Department of Nephrology, Zhongshan Hospital, Fudan University, Shanghai Clinical Research Center for Kidney Disease, Shanghai Medical Center of Kidney, Shanghai Institute of Kidney and Dialysis, Shanghai Key Laboratory of Kidney and Blood Purification, Hemodialysis Quality Control Center of Shanghai, Shanghai, China.
School of Computer Science & Information Engineering, Shanghai Institute of Technology, Shanghai, China.
BMC Med Inform Decis Mak. 2023 Aug 31;23(1):173. doi: 10.1186/s12911-023-02269-2.
Chronic kidney disease (CKD) is a global public health concern. Therefore, to provide timely intervention for non-hospitalized high-risk patients and rationally allocate limited clinical resources is important to mine the key factors when designing a CKD prediction model.
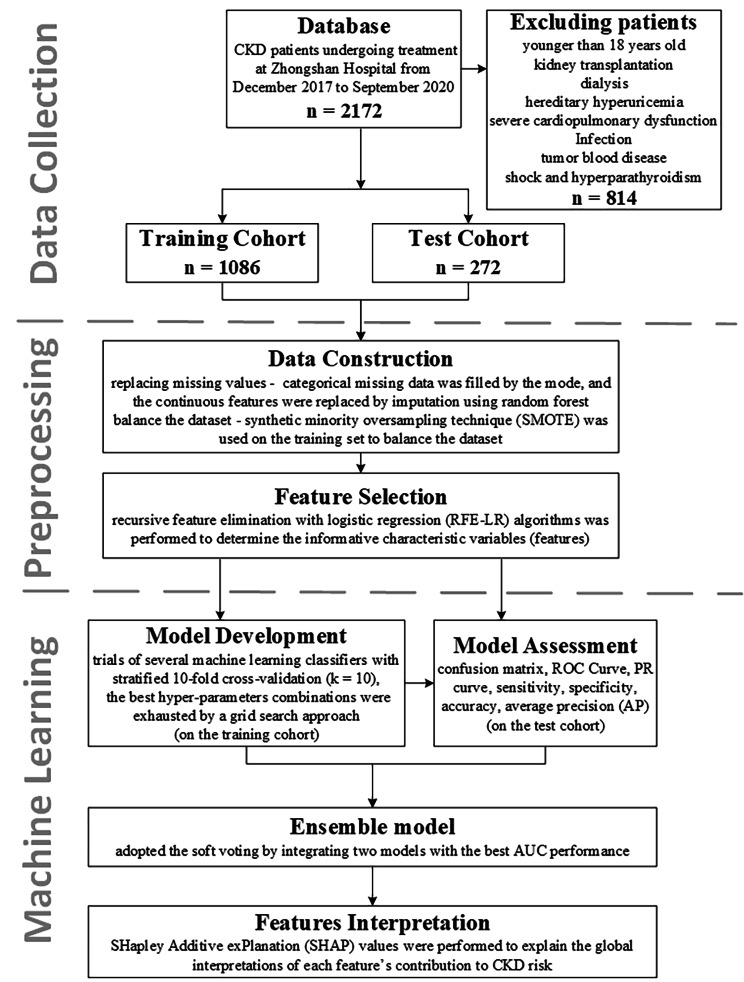
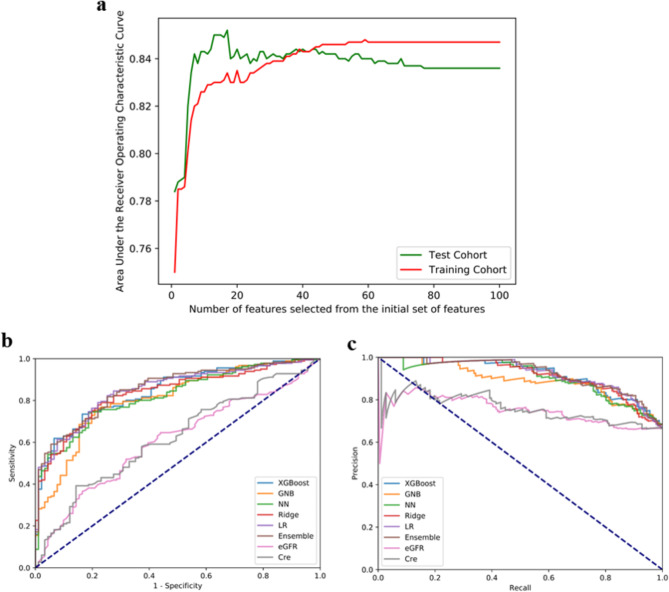
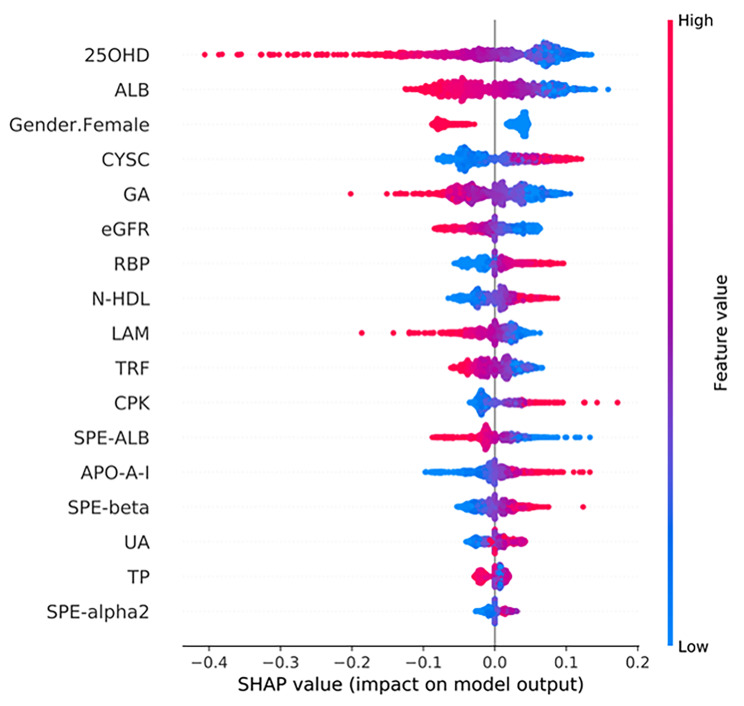
This study included data from 1,358 patients with CKD pathologically confirmed during the period from December 2017 to September 2020 at Zhongshan Hospital. A CKD prediction interpretation framework based on machine learning was proposed. From among 100 variables, 17 were selected for the model construction through a recursive feature elimination with logistic regression feature screening. Several machine learning classifiers, including extreme gradient boosting, gaussian-based naive bayes, a neural network, ridge regression, and linear model logistic regression (LR), were trained, and an ensemble model was developed to predict 24-hour urine protein. The detailed relationship between the risk of CKD progression and these predictors was determined using a global interpretation. A patient-specific analysis was conducted using a local interpretation.
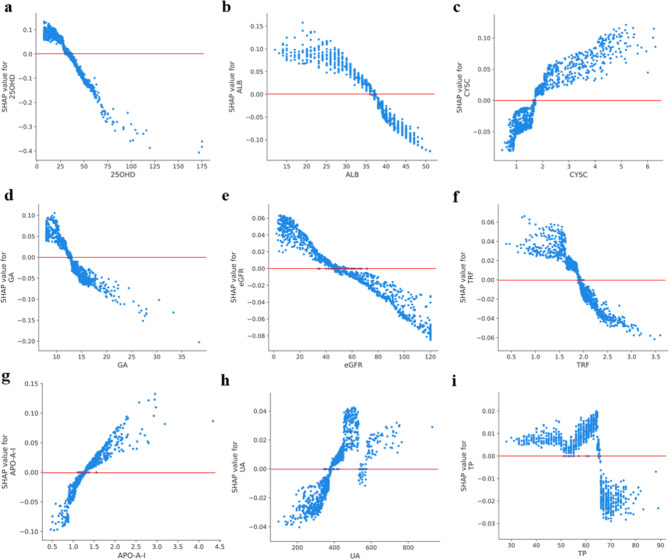
The results showed that LR achieved the best performance, with an area under the curve (AUC) of 0.850 in a single machine learning model. The ensemble model constructed using the voting integration method further improved the AUC to 0.856. The major predictors of moderate-to-severe severity included lower levels of 25-OH-vitamin, albumin, transferrin in males, and higher levels of cystatin C.
Compared with the clinical single kidney function evaluation indicators (eGFR, Scr), the machine learning model proposed in this study improved the prediction accuracy of CKD progression by 17.6% and 24.6%, respectively, and the AUC was improved by 0.250 and 0.236, respectively. Our framework can achieve a good predictive interpretation and provide effective clinical decision support.
慢性肾脏病(CKD)是一个全球性的公共卫生关注点。因此,为非住院的高危患者提供及时的干预,并合理分配有限的临床资源,对于设计 CKD 预测模型来说非常重要,以便挖掘关键因素。
本研究纳入了 2017 年 12 月至 2020 年 9 月期间在中山医院经病理确诊的 1358 例 CKD 患者的数据。提出了一种基于机器学习的 CKD 预测解释框架。通过逻辑回归特征筛选的递归特征消除,从 100 个变量中选择了 17 个变量用于模型构建。使用极端梯度提升、基于高斯的朴素贝叶斯、神经网络、岭回归和线性模型逻辑回归(LR)等几种机器学习分类器进行训练,并开发了一个集成模型来预测 24 小时尿蛋白。使用全局解释确定了这些预测因子与 CKD 进展风险之间的详细关系。使用局部解释对患者进行了特定分析。
结果表明,LR 在单一机器学习模型中的表现最佳,曲线下面积(AUC)为 0.850。使用投票集成方法构建的集成模型进一步将 AUC 提高到 0.856。中重度严重程度的主要预测因子包括男性 25-OH-维生素、白蛋白和转铁蛋白水平较低,胱抑素 C 水平较高。
与临床单一肾功能评估指标(eGFR、Scr)相比,本研究提出的机器学习模型分别将 CKD 进展的预测准确性提高了 17.6%和 24.6%,AUC 分别提高了 0.250 和 0.236。我们的框架可以实现良好的预测解释,并提供有效的临床决策支持。