Warkentin Coby, O'Connell Michael J, Lee Donghyung
Department of Statistics, Miami University, Oxford, OH 45056, United States.
InfoWorks, Inc., Nashville, TN 37205, United States.
Bioinform Adv. 2023 Aug 1;3(1):vbad100. doi: 10.1093/bioadv/vbad100. eCollection 2023.
The International Mouse Phenotyping Consortium (IMPC) is striving to build a comprehensive functional catalog of mammalian protein-coding genes by systematically producing and phenotyping gene-knockout mice for almost every protein-coding gene in the mouse genome and by testing associations between gene loss-of-function and phenotype. To date, the IMPC has identified over 90 000 gene-phenotype associations, but many phenotypes have not yet been measured for each gene, resulting in largely incomplete data; ∼75.6% of association summary statistics are still missing in the latest IMPC summary statistics dataset (IMPC release version 16).
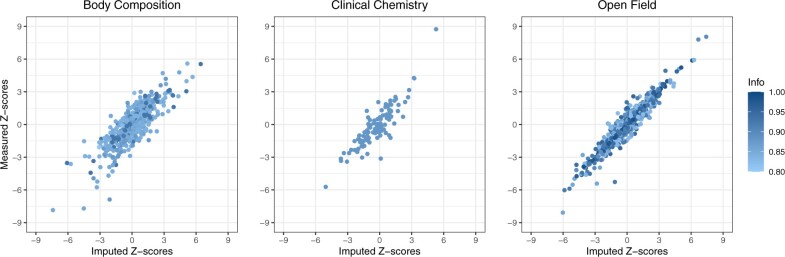
To overcome these challenges, we propose KOMPUTE, a novel method for imputing missing summary statistics in the IMPC dataset. Using conditional distribution properties of multivariate normal, KOMPUTE estimates the association Z-scores of unmeasured phenotypes for a particular gene as a conditional expectation given the Z-scores of measured phenotypes. Our evaluation of the method using simulated and real-world datasets demonstrates its superiority over the singular value decomposition matrix completion method in various scenarios.
An R package for KOMPUTE is publicly available at https://github.com/statsleelab/kompute, along with usage examples and results for different phenotype domains at https://statsleelab.github.io/komputeExamples.
国际小鼠表型分析联盟(IMPC)正致力于通过系统地培育和分析小鼠基因组中几乎每个蛋白质编码基因的基因敲除小鼠,并测试基因功能丧失与表型之间的关联,构建一个全面的哺乳动物蛋白质编码基因功能目录。到目前为止,IMPC已经确定了超过90000个基因-表型关联,但每个基因的许多表型尚未测量,导致数据在很大程度上不完整;在最新的IMPC汇总统计数据集中(IMPC发布版本16),约75.6%的关联汇总统计数据仍然缺失。
为了克服这些挑战,我们提出了KOMPUTE,这是一种用于估算IMPC数据集中缺失汇总统计数据的新方法。利用多元正态分布的条件分布特性,KOMPUTE将特定基因未测量表型的关联Z分数估计为给定测量表型Z分数的条件期望。我们使用模拟和真实数据集对该方法进行的评估表明,在各种情况下,它都优于奇异值分解矩阵补全方法。