Coccomini Davide Alessandro, Caldelli Roberto, Falchi Fabrizio, Gennaro Claudio
Istituto di Scienza e Tecnologie dell'Informazione, 56124 Pisa, Italy.
National Inter-University Consortium for Telecommunications (CNIT), 50134 Florence, Italy.
J Imaging. 2023 Apr 29;9(5):89. doi: 10.3390/jimaging9050089.
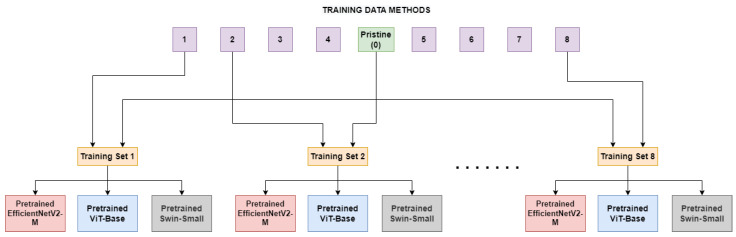
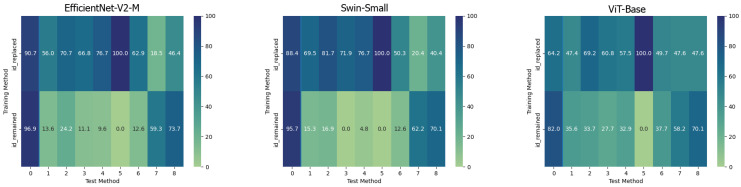
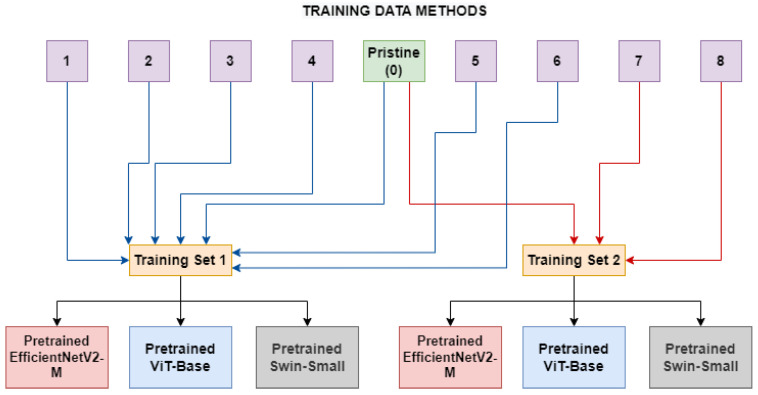
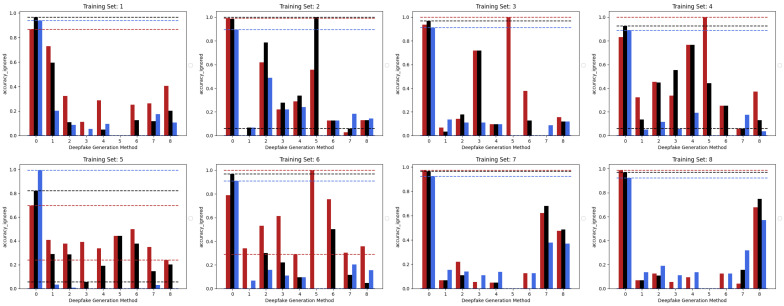
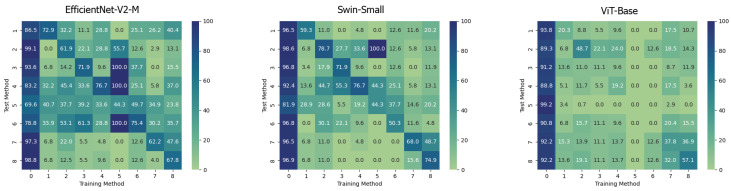
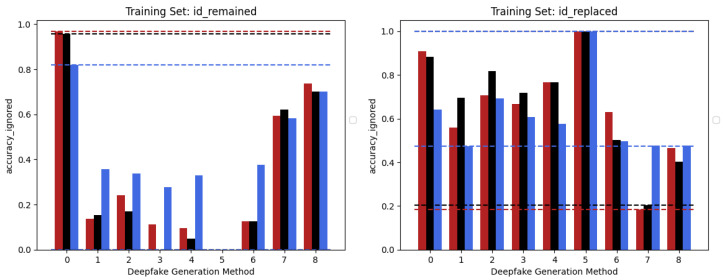
The increasing use of deep learning techniques to manipulate images and videos, commonly referred to as "deepfakes", is making it more challenging to differentiate between real and fake content, while various deepfake detection systems have been developed, they often struggle to detect deepfakes in real-world situations. In particular, these methods are often unable to effectively distinguish images or videos when these are modified using novel techniques which have not been used in the training set. In this study, we carry out an analysis of different deep learning architectures in an attempt to understand which is more capable of better generalizing the concept of deepfake. According to our results, it appears that Convolutional Neural Networks (CNNs) seem to be more capable of storing specific anomalies and thus excel in cases of datasets with a limited number of elements and manipulation methodologies. The Vision Transformer, conversely, is more effective when trained with more varied datasets, achieving more outstanding generalization capabilities than the other methods analysed. Finally, the Swin Transformer appears to be a good alternative for using an attention-based method in a more limited data regime and performs very well in cross-dataset scenarios. All the analysed architectures seem to have a different way to look at deepfakes, but since in a real-world environment the generalization capability is essential, based on the experiments carried out, the attention-based architectures seem to provide superior performances.
深度学习技术越来越多地被用于处理图像和视频,通常被称为“深度伪造”,这使得区分真实内容和虚假内容变得更具挑战性。虽然已经开发了各种深度伪造检测系统,但它们在现实世界的情况下往往难以检测出深度伪造。特别是,当使用训练集中未使用的新技术修改图像或视频时,这些方法通常无法有效地区分。在本研究中,我们对不同的深度学习架构进行了分析,试图了解哪种架构更能更好地概括深度伪造的概念。根据我们的结果,卷积神经网络(CNN)似乎更能够存储特定异常,因此在元素数量有限和操作方法的数据集情况下表现出色。相反,视觉Transformer在使用更多样化的数据集进行训练时更有效,比其他分析方法具有更出色的泛化能力。最后,Swin Transformer似乎是在更有限的数据环境中使用基于注意力的方法的一个很好的选择,并且在跨数据集场景中表现非常出色。所有分析的架构似乎都有不同的方式看待深度伪造,但由于在现实世界环境中泛化能力至关重要,基于所进行的实验,基于注意力的架构似乎提供了卓越的性能。