Temerty Faculty of Medicine, University of Toronto, 1 King's College Cir, M5S 1A8, Toronto, ON, Canada.
Cumming School of Medicine, University of Calgary, 3330 Hospital Dr NW, T2N 4N1, Calgary, AB, Canada.
BMC Med Inform Decis Mak. 2024 Mar 12;24(1):72. doi: 10.1186/s12911-024-02459-6.
Large language models (LLMs) like OpenAI's ChatGPT are powerful generative systems that rapidly synthesize natural language responses. Research on LLMs has revealed their potential and pitfalls, especially in clinical settings. However, the evolving landscape of LLM research in medicine has left several gaps regarding their evaluation, application, and evidence base.
This scoping review aims to (1) summarize current research evidence on the accuracy and efficacy of LLMs in medical applications, (2) discuss the ethical, legal, logistical, and socioeconomic implications of LLM use in clinical settings, (3) explore barriers and facilitators to LLM implementation in healthcare, (4) propose a standardized evaluation framework for assessing LLMs' clinical utility, and (5) identify evidence gaps and propose future research directions for LLMs in clinical applications.
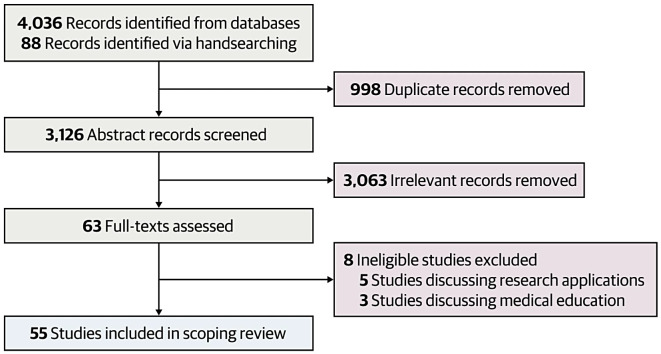
We screened 4,036 records from MEDLINE, EMBASE, CINAHL, medRxiv, bioRxiv, and arXiv from January 2023 (inception of the search) to June 26, 2023 for English-language papers and analyzed findings from 55 worldwide studies. Quality of evidence was reported based on the Oxford Centre for Evidence-based Medicine recommendations.
Our results demonstrate that LLMs show promise in compiling patient notes, assisting patients in navigating the healthcare system, and to some extent, supporting clinical decision-making when combined with human oversight. However, their utilization is limited by biases in training data that may harm patients, the generation of inaccurate but convincing information, and ethical, legal, socioeconomic, and privacy concerns. We also identified a lack of standardized methods for evaluating LLMs' effectiveness and feasibility.
This review thus highlights potential future directions and questions to address these limitations and to further explore LLMs' potential in enhancing healthcare delivery.
像 OpenAI 的 ChatGPT 这样的大型语言模型(LLMs)是强大的生成系统,可以快速合成自然语言响应。对 LLM 的研究揭示了它们的潜力和陷阱,尤其是在临床环境中。然而,医学领域 LLM 研究的不断发展,在评估、应用和证据基础方面留下了几个空白。
本范围综述旨在(1)总结 LLM 在医学应用中的准确性和有效性的现有研究证据,(2)讨论 LLM 在临床环境中使用的伦理、法律、后勤和社会经济影响,(3)探讨在医疗保健中实施 LLM 的障碍和促进因素,(4)提出评估 LLM 临床实用性的标准化评估框架,以及(5)确定 LLM 在临床应用中的证据空白并提出未来的研究方向。
我们从 MEDLINE、EMBASE、CINAHL、medRxiv、bioRxiv 和 arXiv 中筛选了 2023 年 1 月(搜索开始)至 2023 年 6 月 26 日的 4036 条记录,筛选出英文论文,并分析了来自全球 55 项研究的发现。根据牛津循证医学中心的建议报告证据质量。
我们的研究结果表明,LLM 在编写患者记录、帮助患者在医疗保健系统中导航以及在一定程度上支持临床决策方面具有潜力,前提是结合人工监督。然而,它们的利用受到训练数据中的偏差的限制,这些偏差可能会伤害患者,产生不准确但令人信服的信息,以及存在伦理、法律、社会经济和隐私方面的担忧。我们还发现,缺乏评估 LLM 有效性和可行性的标准化方法。
因此,本综述强调了潜在的未来方向和问题,以解决这些限制,并进一步探索 LLM 在增强医疗保健提供方面的潜力。