Umer Fahad, Adnan Niha
Operative Dentistry and Endodontics, Department of Surgery, Aga Khan University Hospital, Karachi, Pakistan.
BDJ Open. 2024 Mar 1;10(1):13. doi: 10.1038/s41405-024-00198-4.
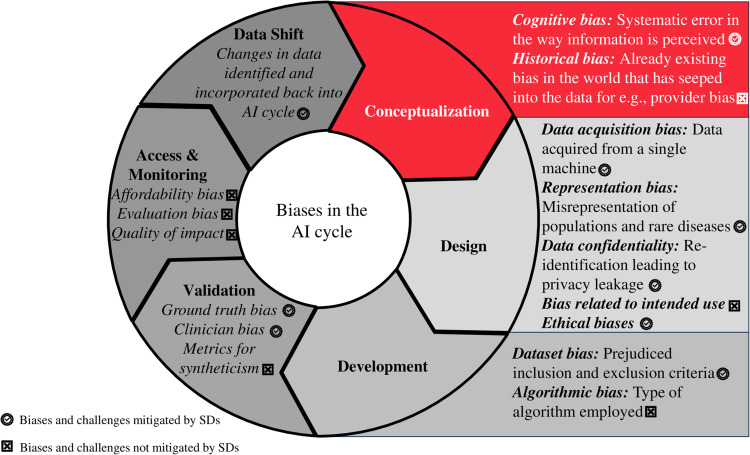
Artificial Intelligence (AI) algorithms, particularly Deep Learning (DL) models are known to be data intensive. This has increased the demand for digital data in all domains of healthcare, including dentistry. The main hindrance in the progress of AI is access to diverse datasets which train DL models ensuring optimal performance, comparable to subject experts. However, administration of these traditionally acquired datasets is challenging due to privacy regulations and the extensive manual annotation required by subject experts. Biases such as ethical, socioeconomic and class imbalances are also incorporated during the curation of these datasets, limiting their overall generalizability. These challenges prevent their accrual at a larger scale for training DL models.
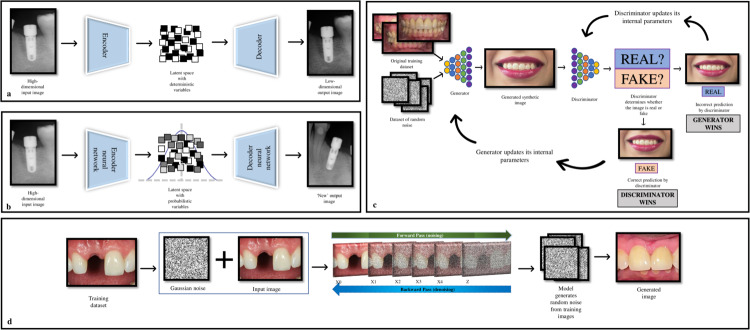
Generative AI techniques can be useful in the production of Synthetic Datasets (SDs) that can overcome issues affecting traditionally acquired datasets. Variational autoencoders, generative adversarial networks and diffusion models have been used to generate SDs. The following text is a review of these generative AI techniques and their operations. It discusses the chances of SDs and challenges with potential solutions which will improve the understanding of healthcare professionals working in AI research.
Synthetic data customized to the need of researchers can be produced to train robust AI models. These models, having been trained on such a diverse dataset will be applicable for dissemination across countries. However, there is a need for the limitations associated with SDs to be better understood, and attempts made to overcome those concerns prior to their widespread use.
众所周知,人工智能(AI)算法,尤其是深度学习(DL)模型对数据要求很高。这增加了医疗保健各个领域(包括牙科)对数字数据的需求。人工智能发展的主要障碍在于获取多样化的数据集,这些数据集用于训练深度学习模型,以确保其性能达到最佳,与专家水平相当。然而,由于隐私法规以及专家所需的大量手动标注,管理这些传统获取的数据集具有挑战性。在整理这些数据集时,还会纳入伦理、社会经济和类别不平衡等偏差,限制了它们的整体通用性。这些挑战阻碍了它们大规模积累用于训练深度学习模型。
生成式人工智能技术在生成合成数据集(SDs)方面可能很有用,这些合成数据集可以克服影响传统获取数据集的问题。变分自编码器、生成对抗网络和扩散模型已被用于生成合成数据集。以下文本是对这些生成式人工智能技术及其操作的综述。它讨论了合成数据集的机会以及潜在解决方案面临的挑战,这将增进从事人工智能研究的医疗专业人员的理解。
可以根据研究人员的需求生成定制的合成数据,以训练强大的人工智能模型。这些在如此多样化的数据集上训练的模型将适用于在各国传播。然而,有必要更好地理解与合成数据集相关的局限性,并在其广泛使用之前尝试克服这些问题。