Ren Jun, Lyu Xuejing, Guo Jintao, Shi Xiaodong, Zhou Ying, Li Qiyuan
School of Informatics, Xiamen University, Xiamen, 361105, China.
Department of Hematology, The First Affiliated Hospital of Xiamen University and Institute of Hematology, School of Medicine, Xiamen University, Xiamen, 361102, China.
J Transl Med. 2024 Mar 3;22(1):233. doi: 10.1186/s12967-024-05009-w.
Accurate and efficient cell grouping is essential for analyzing single-cell transcriptome sequencing (scRNA-seq) data. However, the existing clustering techniques often struggle to provide timely and accurate cell type groupings when dealing with datasets with large-scale or imbalanced cell types. Therefore, there is a need for improved methods that can handle the increasing size of scRNA-seq datasets while maintaining high accuracy and efficiency.
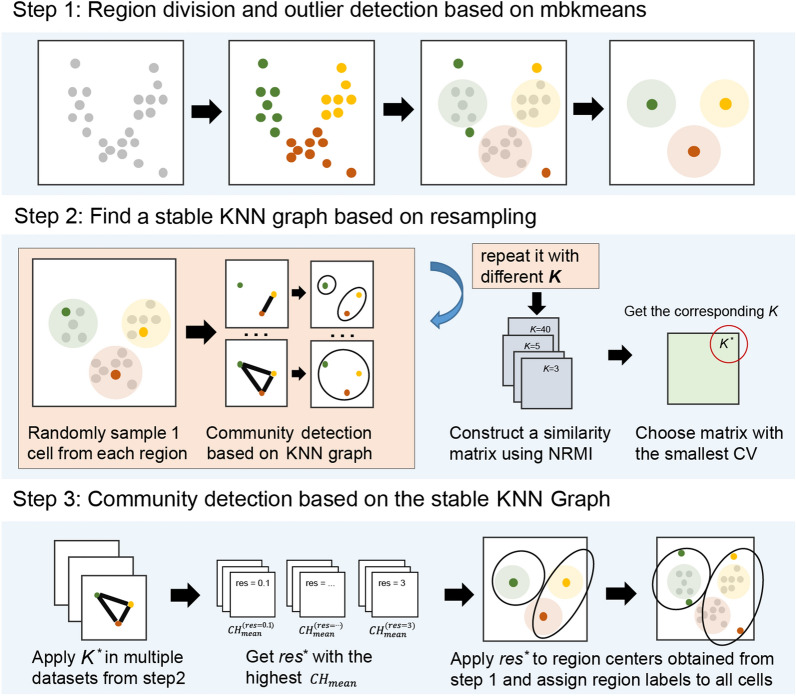
We propose CDSKNN (Community Detection based on a Stable K-Nearest Neighbor Graph Structure), a novel single-cell clustering framework integrating partition clustering algorithm and community detection algorithm, which achieves accurate and fast cell type grouping by finding a stable graph structure.
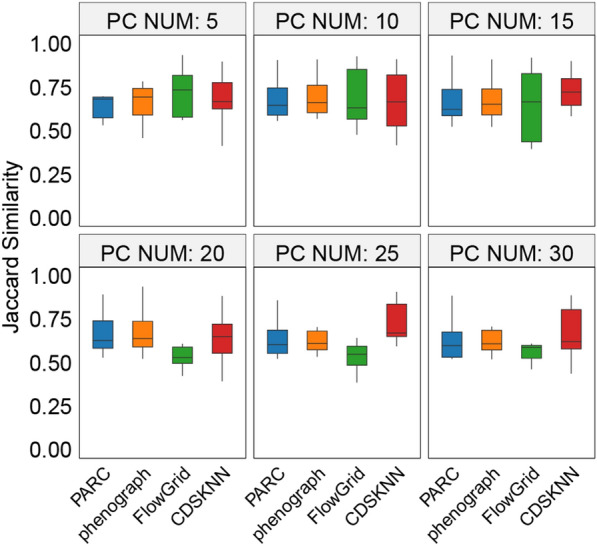
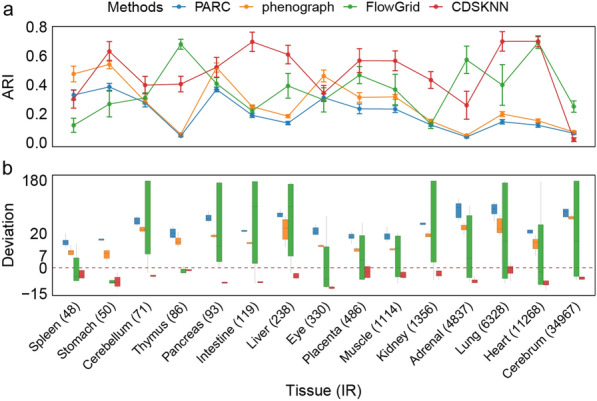
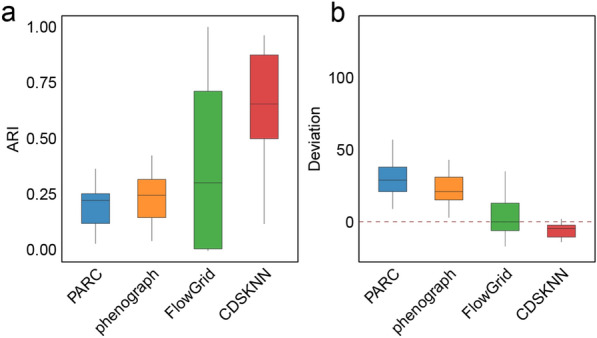
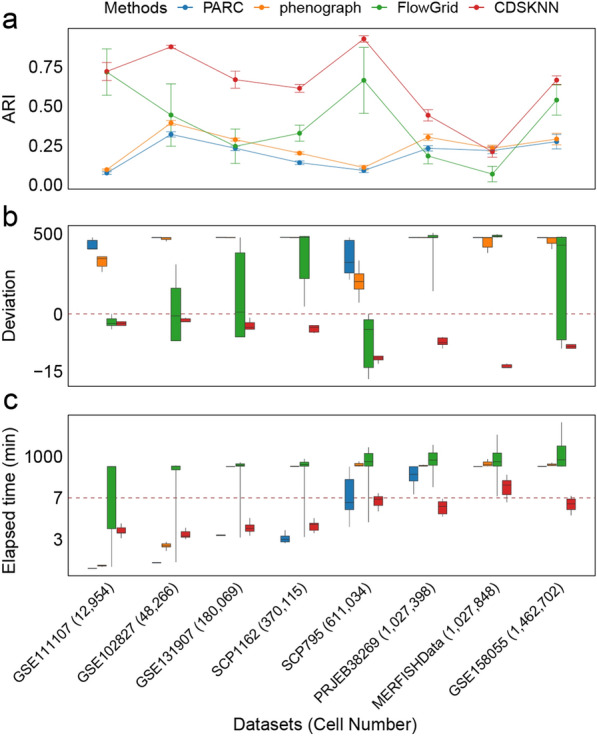
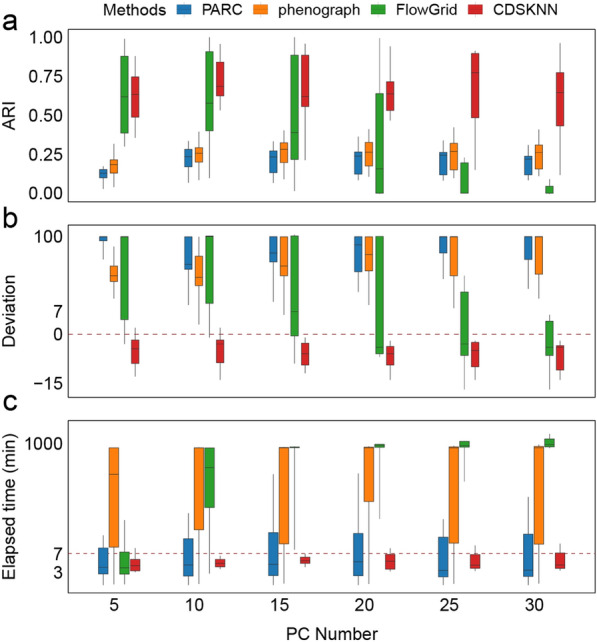
We evaluated the effectiveness of our approach by analyzing 15 tissues from the human fetal atlas. Compared to existing methods, CDSKNN effectively counteracts the high imbalance in single-cell data, enabling effective clustering. Furthermore, we conducted comparisons across multiple single-cell datasets from different studies and sequencing techniques. CDSKNN is of high applicability and robustness, and capable of balancing the complexities of across diverse types of data. Most importantly, CDSKNN exhibits higher operational efficiency on datasets at the million-cell scale, requiring an average of only 6.33 min for clustering 1.46 million single cells, saving 33.3% to 99% of running time compared to those of existing methods.
The CDSKNN is a flexible, resilient, and promising clustering tool that is particularly suitable for clustering imbalanced data and demonstrates high efficiency on large-scale scRNA-seq datasets.
准确且高效的细胞分组对于分析单细胞转录组测序(scRNA-seq)数据至关重要。然而,现有的聚类技术在处理具有大规模或不平衡细胞类型的数据集时,往往难以提供及时且准确的细胞类型分组。因此,需要改进的方法来处理不断增大规模的scRNA-seq数据集,同时保持高精度和高效率。
我们提出了CDSKNN(基于稳定k近邻图结构的社区检测),这是一种整合了划分聚类算法和社区检测算法的新型单细胞聚类框架,通过找到稳定的图结构来实现准确快速的细胞类型分组。
我们通过分析人类胎儿图谱中的15种组织来评估我们方法的有效性。与现有方法相比,CDSKNN有效抵消了单细胞数据中的高度不平衡,实现了有效的聚类。此外,我们对来自不同研究和测序技术的多个单细胞数据集进行了比较。CDSKNN具有高度的适用性和稳健性,能够平衡不同类型数据的复杂性。最重要的是,CDSKNN在百万细胞规模的数据集上展现出更高的运算效率,对146万个单细胞进行聚类平均仅需6.33分钟,与现有方法相比节省了33.3%至99%的运行时间。
CDSKNN是一种灵活、有弹性且有前景的聚类工具,特别适用于对不平衡数据进行聚类,并且在大规模scRNA-seq数据集上表现出高效率。