Hoover Jacob Louis, Sonderegger Morgan, Piantadosi Steven T, O'Donnell Timothy J
McGill University, Montréal, Canada.
Mila Québec AI Institute, Montréal, Canada.
Open Mind (Camb). 2023 Jul 21;7:350-391. doi: 10.1162/opmi_a_00086. eCollection 2023.
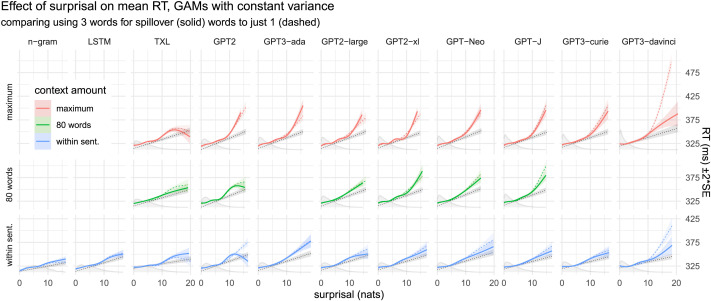
Words that are more surprising given context take longer to process. However, no incremental parsing algorithm has been shown to directly predict this phenomenon. In this work, we focus on a class of algorithms whose runtime does naturally scale in surprisal-those that involve repeatedly sampling from the prior. Our first contribution is to show that simple examples of such algorithms predict runtime to increase superlinearly with surprisal, and also predict variance in runtime to increase. These two predictions stand in contrast with literature on surprisal theory (Hale, 2001; Levy, 2008a) which assumes that the expected processing cost increases linearly with surprisal, and makes no prediction about variance. In the second part of this paper, we conduct an empirical study of the relationship between surprisal and reading time, using a collection of modern language models to estimate surprisal. We find that with better language models, reading time increases superlinearly in surprisal, and also that variance increases. These results are consistent with the predictions of sampling-based algorithms.
在给定语境下更令人惊讶的词汇需要更长时间来处理。然而,尚未有增量解析算法被证明能直接预测这一现象。在这项工作中,我们关注一类算法,其运行时自然地随意外性而扩展,即那些涉及从先验中反复采样的算法。我们的第一个贡献是表明,这类算法的简单示例预测运行时会随意外性超线性增加,并且还预测运行时的方差会增加。这两个预测与意外性理论的文献(黑尔,2001年;利维,2008年a)形成对比,后者假设预期处理成本随意外性线性增加,并且对方差没有预测。在本文的第二部分,我们使用一组现代语言模型来估计意外性,对意外性与阅读时间之间的关系进行了实证研究。我们发现,使用更好的语言模型时,阅读时间随意外性超线性增加,并且方差也增加。这些结果与基于采样的算法的预测一致。