Graduate School of Public Health, St. Luke's International University, 3-6-2 Tsukiji, Chuo-ku, Tokyo, 104-0045, Japan.
School of Medical Sciences, The University of Sydney, Camperdown, NSW, 2006, Australia.
Sci Data. 2024 Feb 29;11(1):260. doi: 10.1038/s41597-024-03036-2.
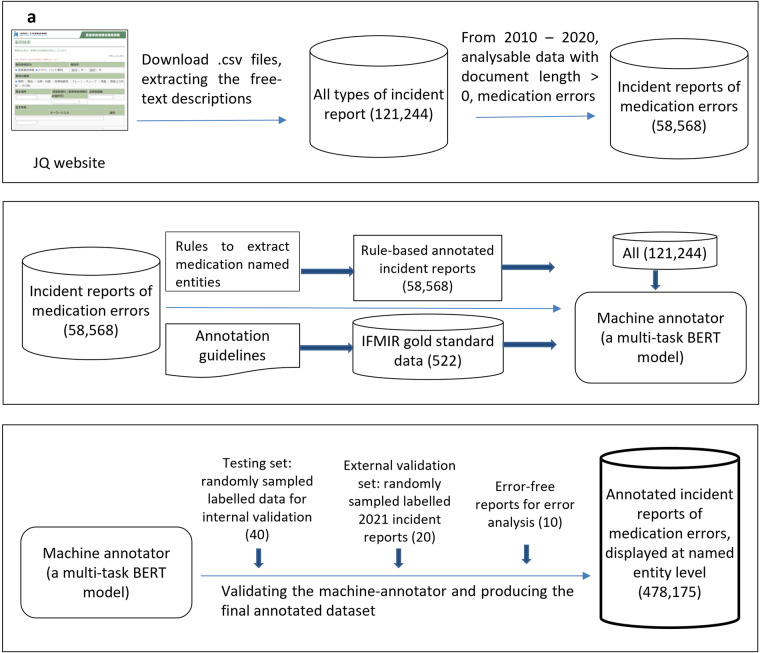
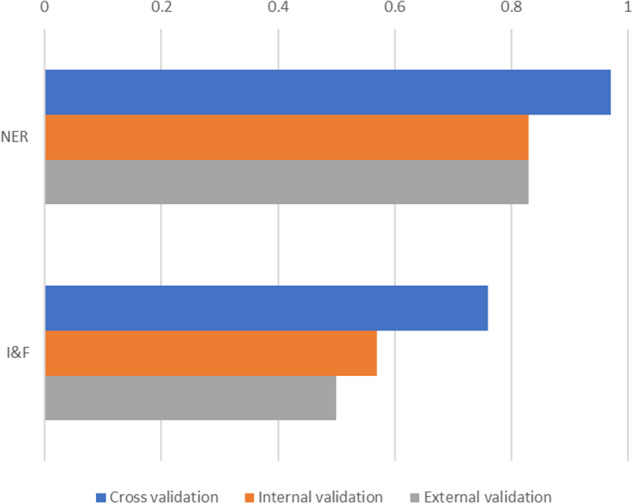
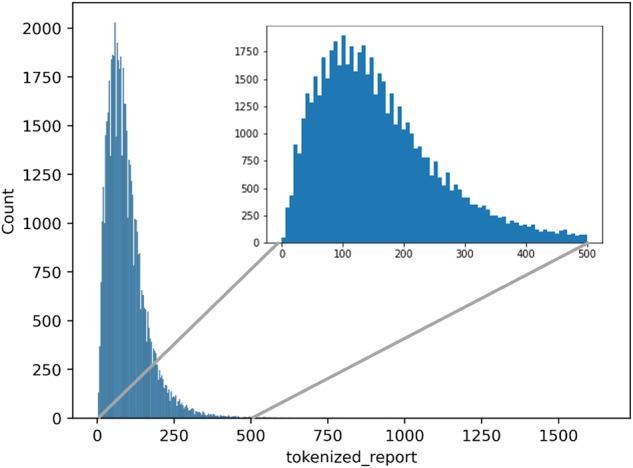
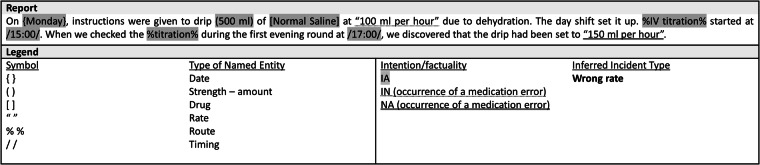
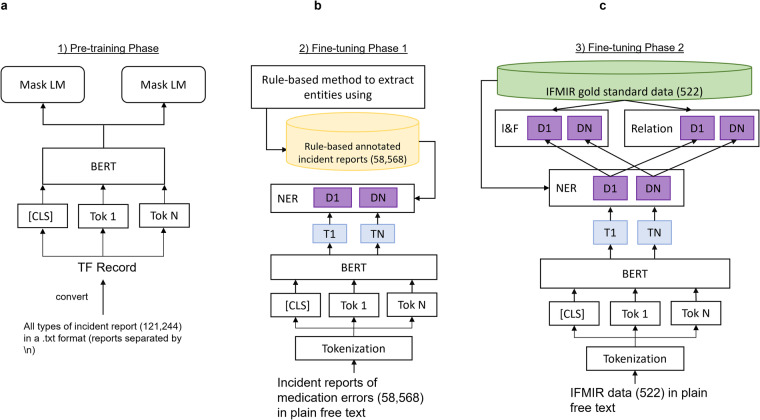
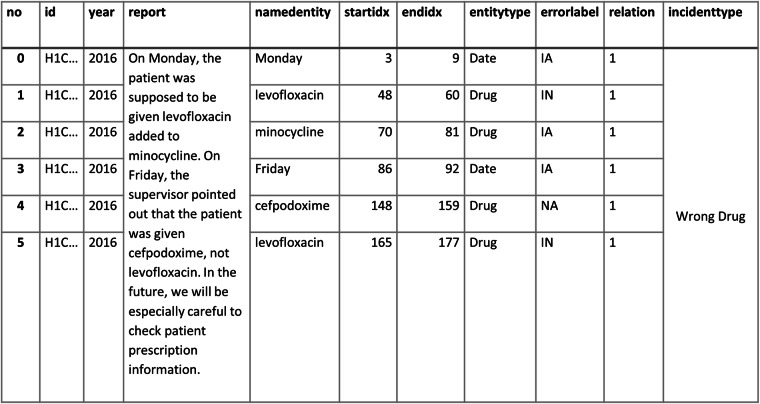
Incident reports of medication errors are valuable learning resources for improving patient safety. However, pertinent information is often contained within unstructured free text, which prevents automated analysis and limits the usefulness of these data. Natural language processing can structure this free text automatically and retrieve relevant past incidents and learning materials, but to be able to do so requires a large, fully annotated and validated corpus of incident reports. We present a corpus of 58,658 machine-annotated incident reports of medication errors that can be used to advance the development of information extraction models and subsequent incident learning. We report the best F1-scores for the annotated dataset: 0.97 and 0.76 for named entity recognition and intention/factuality analysis, respectively, for the cross-validation exercise. Our dataset contains 478,175 named entities and differentiates between incident types by recognising discrepancies between what was intended and what actually occurred. We explain our annotation workflow and technical validation and provide access to the validation datasets and machine annotator for labelling future incident reports of medication errors.
药物错误事件报告是提高患者安全性的宝贵学习资源。然而,相关信息通常包含在非结构化的自由文本中,这阻止了自动化分析并限制了这些数据的有用性。自然语言处理可以自动构建这段自由文本,并检索相关的过去事件和学习材料,但要做到这一点,需要一个大型的、完全标注和验证的药物错误事件报告语料库。我们提供了一个包含 58658 个机器标注的药物错误事件报告的语料库,可用于推进信息提取模型和后续事件学习的发展。我们报告了在交叉验证练习中注释数据集的最佳 F1 分数:命名实体识别为 0.97,意图/事实分析为 0.76。我们的数据集包含 478175 个命名实体,并通过识别预期与实际发生之间的差异来区分事件类型。我们解释了我们的注释工作流程和技术验证,并提供了对验证数据集和机器标注器的访问权限,以标注未来的药物错误事件报告。