Lee Hong-Yu, Li Yung-Hui, Lee Ting-Hsuan, Aslam Muhammad Saqlain
Department of Computer Science and Information Engineering, National Central University, Taoyuan 32001, Taiwan.
AI Research Center, Hon Hai Research Institute, Taipei 114699, Taiwan.
Sensors (Basel). 2023 Aug 1;23(15):6858. doi: 10.3390/s23156858.
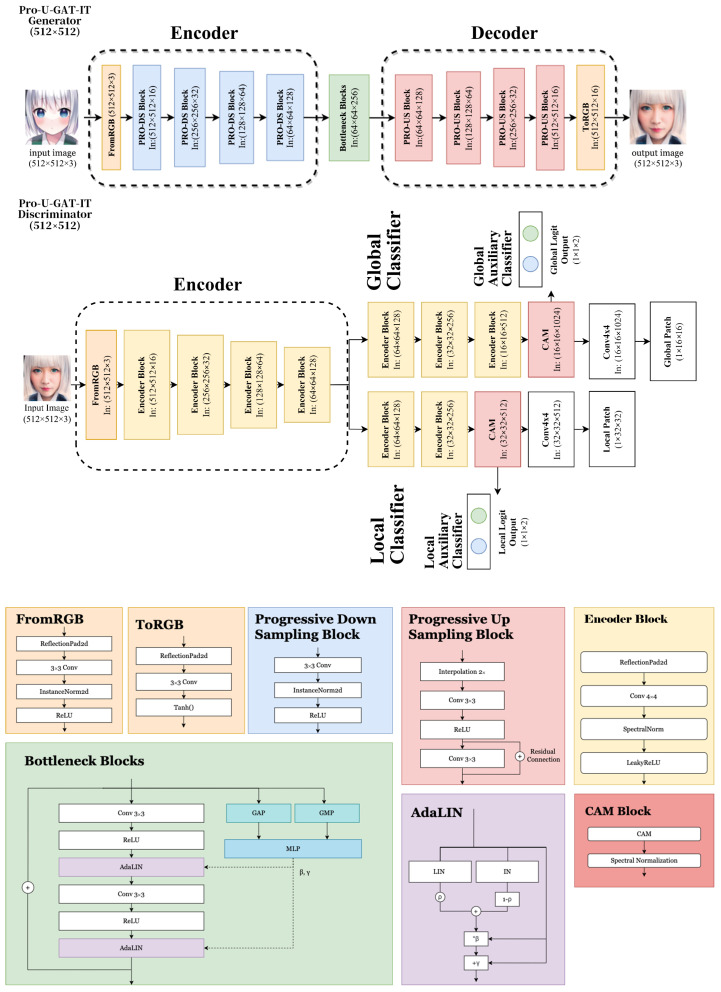
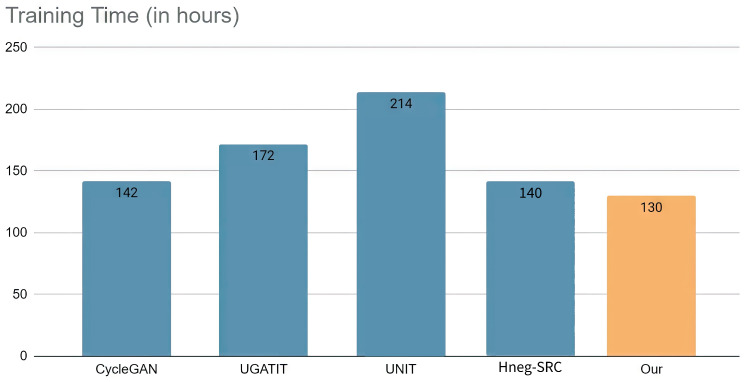
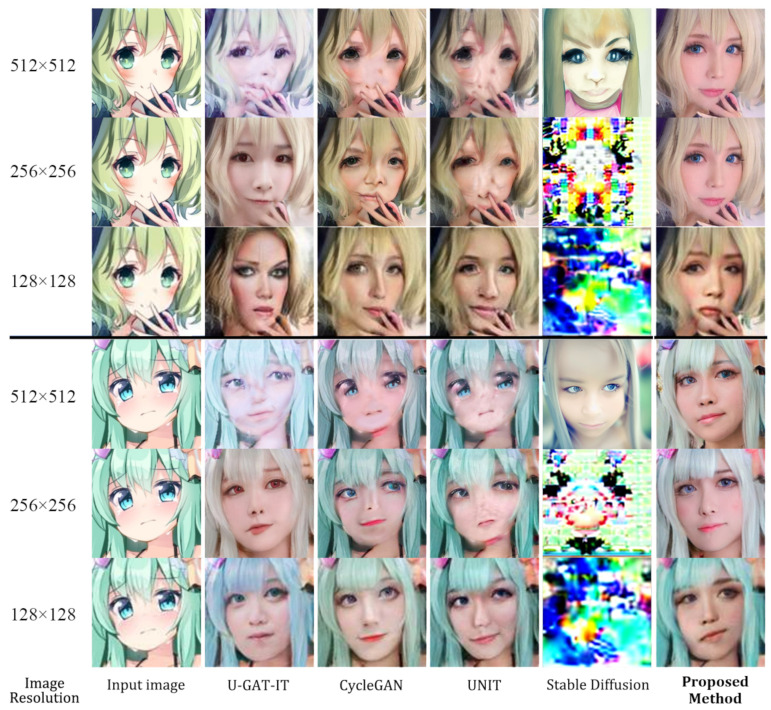
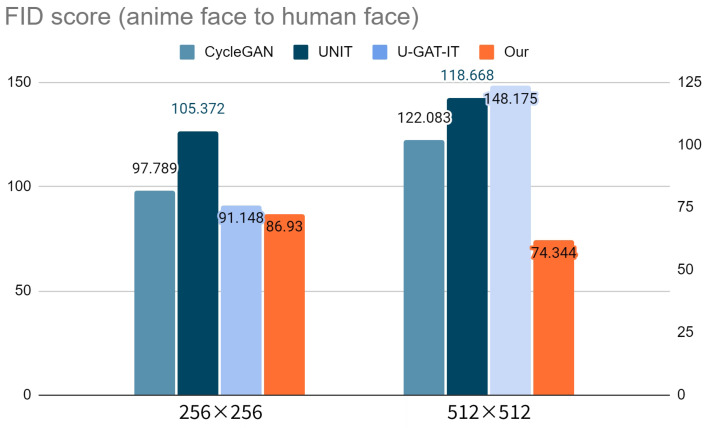
Unsupervised image-to-image translation has received considerable attention due to the recent remarkable advancements in generative adversarial networks (GANs). In image-to-image translation, state-of-the-art methods use unpaired image data to learn mappings between the source and target domains. However, despite their promising results, existing approaches often fail in challenging conditions, particularly when images have various target instances and a translation task involves significant transitions in shape and visual artifacts when translating low-level information rather than high-level semantics. To tackle the problem, we propose a novel framework called Progressive Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization (PRO-U-GAT-IT) for the unsupervised image-to-image translation task. In contrast to existing attention-based models that fail to handle geometric transitions between the source and target domains, our model can translate images requiring extensive and holistic changes in shape. Experimental results show the superiority of the proposed approach compared to the existing state-of-the-art models on different datasets.
由于生成对抗网络(GAN)最近取得了显著进展,无监督图像到图像的翻译受到了广泛关注。在图像到图像的翻译中,当前的先进方法使用未配对的图像数据来学习源域和目标域之间的映射。然而,尽管取得了令人鼓舞的成果,但现有方法在具有挑战性的条件下往往会失败,特别是当图像有各种目标实例,并且在翻译低级信息而非高级语义时,翻译任务涉及形状和视觉伪像的显著变化。为了解决这个问题,我们提出了一种新颖的框架,称为具有自适应层实例归一化的渐进式无监督生成注意力网络(PRO-U-GAT-IT),用于无监督图像到图像的翻译任务。与现有的无法处理源域和目标域之间几何转换的基于注意力的模型不同,我们的模型可以翻译需要在形状上进行广泛和整体变化的图像。实验结果表明,与现有最先进的模型相比,该方法在不同数据集上具有优越性。