Division of Vaccine Discovery, La Jolla Institute for Immunology, La Jolla, San Diego, CA, USA.
University of California San Diego School of Medicine, La Jolla, San Diego, CA, USA.
BMC Bioinformatics. 2023 Dec 18;24(1):485. doi: 10.1186/s12859-023-05606-4.
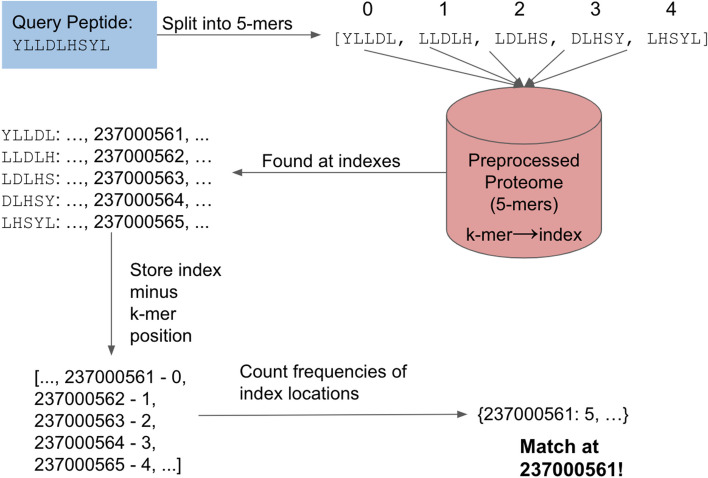
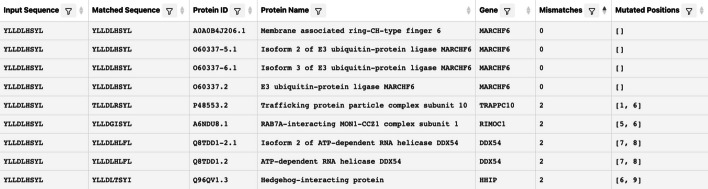
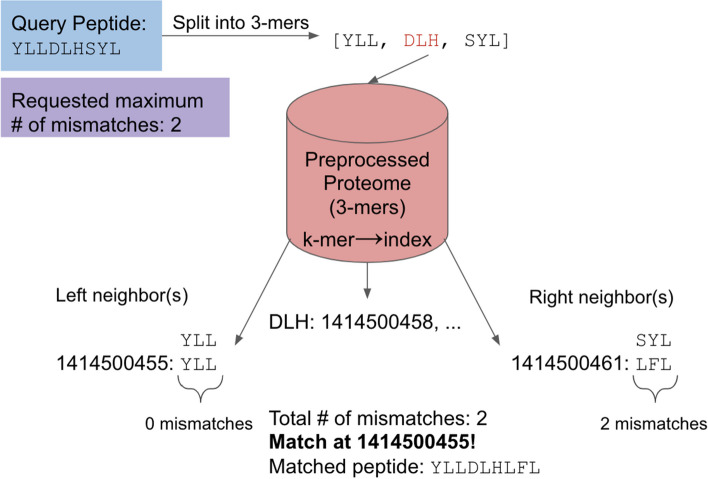
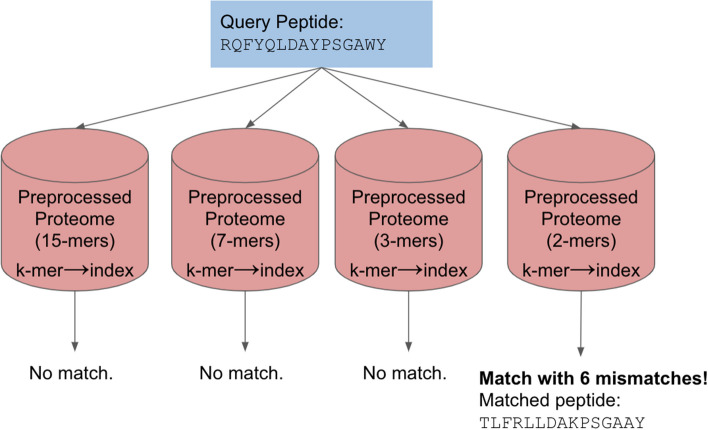
Numerous tools exist for biological sequence comparisons and search. One case of particular interest for immunologists is finding matches for linear peptide T cell epitopes, typically between 8 and 15 residues in length, in a large set of protein sequences. Both to find exact matches or matches that account for residue substitutions. The utility of such tools is critical in applications ranging from identifying conservation across viral epitopes, identifying putative epitope targets for allergens, and finding matches for cancer-associated neoepitopes to examine the role of tolerance in tumor recognition.
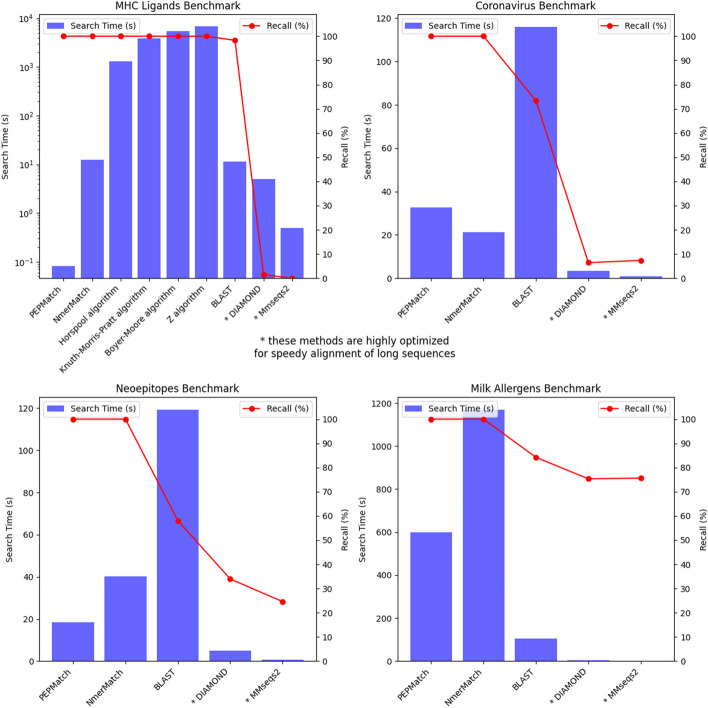
We defined a set of benchmarks that reflect the different practical applications of short peptide sequence matching. We evaluated a suite of existing methods for speed and recall and developed a new tool, PEPMatch. The tool uses a deterministic k-mer mapping algorithm that preprocesses proteomes before searching, achieving a 50-fold increase in speed over methods such as the Basic Local Alignment Search Tool (BLAST) without compromising recall. PEPMatch's code and benchmark datasets are publicly available.
PEPMatch offers significant speed and recall advantages for peptide sequence matching. While it is of immediate utility for immunologists, the developed benchmarking framework also provides a standard against which future tools can be evaluated for improvements. The tool is available at https://nextgen-tools.iedb.org , and the source code can be found at https://github.com/IEDB/PEPMatch .
有许多用于生物序列比较和搜索的工具。对于免疫学家来说,特别感兴趣的一个案例是在一大组蛋白质序列中找到线性肽 T 细胞表位(通常长度为 8 到 15 个残基)的匹配,无论是精确匹配还是残基替换的匹配。这些工具的实用性在各种应用中都至关重要,包括识别病毒表位的保守性、鉴定过敏原的潜在表位靶标,以及寻找与癌症相关的新表位的匹配,以研究耐受在肿瘤识别中的作用。
我们定义了一组反映短肽序列匹配不同实际应用的基准。我们评估了一系列现有的方法的速度和召回率,并开发了一个新工具,PEPMatch。该工具使用确定性 k-mer 映射算法在搜索前预处理蛋白质组,与 Basic Local Alignment Search Tool(BLAST)等方法相比,速度提高了 50 倍,而不会影响召回率。PEPMatch 的代码和基准数据集可公开获取。
PEPMatch 为肽序列匹配提供了显著的速度和召回优势。虽然它对免疫学家具有直接的实用性,但开发的基准框架还为未来的工具提供了一个评估改进的标准。该工具可在 https://nextgen-tools.iedb.org 获得,其源代码可在 https://github.com/IEDB/PEPMatch 找到。