Department of Ophthalmology, Byers Eye Institute, Stanford University, Stanford, California.
Department of Ophthalmology, Kaiser Permanente San Francisco, San Francisco, California.
JAMA Netw Open. 2023 Aug 1;6(8):e2330320. doi: 10.1001/jamanetworkopen.2023.30320.
Large language models (LLMs) like ChatGPT appear capable of performing a variety of tasks, including answering patient eye care questions, but have not yet been evaluated in direct comparison with ophthalmologists. It remains unclear whether LLM-generated advice is accurate, appropriate, and safe for eye patients.
To evaluate the quality of ophthalmology advice generated by an LLM chatbot in comparison with ophthalmologist-written advice.
DESIGN, SETTING, AND PARTICIPANTS: This cross-sectional study used deidentified data from an online medical forum, in which patient questions received responses written by American Academy of Ophthalmology (AAO)-affiliated ophthalmologists. A masked panel of 8 board-certified ophthalmologists were asked to distinguish between answers generated by the ChatGPT chatbot and human answers. Posts were dated between 2007 and 2016; data were accessed January 2023 and analysis was performed between March and May 2023.
Identification of chatbot and human answers on a 4-point scale (likely or definitely artificial intelligence [AI] vs likely or definitely human) and evaluation of responses for presence of incorrect information, alignment with perceived consensus in the medical community, likelihood to cause harm, and extent of harm.
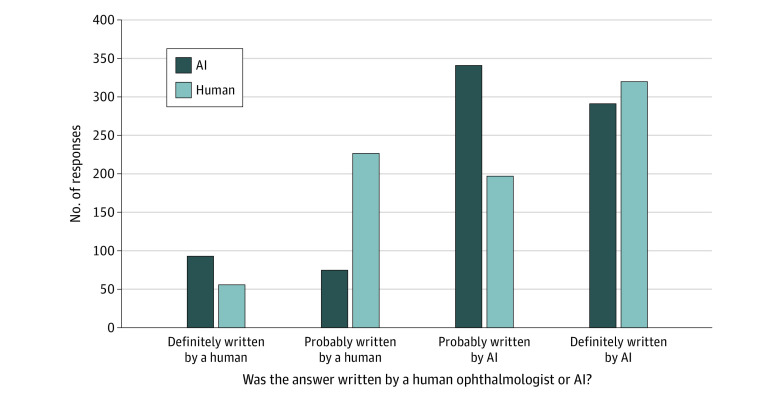
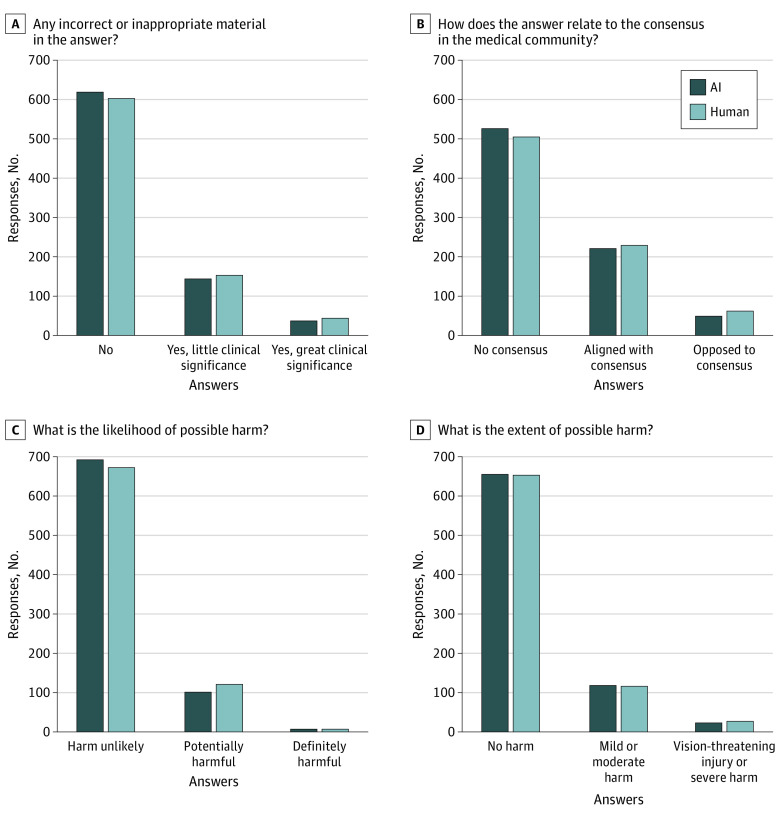
A total of 200 pairs of user questions and answers by AAO-affiliated ophthalmologists were evaluated. The mean (SD) accuracy for distinguishing between AI and human responses was 61.3% (9.7%). Of 800 evaluations of chatbot-written answers, 168 answers (21.0%) were marked as human-written, while 517 of 800 human-written answers (64.6%) were marked as AI-written. Compared with human answers, chatbot answers were more frequently rated as probably or definitely written by AI (prevalence ratio [PR], 1.72; 95% CI, 1.52-1.93). The likelihood of chatbot answers containing incorrect or inappropriate material was comparable with human answers (PR, 0.92; 95% CI, 0.77-1.10), and did not differ from human answers in terms of likelihood of harm (PR, 0.84; 95% CI, 0.67-1.07) nor extent of harm (PR, 0.99; 95% CI, 0.80-1.22).
In this cross-sectional study of human-written and AI-generated responses to 200 eye care questions from an online advice forum, a chatbot appeared capable of responding to long user-written eye health posts and largely generated appropriate responses that did not differ significantly from ophthalmologist-written responses in terms of incorrect information, likelihood of harm, extent of harm, or deviation from ophthalmologist community standards. Additional research is needed to assess patient attitudes toward LLM-augmented ophthalmologists vs fully autonomous AI content generation, to evaluate clarity and acceptability of LLM-generated answers from the patient perspective, to test the performance of LLMs in a greater variety of clinical contexts, and to determine an optimal manner of utilizing LLMs that is ethical and minimizes harm.
像 ChatGPT 这样的大型语言模型似乎能够执行各种任务,包括回答患者的眼科护理问题,但尚未与眼科医生进行直接比较评估。目前尚不清楚 LLM 生成的建议是否准确、适当且对眼科患者安全。
评估 LLM 聊天机器人生成的眼科建议与眼科医生书写的建议的质量。
设计、设置和参与者:这是一项横断面研究,使用了在线医学论坛中的匿名数据,其中患者问题的回复是由美国眼科学会 (AAO) 附属眼科医生撰写的。一个由 8 名具有董事会认证的眼科医生组成的盲法小组被要求区分 ChatGPT 聊天机器人生成的答案和人类答案。帖子的日期在 2007 年至 2016 年之间;数据于 2023 年 1 月获取,分析于 2023 年 3 月至 5 月进行。
以 4 分制(可能或肯定是人工智能 [AI] 与可能或肯定是人类)来识别聊天机器人和人类的答案,并评估答案中是否存在错误信息、与医学界共识的一致性、造成伤害的可能性以及伤害的程度。
共评估了 200 对 AAO 附属眼科医生的用户问题和答案。区分 AI 和人类回复的准确率(均数 [SD])为 61.3%(9.7%)。在 800 次对聊天机器人撰写的答案的评估中,有 168 次(21.0%)被标记为人类撰写,而在 800 次人类撰写的答案中,有 517 次(64.6%)被标记为 AI 撰写。与人类答案相比,聊天机器人答案更频繁地被标记为可能或肯定是由 AI 撰写的(优势比 [PR],1.72;95%CI,1.52-1.93)。聊天机器人答案包含错误或不适当内容的可能性与人类答案相似(PR,0.92;95%CI,0.77-1.10),在造成伤害的可能性(PR,0.84;95%CI,0.67-1.07)或伤害程度(PR,0.99;95%CI,0.80-1.22)方面与人类答案无差异。
在这项对在线咨询论坛中 200 个眼科护理问题的人类撰写和 AI 生成回复的横断面研究中,聊天机器人似乎能够回复用户撰写的长篇眼科健康帖子,并生成了大部分适当的回复,在错误信息、造成伤害的可能性、伤害程度或与眼科医生社区标准的偏差方面,与眼科医生撰写的回复没有显著差异。需要进一步研究来评估患者对眼科医生增强型人工智能与完全自主的 AI 内容生成的态度,从患者角度评估 LLM 生成的答案的清晰度和可接受性,在更大范围的临床环境中测试 LLM 的性能,并确定一种合乎道德且最大限度减少伤害的利用 LLM 的最佳方式。