Department of Psychology, University of California, Berkeley, Berkeley, California, United States of America.
Helen Wills Neuroscience Institute, University of California, Berkeley, Berkeley, California, United States of America.
PLoS Biol. 2023 Jul 17;21(7):e3002201. doi: 10.1371/journal.pbio.3002201. eCollection 2023 Jul.
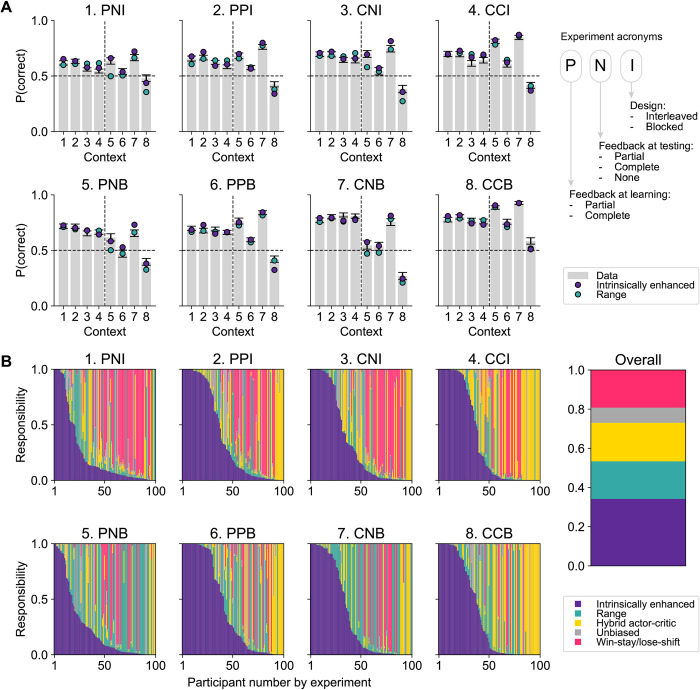
When observing the outcome of a choice, people are sensitive to the choice's context, such that the experienced value of an option depends on the alternatives: getting $1 when the possibilities were 0 or 1 feels much better than when the possibilities were 1 or 10. Context-sensitive valuation has been documented within reinforcement learning (RL) tasks, in which values are learned from experience through trial and error. Range adaptation, wherein options are rescaled according to the range of values yielded by available options, has been proposed to account for this phenomenon. However, we propose that other mechanisms-reflecting a different theoretical viewpoint-may also explain this phenomenon. Specifically, we theorize that internally defined goals play a crucial role in shaping the subjective value attributed to any given option. Motivated by this theory, we develop a new "intrinsically enhanced" RL model, which combines extrinsically provided rewards with internally generated signals of goal achievement as a teaching signal. Across 7 different studies (including previously published data sets as well as a novel, preregistered experiment with replication and control studies), we show that the intrinsically enhanced model can explain context-sensitive valuation as well as, or better than, range adaptation. Our findings indicate a more prominent role of intrinsic, goal-dependent rewards than previously recognized within formal models of human RL. By integrating internally generated signals of reward, standard RL theories should better account for human behavior, including context-sensitive valuation and beyond.
当观察一个选择的结果时,人们对选择的背景很敏感,以至于一个选项的体验价值取决于可供选择的选项:当可能性为 0 或 1 时获得 1 美元的感觉要好得多,而当可能性为 1 或 10 时则要好得多。强化学习 (RL) 任务中已经记录了基于上下文的估值,其中通过反复试验从经验中学习价值。范围自适应(range adaptation),其中根据可用选项产生的价值范围对选项进行重新缩放,已被提议用于解释这种现象。然而,我们提出,其他机制——反映了不同的理论观点——也可能解释这种现象。具体来说,我们推测内部定义的目标在塑造赋予任何给定选项的主观价值方面起着关键作用。受此理论的启发,我们开发了一种新的“内在增强”RL 模型,该模型将外部提供的奖励与内部产生的目标达成信号作为教学信号相结合。在 7 项不同的研究(包括以前发表的数据以及一项具有复制和对照研究的新颖预注册实验)中,我们表明,内在增强模型可以解释基于上下文的估值,以及范围自适应,或者更好。我们的发现表明,内在的、依赖于目标的奖励在人类 RL 的正式模型中比以前认识到的更为重要。通过整合内部产生的奖励信号,标准的 RL 理论应该更好地解释人类行为,包括基于上下文的估值等。