Department of Computer Science, University of Helsinki, Helsinki, Finland.
Department of Computer Science and Engineering, Indian Institute of Technology Roorkee, Roorkee, India.
Genome Biol. 2023 Jun 9;24(1):136. doi: 10.1186/s13059-023-02968-z.
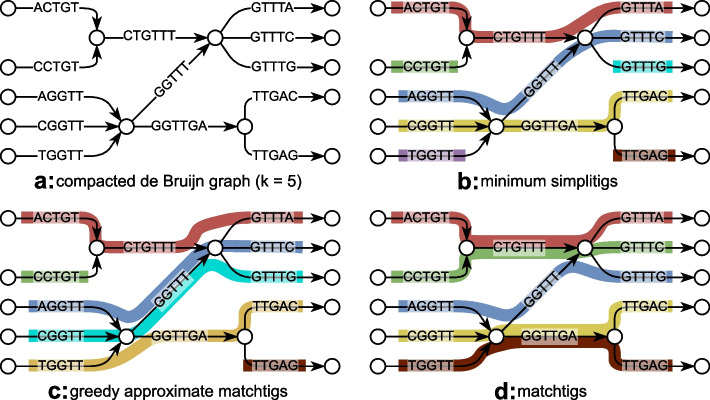
We propose a polynomial algorithm computing a minimum plain-text representation of k-mer sets, as well as an efficient near-minimum greedy heuristic. When compressing read sets of large model organisms or bacterial pangenomes, with only a minor runtime increase, we shrink the representation by up to 59% over unitigs and 26% over previous work. Additionally, the number of strings is decreased by up to 97% over unitigs and 90% over previous work. Finally, a small representation has advantages in downstream applications, as it speeds up SSHash-Lite queries by up to 4.26× over unitigs and 2.10× over previous work.
我们提出了一种多项式算法,用于计算 k-mer 集的最小明文表示,以及一种高效的近似最小贪婪启发式算法。在压缩大型模式生物或细菌泛基因组的读取集时,仅略微增加运行时间,我们将表示缩小了 59%(相对于单元克)和 26%(相对于以前的工作)。此外,与单元克相比,字符串的数量减少了 97%,与以前的工作相比减少了 90%。最后,小的表示在下游应用中具有优势,因为它使 SSHash-Lite 查询的速度提高了 4.26 倍(相对于单元克)和 2.10 倍(相对于以前的工作)。