Kasmaiee Sa, Kasmaiee Si, Homayounpour M
Department of Computer Engineering, Amirkabir University of Technology, Tehran, Iran.
Sci Rep. 2023 Nov 15;13(1):19945. doi: 10.1038/s41598-023-47295-2.
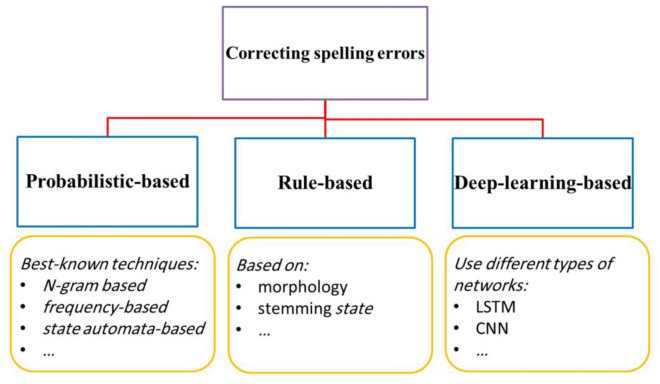
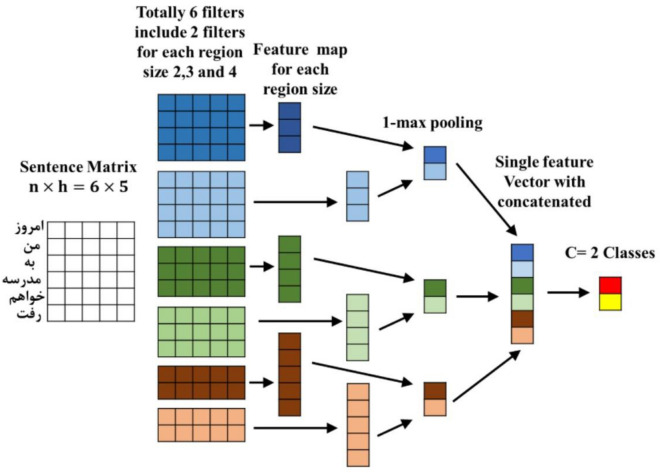
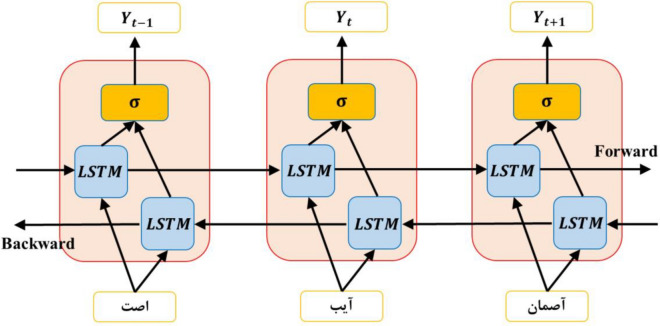
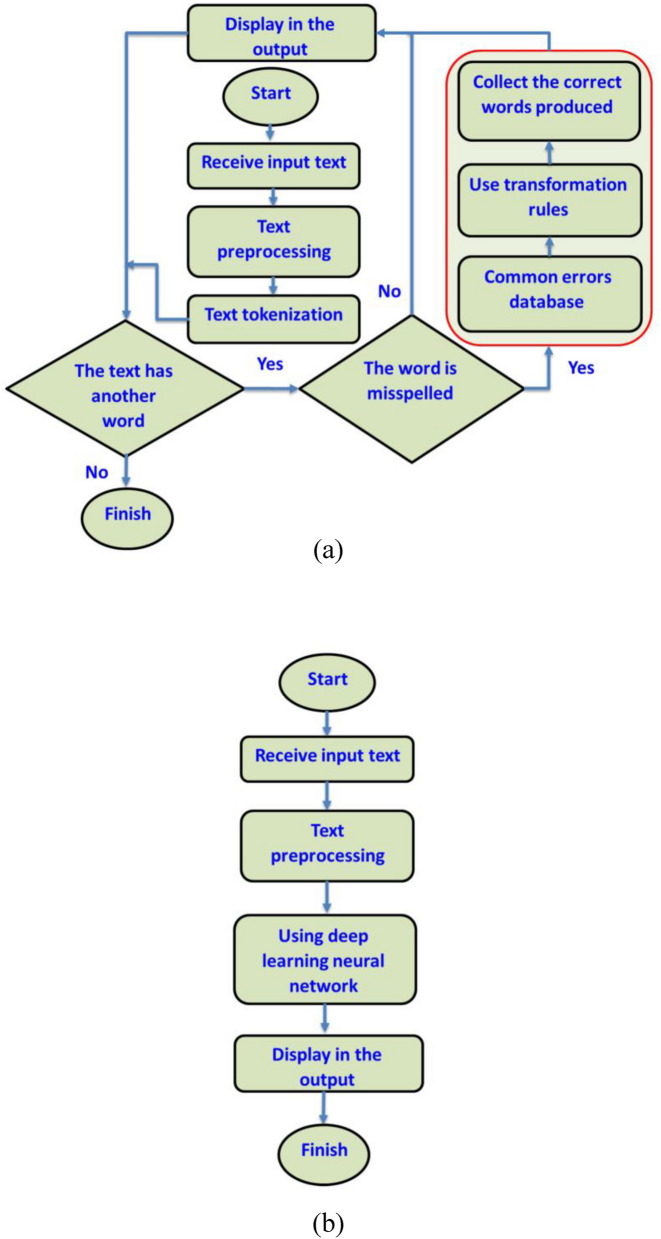
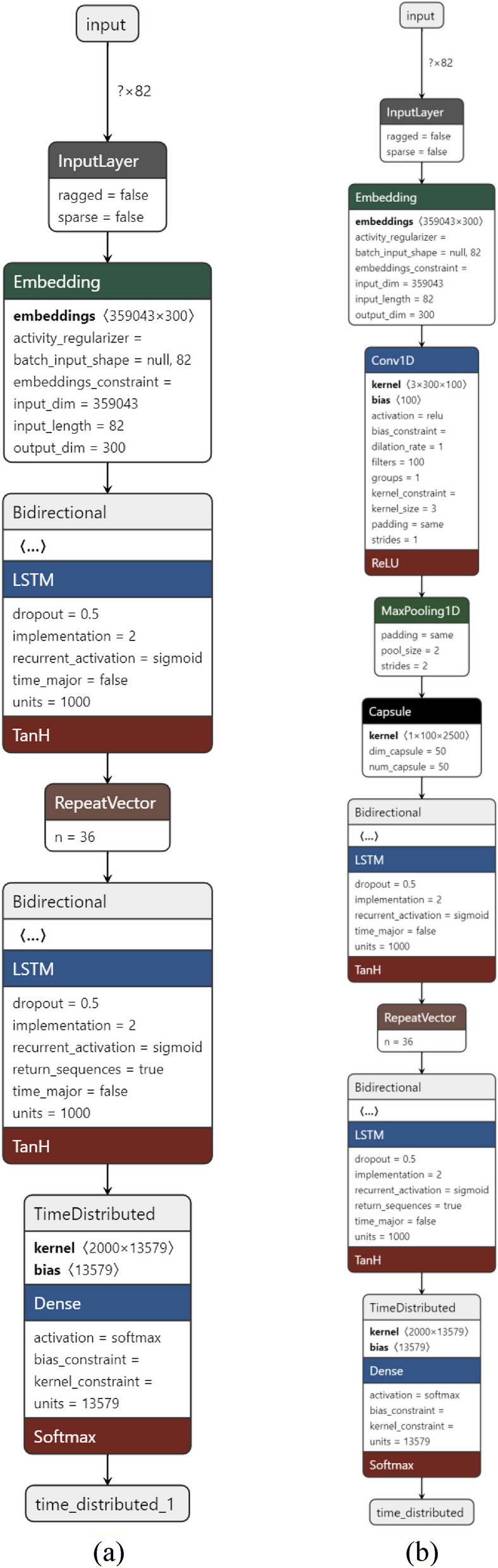
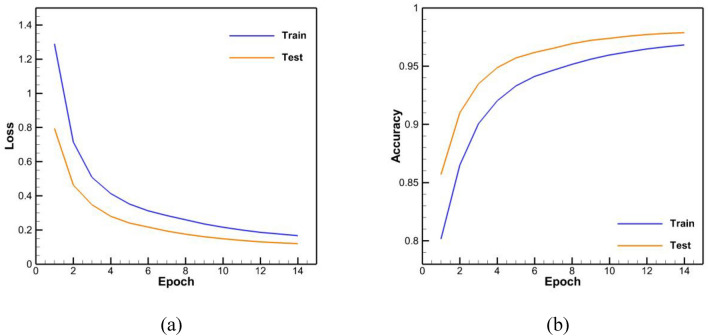
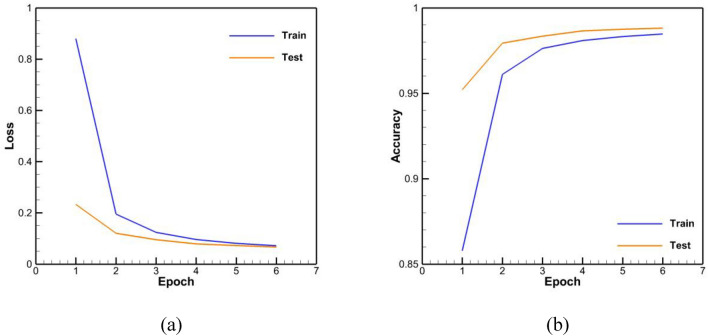
This study aims to develop a system for automatically correcting spelling errors in Persian texts using two approaches: one that relies on rules and a common spelling mistake list and another that uses a deep neural network. The list of 700 common misspellings was compiled, and a database of 55,000 common Persian words was used to identify spelling errors in the rule-based approach. 112 rules were implemented for spelling correction, each providing suggested words for misspelled words. 2500 sentences were used for evaluation, with the word with the shortest Levenshtein distance selected for evaluation. In the deep learning approach, a deep encoder-decoder network that utilized long short-term memory (LSTM) with a word embedding layer was used as the base network, with FastText chosen as the word embedding layer. The base network was enhanced by adding convolutional and capsule layers. A database of 1.2 million sentences was created, with 800,000 for training, 200,000 for testing, and 200,000 for evaluation. The results showed that the network's performance with capsule and convolutional layers was similar to that of the base network. The network performed well in evaluation, achieving accuracy, precision, recall, F-measure, and bilingual evaluation understudy (Bleu) scores of 87%, 70%, 89%, 78%, and 84%, respectively.
本研究旨在开发一个用于自动纠正波斯语文本拼写错误的系统,采用两种方法:一种依赖规则和常见拼写错误列表,另一种使用深度神经网络。编制了700个常见拼写错误的列表,并使用一个包含55000个常见波斯语单词的数据库,在基于规则的方法中识别拼写错误。实施了112条拼写纠正规则,每条规则为拼写错误的单词提供建议单词。使用2500个句子进行评估,选择编辑距离最短的单词进行评估。在深度学习方法中,一个利用带有词嵌入层的长短期记忆(LSTM)的深度编码器-解码器网络被用作基础网络,选择FastText作为词嵌入层。通过添加卷积层和胶囊层对基础网络进行了增强。创建了一个包含120万个句子的数据库,其中80万用于训练,20万用于测试,20万用于评估。结果表明,带有胶囊层和卷积层的网络性能与基础网络相似。该网络在评估中表现良好,准确率、精确率、召回率、F值和双语评估替补分数(Bleu)分别达到87%、70%、89%、78%和84%。