Hanke Paul, Parrello Bruce, Vasieva Olga, Akins Chase, Chlenski Philippe, Babnigg Gyorgy, Henry Chris, Foflonker Fatima, Brettin Thomas, Antonopoulos Dionysios, Stevens Rick, Fonstein Michael
Argonne National Laboratory, 9700 S. Cass Ave, Argonne, IL, 60439, USA.
University of Chicago, 5801 S. Ellis Ave, Chicago, IL, 60637, USA.
Metab Eng Commun. 2023 Jun 16;17:e00225. doi: 10.1016/j.mec.2023.e00225. eCollection 2023 Dec.
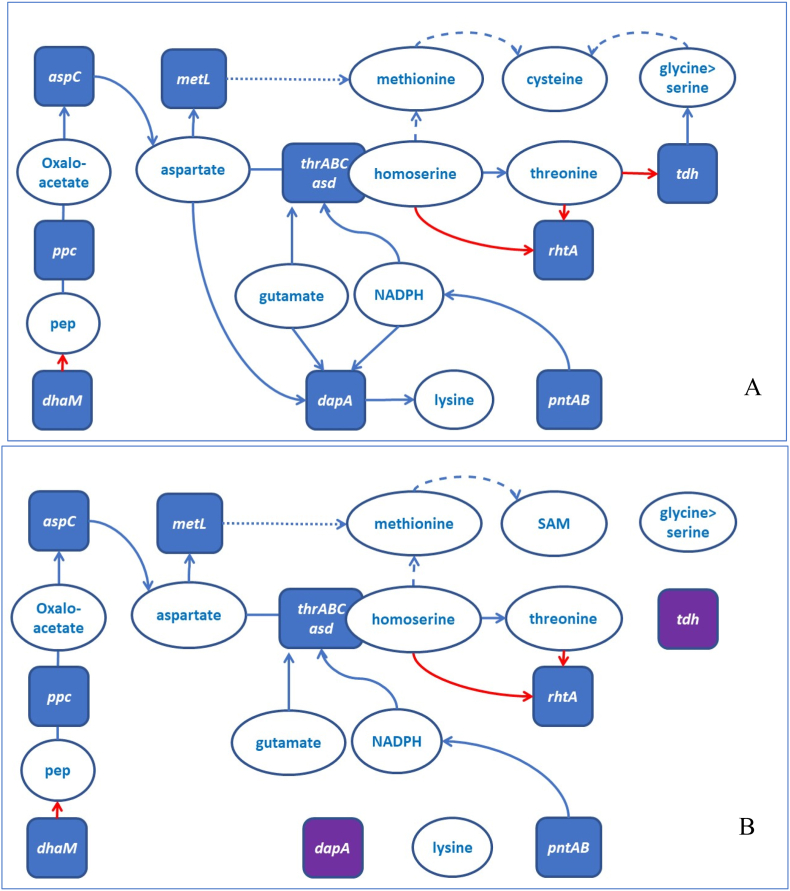
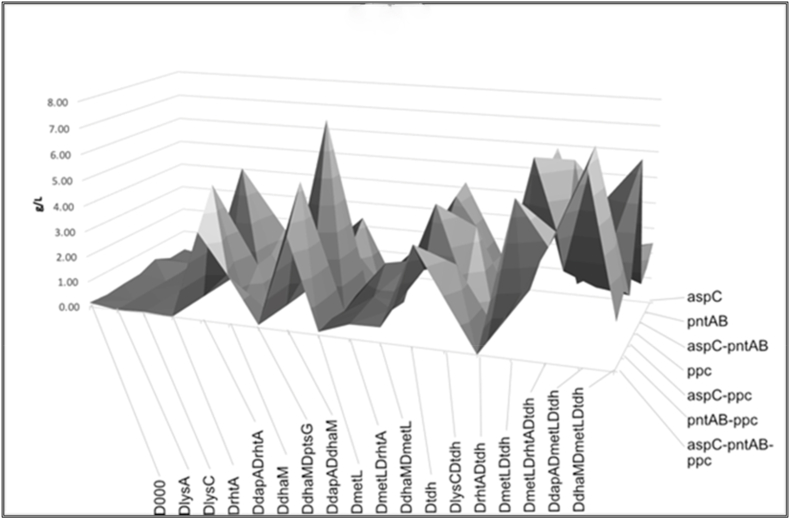
The goal of this study is to develop a general strategy for bacterial engineering using an integrated synthetic biology and machine learning (ML) approach. This strategy was developed in the context of increasing L-threonine production in ATCC 21277. A set of 16 genes was initially selected based on metabolic pathway relevance to threonine biosynthesis and used for combinatorial cloning to construct a set of 385 strains to generate training data (i.e., a range of L-threonine titers linked to each of the specific gene combinations). Hybrid (regression/classification) deep learning (DL) models were developed and used to predict additional gene combinations in subsequent rounds of combinatorial cloning for increased L-threonine production based on the training data. As a result, strains built after just three rounds of iterative combinatorial cloning and model prediction generated higher L-threonine titers (from 2.7 g/L to 8.4 g/L) than those of patented L-threonine strains being used as controls (4-5 g/L). Interesting combinations of genes in L-threonine production included deletions of the , , , and genes as well as overexpression of the , , and genes. Mechanistic analysis of the metabolic system constraints for the best performing constructs offers ways to improve the models by adjusting weights for specific gene combinations. Graph theory analysis of pairwise gene modifications and corresponding levels of L-threonine production also suggests additional rules that can be incorporated into future ML models.
本研究的目标是利用综合合成生物学和机器学习(ML)方法开发一种细菌工程通用策略。该策略是在提高ATCC 21277中L-苏氨酸产量的背景下开发的。最初根据与苏氨酸生物合成的代谢途径相关性选择了一组16个基因,并用于组合克隆,以构建一组385个菌株来生成训练数据(即与每个特定基因组合相关的一系列L-苏氨酸滴度)。开发了混合(回归/分类)深度学习(DL)模型,并用于根据训练数据预测后续几轮组合克隆中用于提高L-苏氨酸产量的其他基因组合。结果,仅经过三轮迭代组合克隆和模型预测构建的菌株产生的L-苏氨酸滴度(从2.7 g/L提高到8.4 g/L)高于用作对照的专利L-苏氨酸菌株(4-5 g/L)。L-苏氨酸生产中有趣的基因组合包括删除 、 、 和 基因以及过表达 、 和 基因。对表现最佳的构建体的代谢系统约束进行机制分析,为通过调整特定基因组合的权重来改进模型提供了方法。对成对基因修饰和相应L-苏氨酸产量水平的图论分析也提出了可以纳入未来ML模型的其他规则。