Division of Urology, Department of Surgery, University of Toronto, Toronto, Ontario, Canada.
Temerty Centre for AI Research and Education in Medicine, University of Toronto, Toronto, Ontario, Canada.
JAMA Netw Open. 2023 Sep 5;6(9):e2335377. doi: 10.1001/jamanetworkopen.2023.35377.
Artificial intelligence (AI) has gained considerable attention in health care, yet concerns have been raised around appropriate methods and fairness. Current AI reporting guidelines do not provide a means of quantifying overall quality of AI research, limiting their ability to compare models addressing the same clinical question.
To develop a tool (APPRAISE-AI) to evaluate the methodological and reporting quality of AI prediction models for clinical decision support.
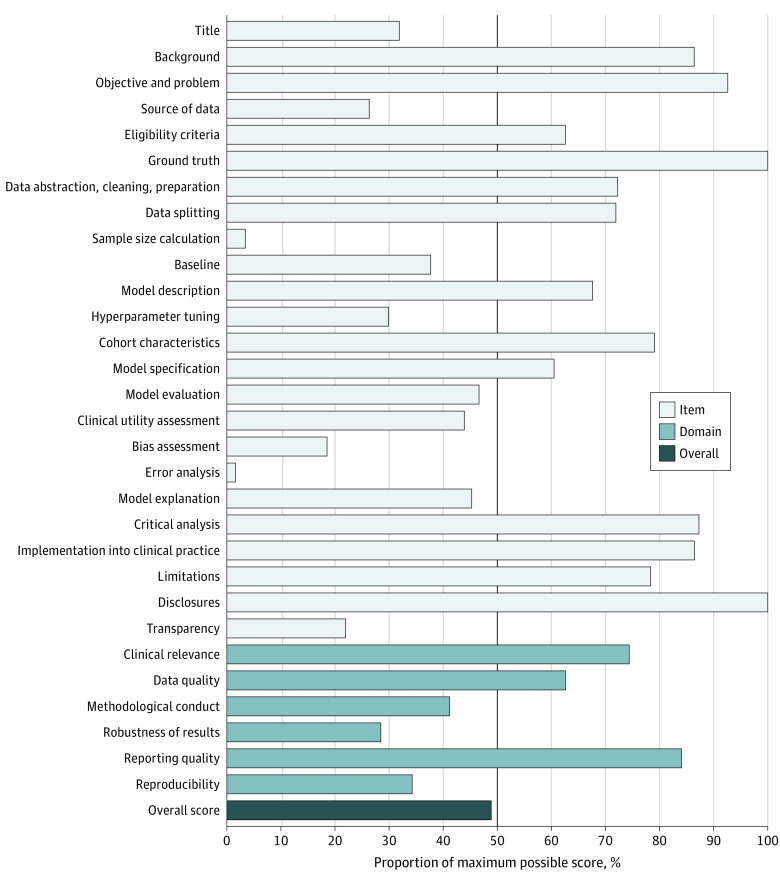
DESIGN, SETTING, AND PARTICIPANTS: This quality improvement study evaluated AI studies in the model development, silent, and clinical trial phases using the APPRAISE-AI tool, a quantitative method for evaluating quality of AI studies across 6 domains: clinical relevance, data quality, methodological conduct, robustness of results, reporting quality, and reproducibility. These domains included 24 items with a maximum overall score of 100 points. Points were assigned to each item, with higher points indicating stronger methodological or reporting quality. The tool was applied to a systematic review on machine learning to estimate sepsis that included articles published until September 13, 2019. Data analysis was performed from September to December 2022.
The primary outcomes were interrater and intrarater reliability and the correlation between APPRAISE-AI scores and expert scores, 3-year citation rate, number of Quality Assessment of Diagnostic Accuracy Studies (QUADAS-2) low risk-of-bias domains, and overall adherence to the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD) statement.
A total of 28 studies were included. Overall APPRAISE-AI scores ranged from 33 (low quality) to 67 (high quality). Most studies were moderate quality. The 5 lowest scoring items included source of data, sample size calculation, bias assessment, error analysis, and transparency. Overall APPRAISE-AI scores were associated with expert scores (Spearman ρ, 0.82; 95% CI, 0.64-0.91; P < .001), 3-year citation rate (Spearman ρ, 0.69; 95% CI, 0.43-0.85; P < .001), number of QUADAS-2 low risk-of-bias domains (Spearman ρ, 0.56; 95% CI, 0.24-0.77; P = .002), and adherence to the TRIPOD statement (Spearman ρ, 0.87; 95% CI, 0.73-0.94; P < .001). Intraclass correlation coefficient ranges for interrater and intrarater reliability were 0.74 to 1.00 for individual items, 0.81 to 0.99 for individual domains, and 0.91 to 0.98 for overall scores.
In this quality improvement study, APPRAISE-AI demonstrated strong interrater and intrarater reliability and correlated well with several study quality measures. This tool may provide a quantitative approach for investigators, reviewers, editors, and funding organizations to compare the research quality across AI studies for clinical decision support.
重要性:人工智能(AI)在医疗保健领域引起了广泛关注,但人们对适当的方法和公平性表示担忧。目前的 AI 报告指南没有提供一种方法来量化 AI 研究的整体质量,限制了它们比较针对同一临床问题的模型的能力。
目的:开发一种工具(APPRAISE-AI),用于评估用于临床决策支持的 AI 预测模型的方法学和报告质量。
设计、设置和参与者:这项质量改进研究使用 APPRAISE-AI 工具评估了模型开发、静默和临床试验阶段的 AI 研究,这是一种用于评估 6 个领域 AI 研究质量的定量方法:临床相关性、数据质量、方法学实施、结果稳健性、报告质量和可重复性。这些领域包括 24 个项目,总分最高为 100 分。为每个项目分配分数,分数越高表示方法学或报告质量越强。该工具应用于一项关于机器学习的脓毒症系统评价,其中包括截至 2019 年 9 月 13 日发表的文章。数据分析于 2022 年 9 月至 12 月进行。
主要结果和措施:主要结果是 APPRAISE-AI 评分的内部和内部可靠性以及与专家评分、3 年引用率、QUADAS-2 低风险偏倚域数量和整体对多变量预测模型个体预后或诊断透明报告(TRIPOD)声明的相关性。
结果:共纳入 28 项研究。总体 APPRAISE-AI 评分范围为 33(低质量)至 67(高质量)。大多数研究为中等质量。得分最低的 5 个项目包括数据来源、样本量计算、偏差评估、误差分析和透明度。总体 APPRAISE-AI 评分与专家评分相关(Spearman ρ,0.82;95%CI,0.64-0.91;P<0.001),3 年引用率(Spearman ρ,0.69;95%CI,0.43-0.85;P<0.001),QUADAS-2 低风险偏倚域数量(Spearman ρ,0.56;95%CI,0.24-0.77;P=0.002)和对 TRIPOD 声明的遵守情况(Spearman ρ,0.87;95%CI,0.73-0.94;P<0.001)。个体项目的内部和内部可靠性的组内相关系数范围为 0.74 至 1.00,个体域为 0.81 至 0.99,总体评分为 0.91 至 0.98。
结论和相关性:在这项质量改进研究中,APPRAISE-AI 表现出很强的内部和内部可靠性,与多项研究质量指标相关性良好。该工具可为研究人员、审查员、编辑和资助组织提供一种定量方法,用于比较用于临床决策支持的 AI 研究的研究质量。