Meo Sultan Ayoub, Al-Masri Abeer A, Alotaibi Metib, Meo Muhammad Zain Sultan, Meo Muhammad Omair Sultan
Department of Physiology, College of Medicine, King Saud University, Riyadh 11461, Saudi Arabia.
University Diabetes Unit, Department of Medicine, College of Medicine, King Saud University, Riyadh 11461, Saudi Arabia.
Healthcare (Basel). 2023 Jul 17;11(14):2046. doi: 10.3390/healthcare11142046.
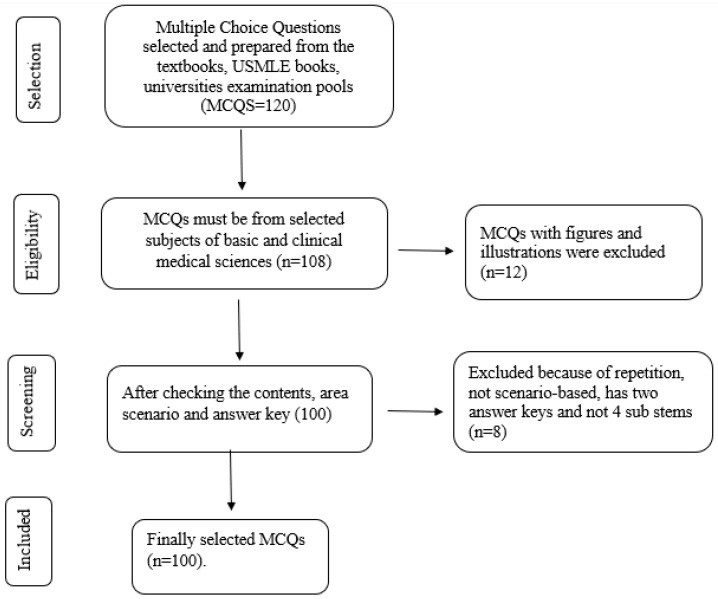
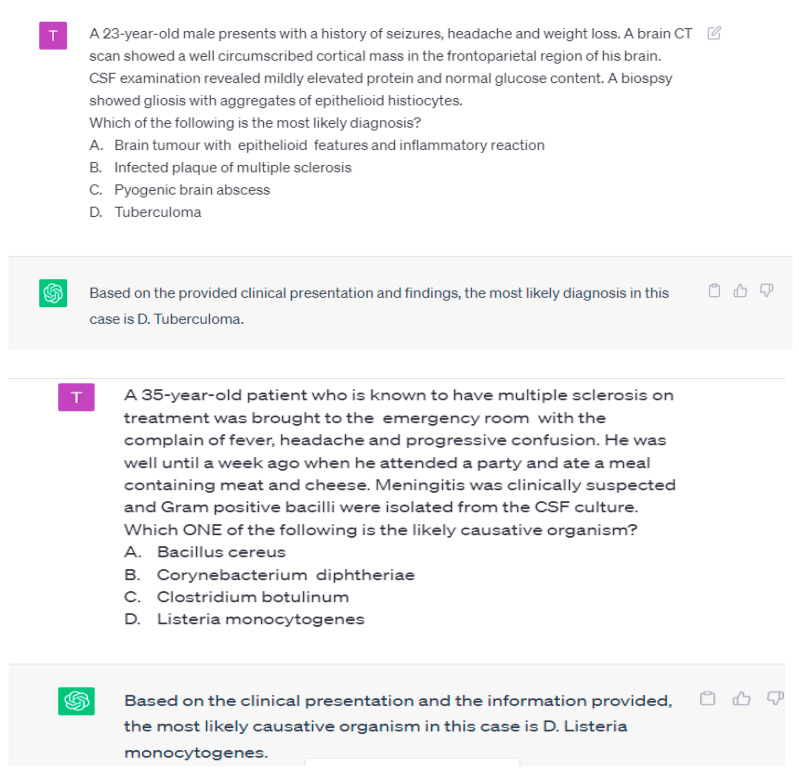
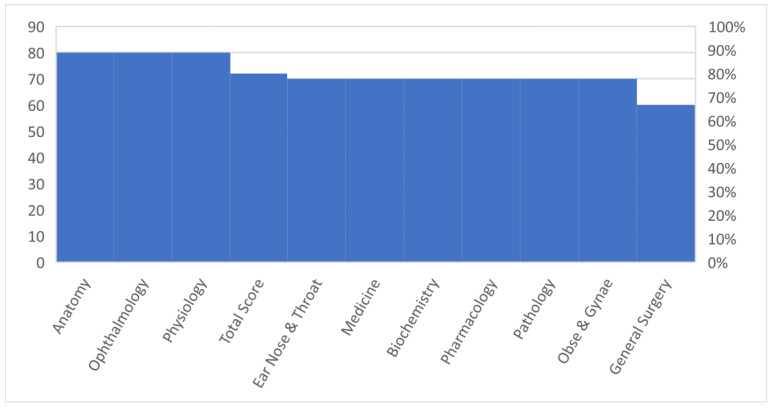
The Chatbot Generative Pre-Trained Transformer (ChatGPT) has garnered great attention from the public, academicians and science communities. It responds with appropriate and articulate answers and explanations across various disciplines. For the use of ChatGPT in education, research and healthcare, different perspectives exist with some level of ambiguity around its acceptability and ideal uses. However, the literature is acutely lacking in establishing a link to assess the intellectual levels of ChatGPT in the medical sciences. Therefore, the present study aimed to investigate the knowledge level of ChatGPT in medical education both in basic and clinical medical sciences, multiple-choice question (MCQs) examination-based performance and its impact on the medical examination system. In this study, initially, a subject-wise question bank was established with a pool of multiple-choice questions (MCQs) from various medical textbooks and university examination pools. The research team members carefully reviewed the MCQ contents and ensured that the MCQs were relevant to the subject's contents. Each question was scenario-based with four sub-stems and had a single correct answer. In this study, 100 MCQs in various disciplines, including basic medical sciences (50 MCQs) and clinical medical sciences (50 MCQs), were randomly selected from the MCQ bank. The MCQs were manually entered one by one, and a fresh ChatGPT session was started for each entry to avoid memory retention bias. The task was given to ChatGPT to assess the response and knowledge level of ChatGPT. The first response obtained was taken as the final response. Based on a pre-determined answer key, scoring was made on a scale of 0 to 1, with zero representing incorrect and one representing the correct answer. The results revealed that out of 100 MCQs in various disciplines of basic and clinical medical sciences, ChatGPT attempted all the MCQs and obtained 37/50 (74%) marks in basic medical sciences and 35/50 (70%) marks in clinical medical sciences, with an overall score of 72/100 (72%) in both basic and clinical medical sciences. It is concluded that ChatGPT obtained a satisfactory score in both basic and clinical medical sciences subjects and demonstrated a degree of understanding and explanation. This study's findings suggest that ChatGPT may be able to assist medical students and faculty in medical education settings since it has potential as an innovation in the framework of medical sciences and education.
聊天机器人生成式预训练变换器(ChatGPT)已引起公众、院士和科学界的极大关注。它能针对各个学科给出恰当且清晰的答案和解释。对于ChatGPT在教育、研究和医疗保健领域的应用,存在不同观点,其可接受性和理想用途在一定程度上存在模糊性。然而,目前的文献严重缺乏对ChatGPT在医学领域知识水平评估的相关联系。因此,本研究旨在调查ChatGPT在基础医学和临床医学教育方面的知识水平、基于多项选择题(MCQ)考试的表现及其对医学考试系统的影响。在本研究中,首先,依据来自各种医学教科书和大学考试题库的多项选择题,建立了一个按学科分类的题库。研究团队成员仔细审查了MCQ内容,并确保这些题目与学科内容相关。每个问题都基于情景,有四个子问题,且只有一个正确答案。在本研究中,从题库中随机选取了100道不同学科的MCQ,包括基础医学(50道题)和临床医学(50道题)。这些MCQ被逐一手动输入,并且为每个输入开启一个新的ChatGPT会话,以避免记忆保留偏差。将任务交给ChatGPT以评估其回答和知识水平。获得的第一个回答被视为最终回答。根据预先确定的答案键,评分范围为0到1,0表示错误答案,1表示正确答案。结果显示,在基础医学和临床医学各学科的100道MCQ中,ChatGPT尝试了所有题目,在基础医学中获得37/50(74%)的分数,在临床医学中获得35/50(70%)的分数,基础医学和临床医学的总体分数为72/100(72%)。研究得出结论,ChatGPT在基础医学和临床医学科目中都获得了令人满意的分数,并展现出一定程度的理解和解释能力。本研究结果表明,ChatGPT在医学教育环境中可能能够帮助医学生和教师,因为它在医学科学和教育框架中具有作为一项创新的潜力。