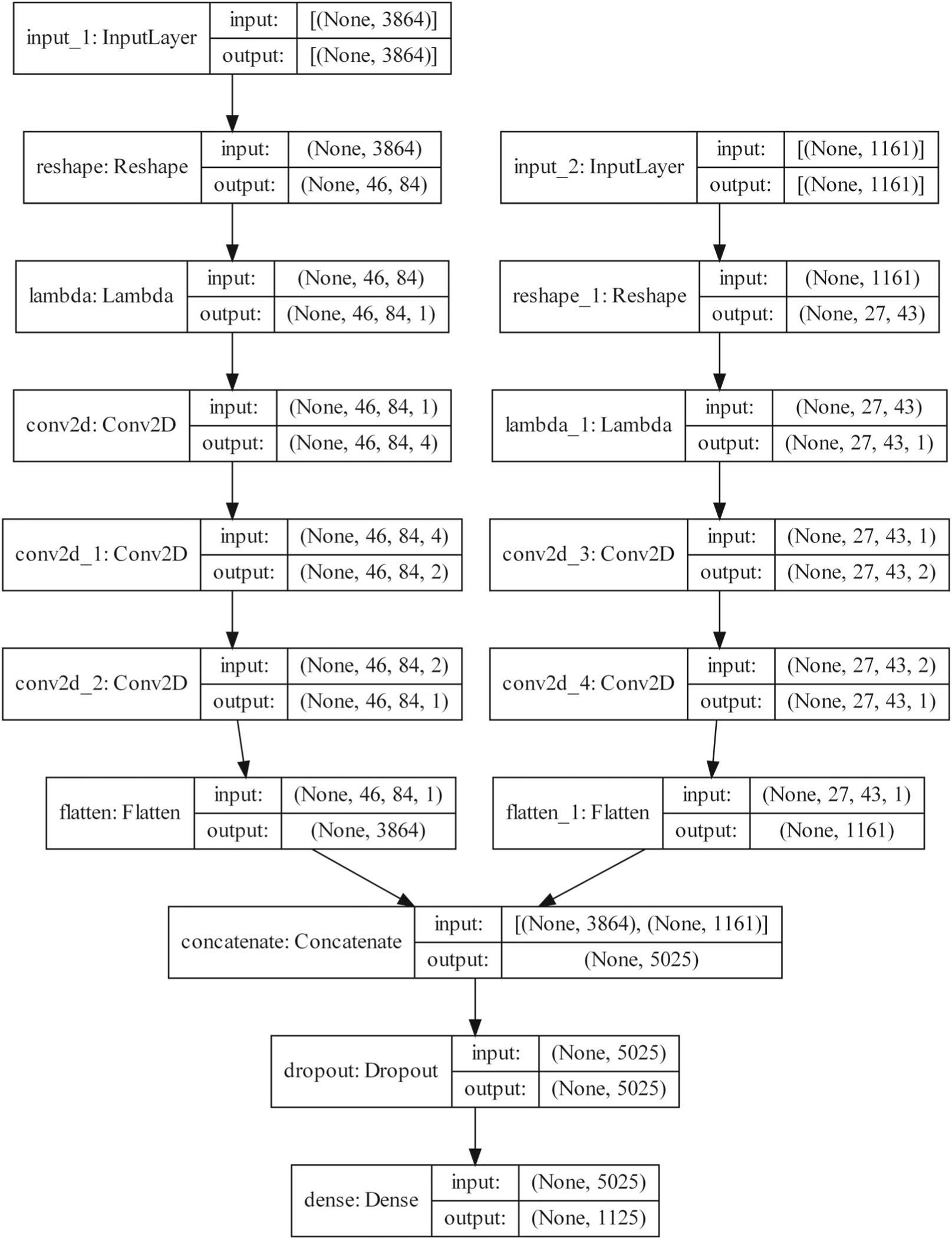
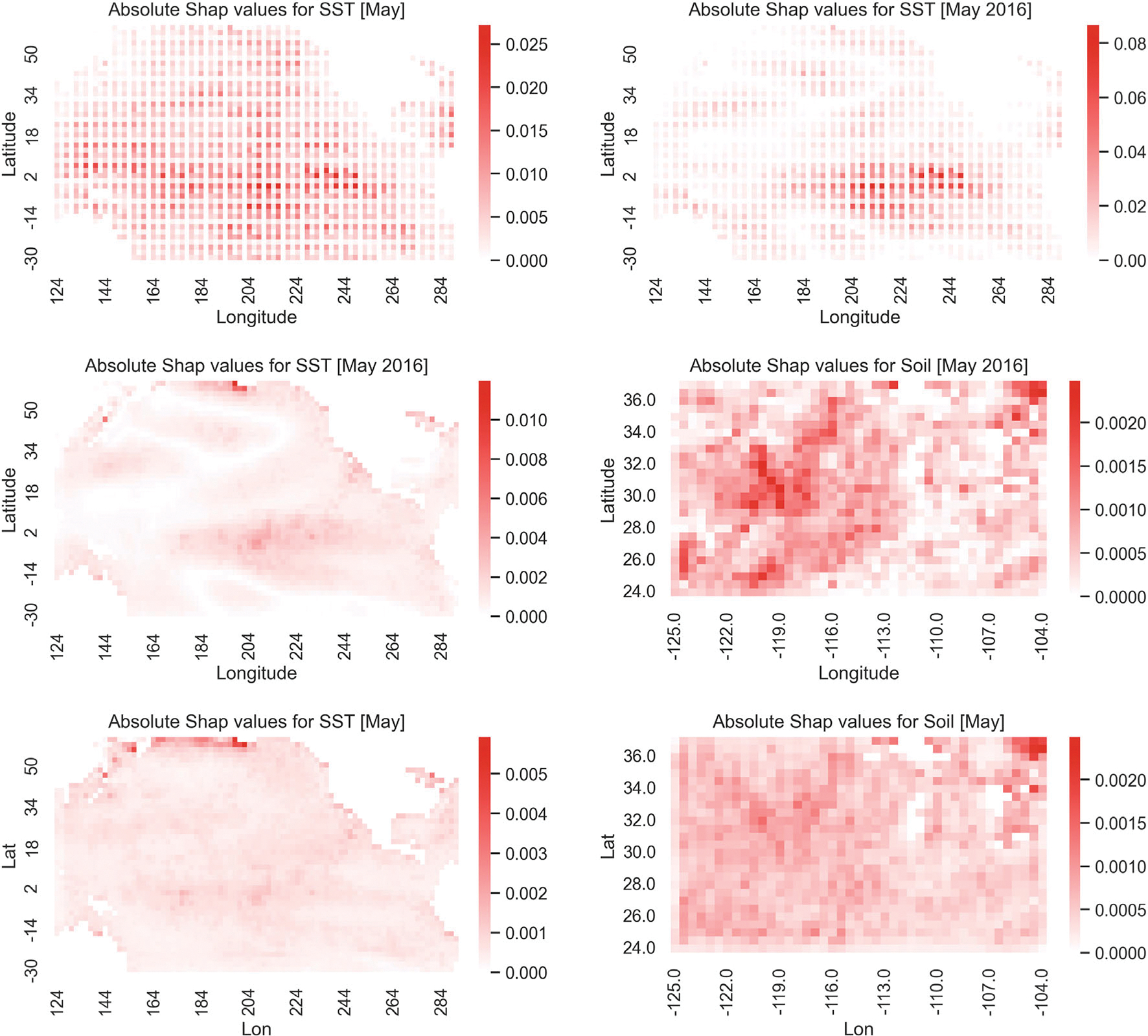
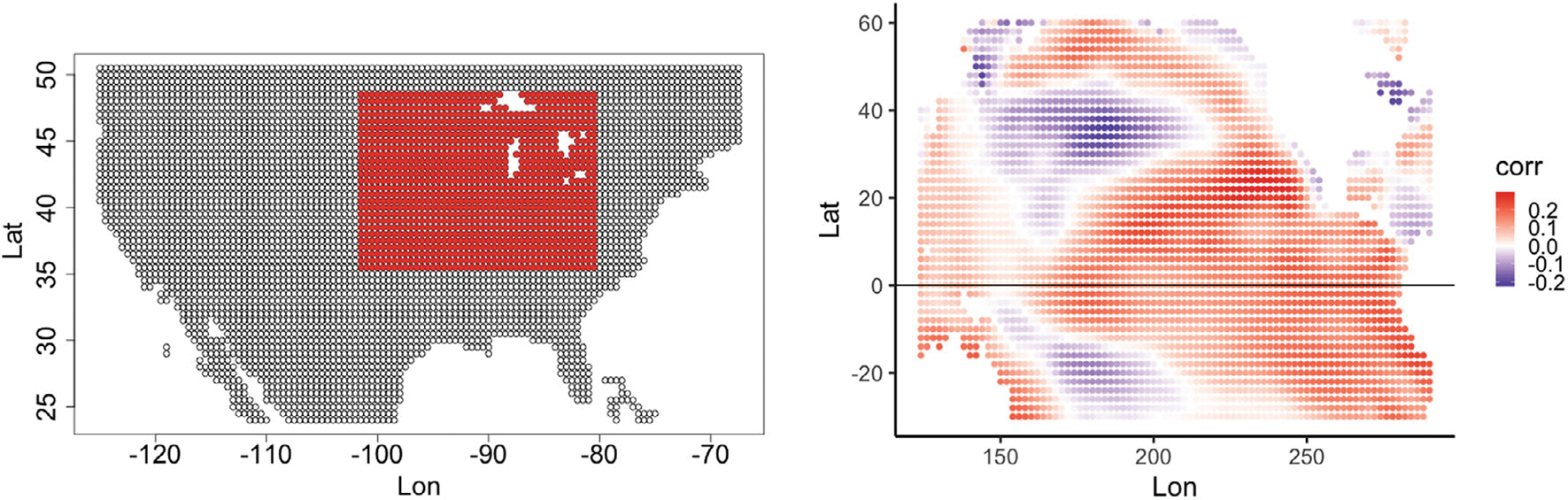
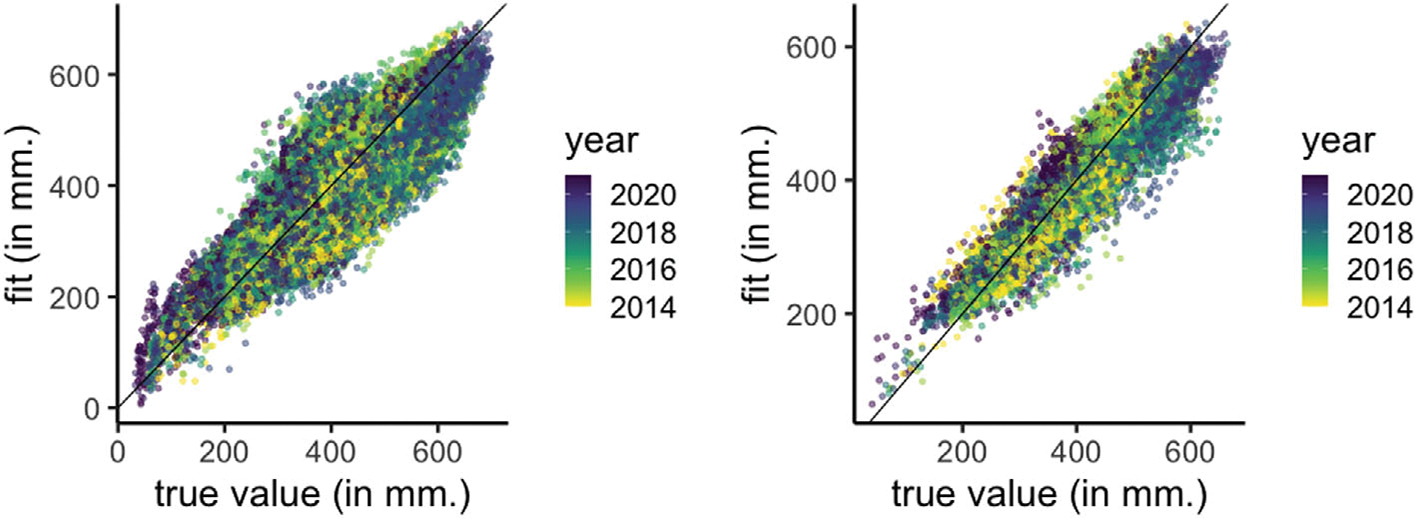
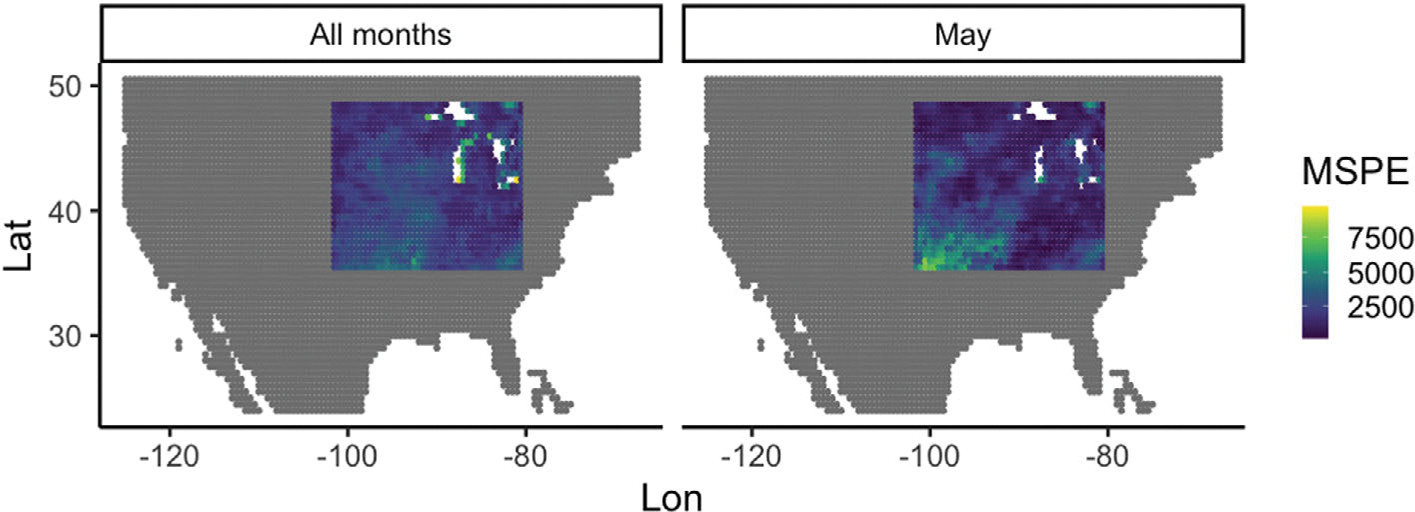
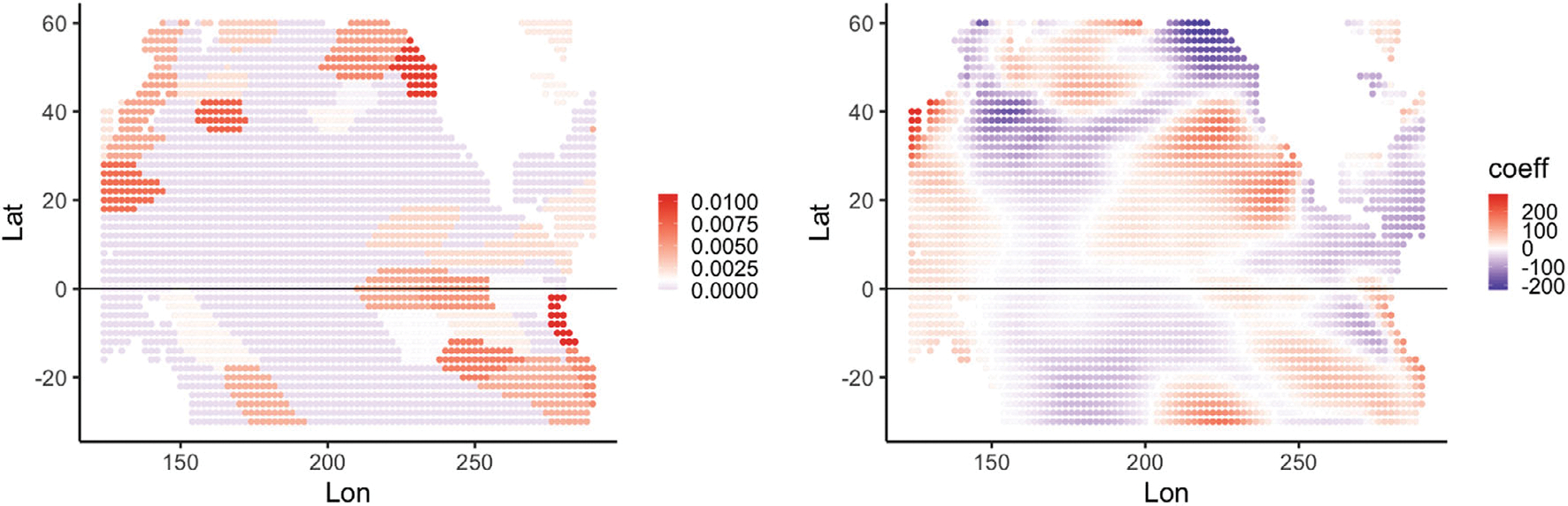
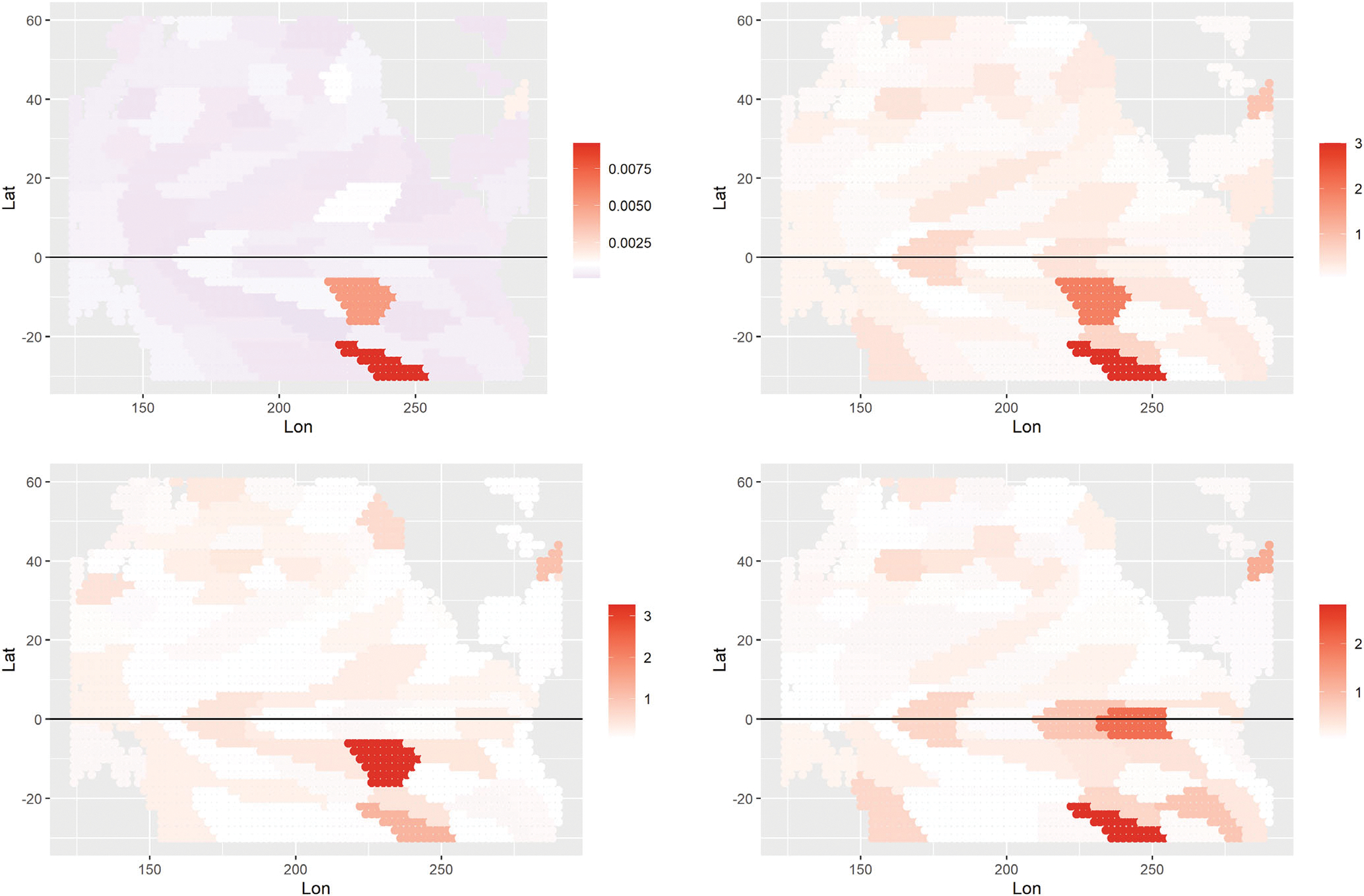
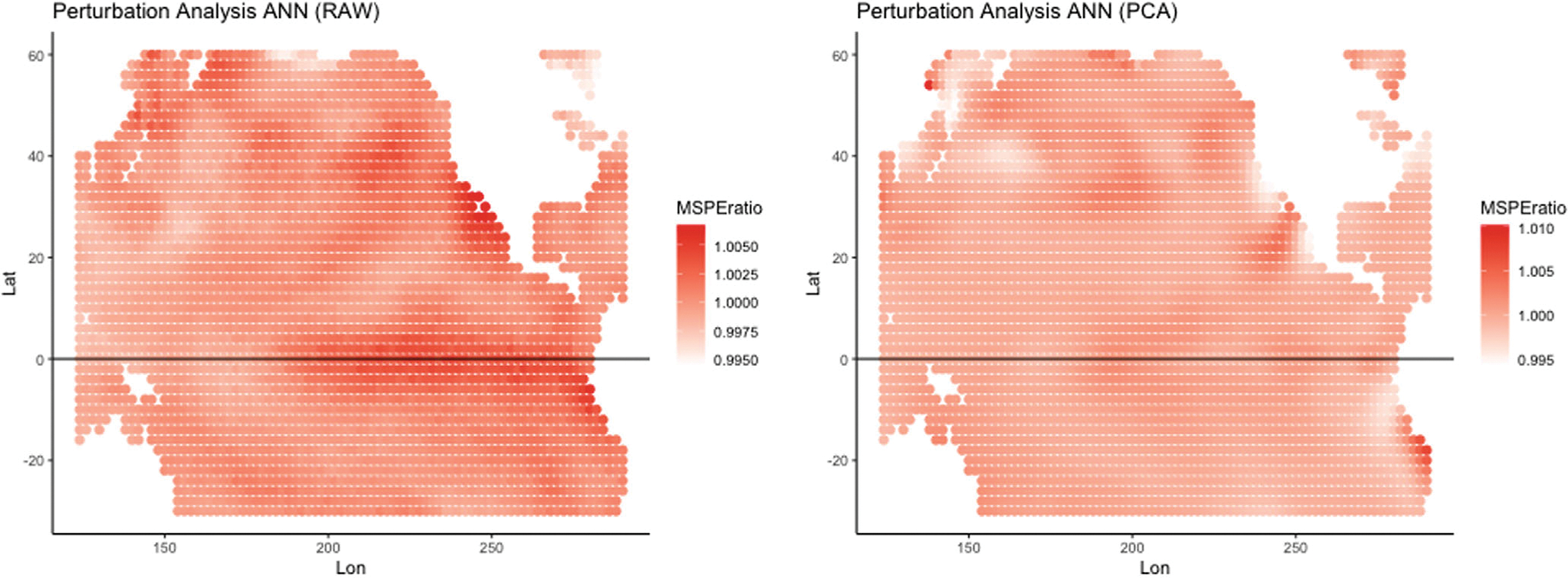
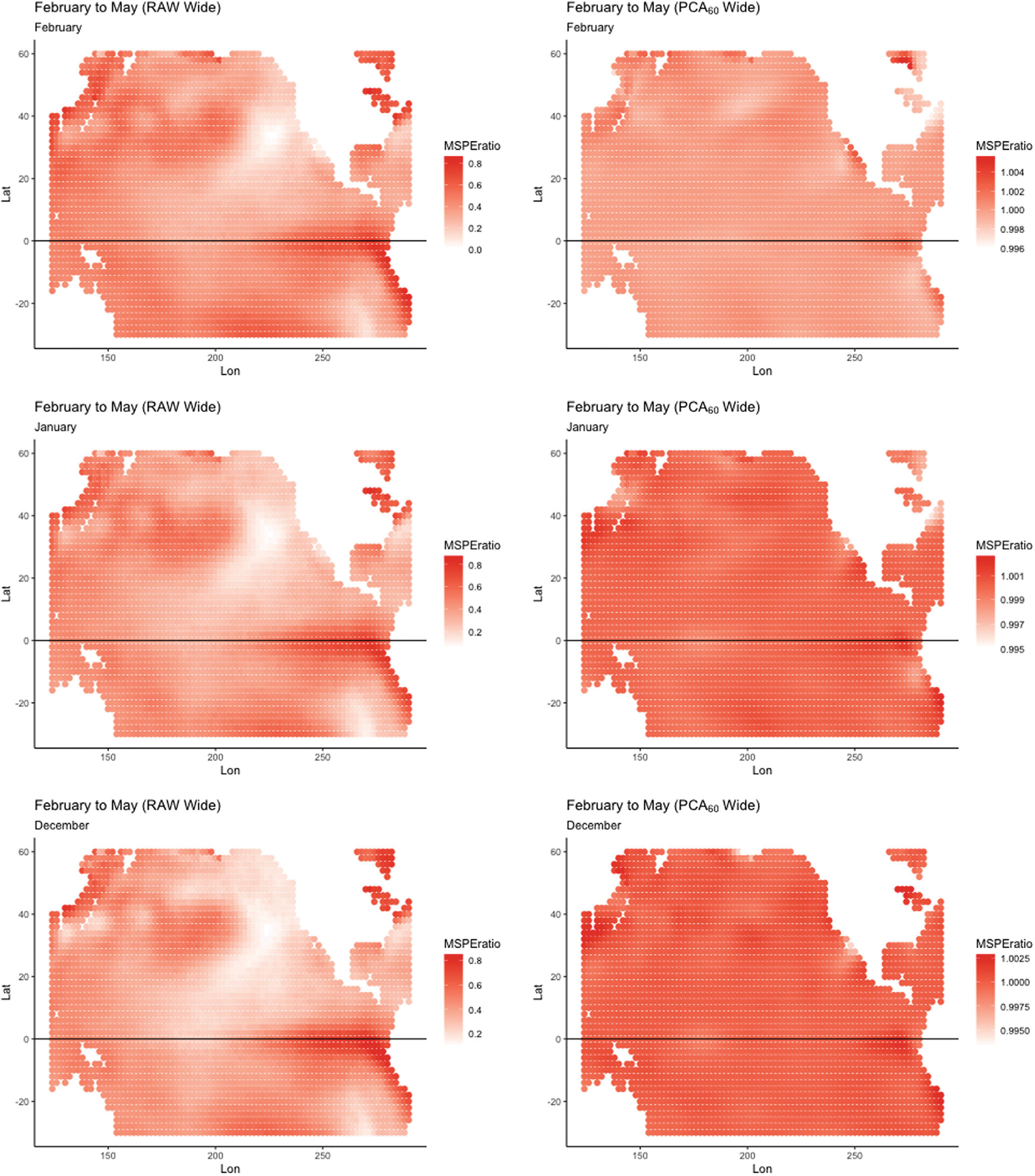
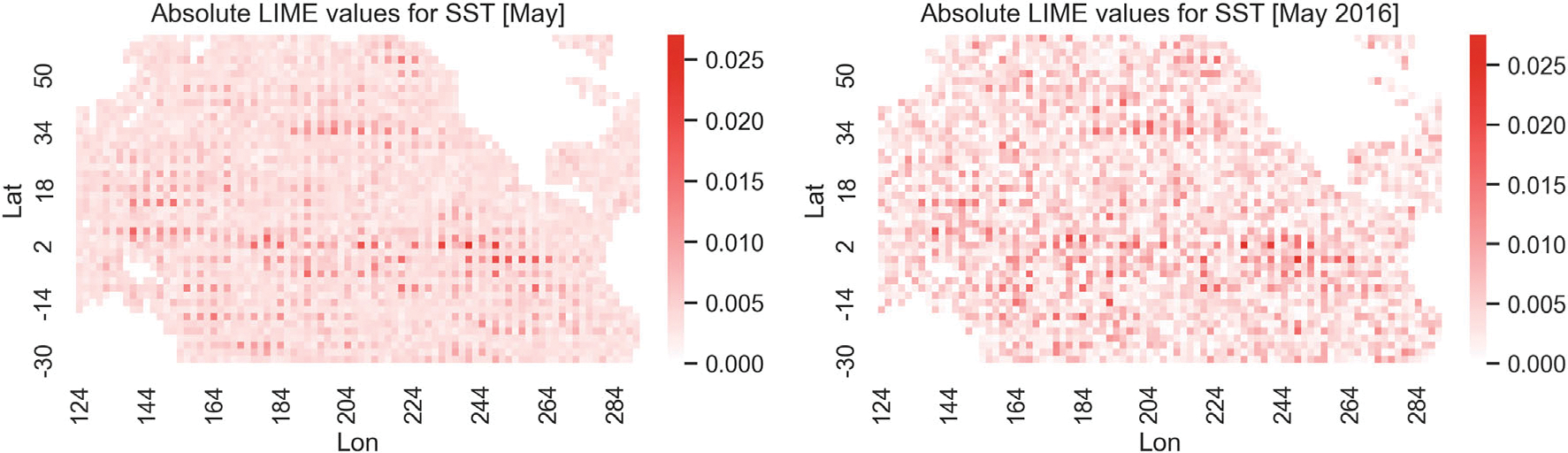
Historically, two primary criticisms statisticians have of machine learning and deep neural models is their lack of uncertainty quantification and the inability to do inference (i.e., to explain what inputs are important). Explainable AI has developed in the last few years as a sub-discipline of computer science and machine learning to mitigate these concerns (as well as concerns of fairness and transparency in deep modeling). In this article, our focus is on explaining which inputs are important in models for predicting environmental data. In particular, we focus on three general methods for explainability that are model agnostic and thus applicable across a breadth of models without internal explainability: "feature shuffling", "interpretable local surrogates", and "occlusion analysis". We describe particular implementations of each of these and illustrate their use with a variety of models, all applied to the problem of long-lead forecasting monthly soil moisture in the North American corn belt given sea surface temperature anomalies in the Pacific Ocean.
从历史上看,统计学家对机器学习和深度神经模型主要有两点批评,一是它们缺乏不确定性量化,二是无法进行推理(即解释哪些输入是重要的)。可解释人工智能在过去几年中作为计算机科学和机器学习的一个子领域得到了发展,以缓解这些问题(以及深度建模中的公平性和透明度问题)。在本文中,我们的重点是解释在预测环境数据的模型中哪些输入是重要的。具体而言,我们关注三种通用的可解释性方法,这些方法与模型无关,因此适用于广泛的、没有内部可解释性的模型:“特征洗牌”、“可解释的局部替代模型”和“遮挡分析”。我们描述了每种方法的具体实现,并通过各种模型展示了它们的应用,所有这些模型都应用于根据太平洋海表面温度异常对北美玉米带月土壤湿度进行长期预测的问题。