Choi Hyeon Seok, Song Jun Yeong, Shin Kyung Hwan, Chang Ji Hyun, Jang Bum-Sup
Department of Radiation Oncology, Seoul National University Hospital, Seoul National University College of Medicine, Seoul, Korea.
Institute of Radiation Medicine, Seoul National University Medical Research Center, Seoul, Korea.
Radiat Oncol J. 2023 Sep;41(3):209-216. doi: 10.3857/roj.2023.00633. Epub 2023 Sep 21.
We aimed to evaluate the time and cost of developing prompts using large language model (LLM), tailored to extract clinical factors in breast cancer patients and their accuracy.
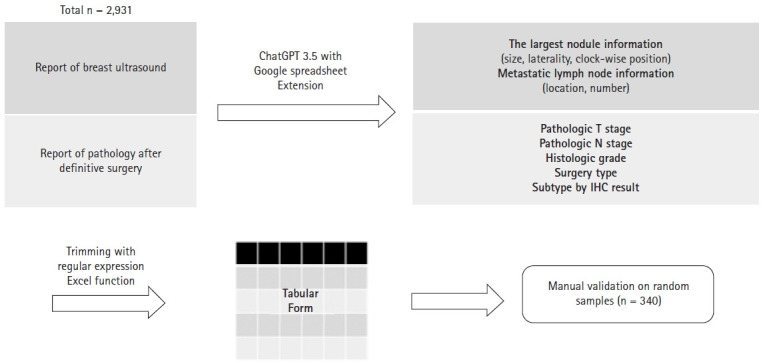
We collected data from reports of surgical pathology and ultrasound from breast cancer patients who underwent radiotherapy from 2020 to 2022. We extracted the information using the Generative Pre-trained Transformer (GPT) for Sheets and Docs extension plugin and termed this the "LLM" method. The time and cost of developing the prompts with LLM methods were assessed and compared with those spent on collecting information with "full manual" and "LLM-assisted manual" methods. To assess accuracy, 340 patients were randomly selected, and the extracted information by LLM method were compared with those collected by "full manual" method.
Data from 2,931 patients were collected. We developed 12 prompts for Extract function and 12 for Format function to extract and standardize the information. The overall accuracy was 87.7%. For lymphovascular invasion, it was 98.2%. Developing and processing the prompts took 3.5 hours and 15 minutes, respectively. Utilizing the ChatGPT application programming interface cost US $65.8 and when factoring in the estimated wage, the total cost was US $95.4. In an estimated comparison, "LLM-assisted manual" and "LLM" methods were time- and cost-efficient compared to the "full manual" method.
Developing and facilitating prompts for LLM to derive clinical factors was efficient to extract crucial information from huge medical records. This study demonstrated the potential of the application of natural language processing using LLM model in breast cancer patients. Prompts from the current study can be re-used for other research to collect clinical information.
我们旨在评估使用大语言模型(LLM)开发提示以提取乳腺癌患者临床因素的时间、成本及其准确性。
我们收集了2020年至2022年接受放疗的乳腺癌患者的手术病理报告和超声报告数据。我们使用适用于表格和文档的生成式预训练变换器(GPT)扩展插件提取信息,并将此方法称为“LLM”方法。评估了使用LLM方法开发提示的时间和成本,并与“完全手动”和“LLM辅助手动”方法收集信息所花费的时间和成本进行了比较。为评估准确性,随机选择了340例患者,并将LLM方法提取的信息与“完全手动”方法收集的信息进行比较。
收集了2931例患者的数据。我们为提取功能开发了12个提示词,为格式化功能开发了12个提示词,以提取和规范信息。总体准确率为87.7%。对于脉管侵犯,准确率为98.2%。开发和处理提示词分别耗时3.5小时15分钟。使用ChatGPT应用程序编程接口花费65.8美元,计入估计工资后,总成本为95.4美元。在估计比较中,与“完全手动”方法相比,“LLM辅助手动”和“LLM”方法在时间和成本上更具效率。
开发并促进LLM的提示以获取临床因素,能有效地从大量医疗记录中提取关键信息。本研究证明了使用LLM模型进行自然语言处理在乳腺癌患者中的应用潜力。本研究中的提示词可重新用于其他收集临床信息的研究。