Department of Information Engineering, University of Brescia, Brescia, Italy.
Department of Molecular and Translational Medicine, University of Brescia, Brescia, Italy.
Sci Rep. 2023 Jul 11;13(1):11238. doi: 10.1038/s41598-023-38186-7.
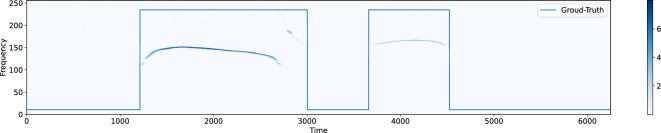
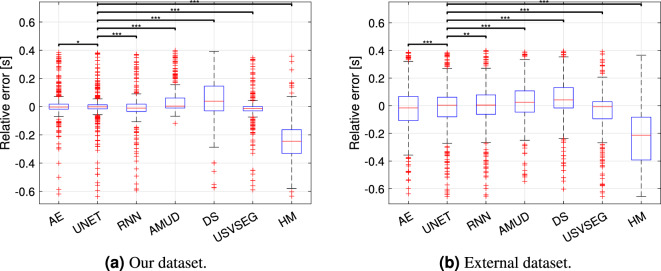
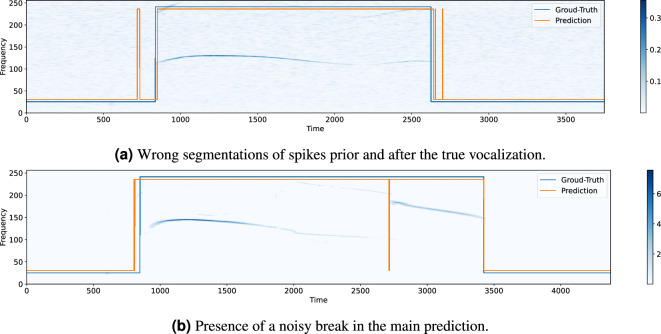
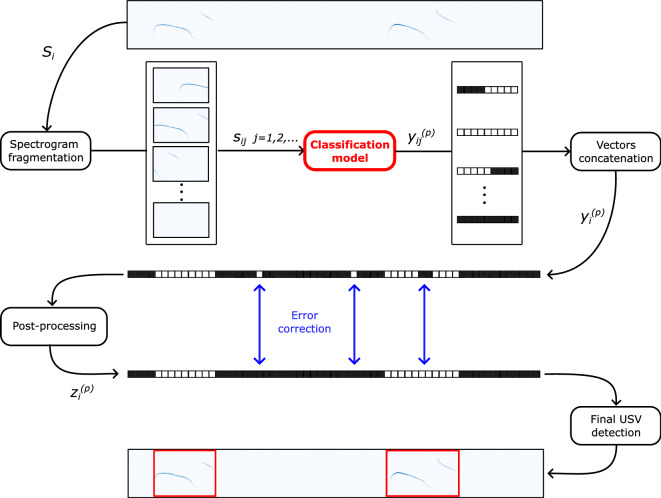
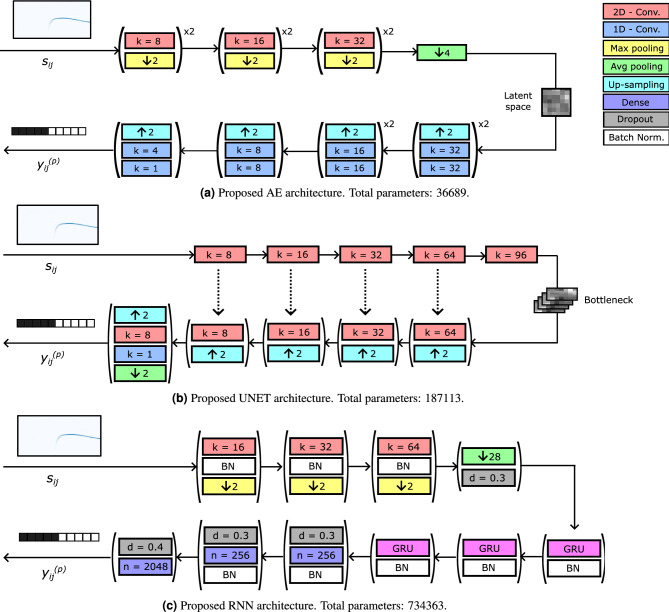
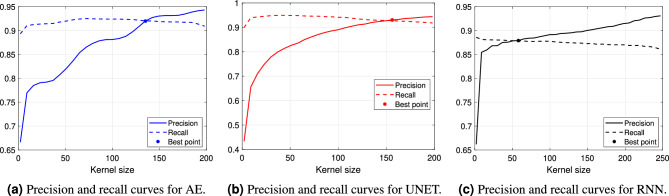
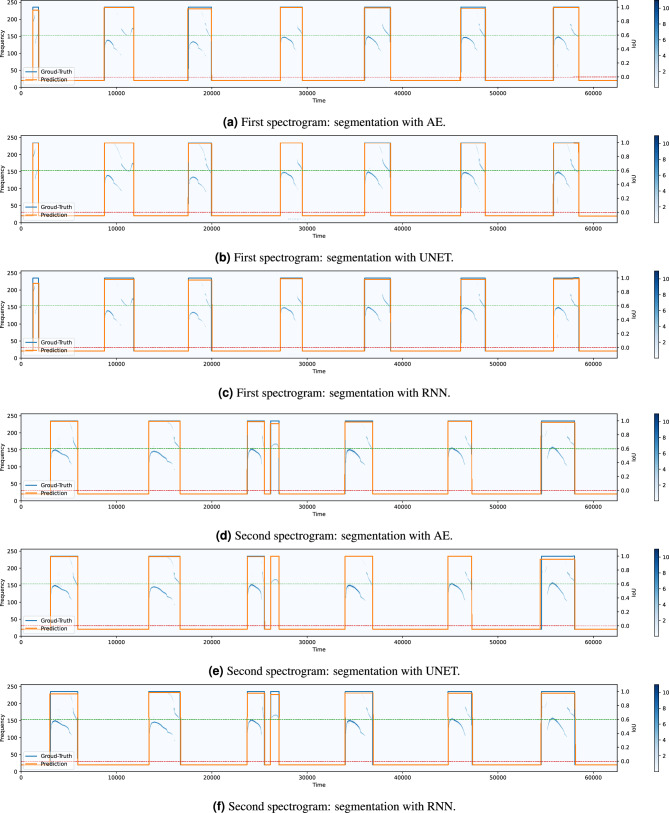
Ultrasonic vocalizations (USVs) analysis represents a fundamental tool to study animal communication. It can be used to perform a behavioral investigation of mice for ethological studies and in the field of neuroscience and neuropharmacology. The USVs are usually recorded with a microphone sensitive to ultrasound frequencies and then processed by specific software, which help the operator to identify and characterize different families of calls. Recently, many automated systems have been proposed for automatically performing both the detection and the classification of the USVs. Of course, the USV segmentation represents the crucial step for the general framework, since the quality of the call processing strictly depends on how accurately the call itself has been previously detected. In this paper, we investigate the performance of three supervised deep learning methods for automated USV segmentation: an Auto-Encoder Neural Network (AE), a U-NET Neural Network (UNET) and a Recurrent Neural Network (RNN). The proposed models receive as input the spectrogram associated with the recorded audio track and return as output the regions in which the USV calls have been detected. To evaluate the performance of the models, we have built a dataset by recording several audio tracks and manually segmenting the corresponding USV spectrograms generated with the Avisoft software, producing in this way the ground-truth (GT) used for training. All three proposed architectures demonstrated precision and recall scores exceeding [Formula: see text], with UNET and AE achieving values above [Formula: see text], surpassing other state-of-the-art methods that were considered for comparison in this study. Additionally, the evaluation was extended to an external dataset, where UNET once again exhibited the highest performance. We suggest that our experimental results may represent a valuable benchmark for future works.
超声发声(USVs)分析是研究动物交流的基本工具。它可用于对老鼠进行行为学研究以及神经科学和神经药理学领域的研究。USVs 通常使用对超声波频率敏感的麦克风进行记录,然后由特定软件进行处理,该软件可以帮助操作人员识别和描述不同类型的叫声。最近,已经提出了许多自动化系统,用于自动执行 USVs 的检测和分类。当然,USV 分割是通用框架的关键步骤,因为叫声处理的质量严格取决于之前如何准确地检测到叫声。在本文中,我们研究了三种用于自动 USV 分割的监督深度学习方法的性能:自动编码器神经网络(AE)、U-NET 神经网络(UNET)和递归神经网络(RNN)。所提出的模型接收与记录的音频轨道相关的频谱图作为输入,并输出已检测到 USV 叫声的区域作为输出。为了评估模型的性能,我们通过录制多个音频轨道并使用 Avisoft 软件手动分割相应的 USV 频谱图构建了一个数据集,从而生成用于训练的真实数据(GT)。所有三种提出的架构都表现出超过 [Formula: see text] 的精确率和召回率,其中 UNET 和 AE 的值超过 [Formula: see text],超过了在本研究中考虑的其他用于比较的最新方法。此外,评估扩展到了外部数据集,其中 UNET 再次表现出最高的性能。我们建议,我们的实验结果可能是未来工作的有价值的基准。