Laboratory of Chemoinformatics, UMR7140, University of Strasbourg, Strasbourg, France.
IDD/CADD, Sanofi, Vitry-Sur-Seine, France.
Sci Data. 2024 Mar 18;11(1):303. doi: 10.1038/s41597-024-03105-6.
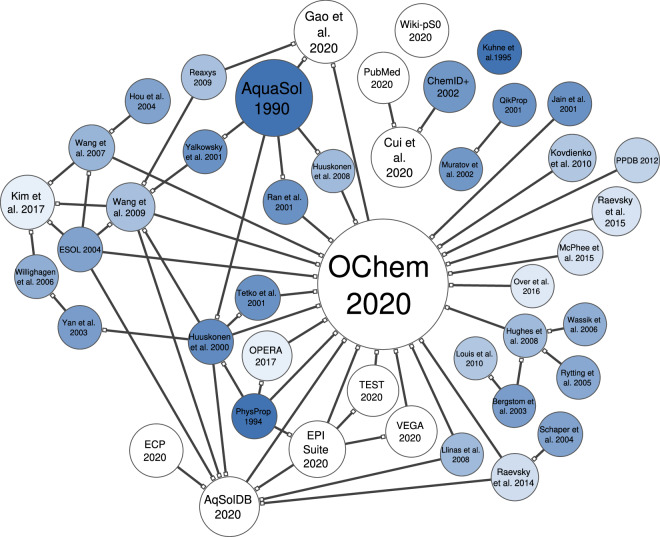
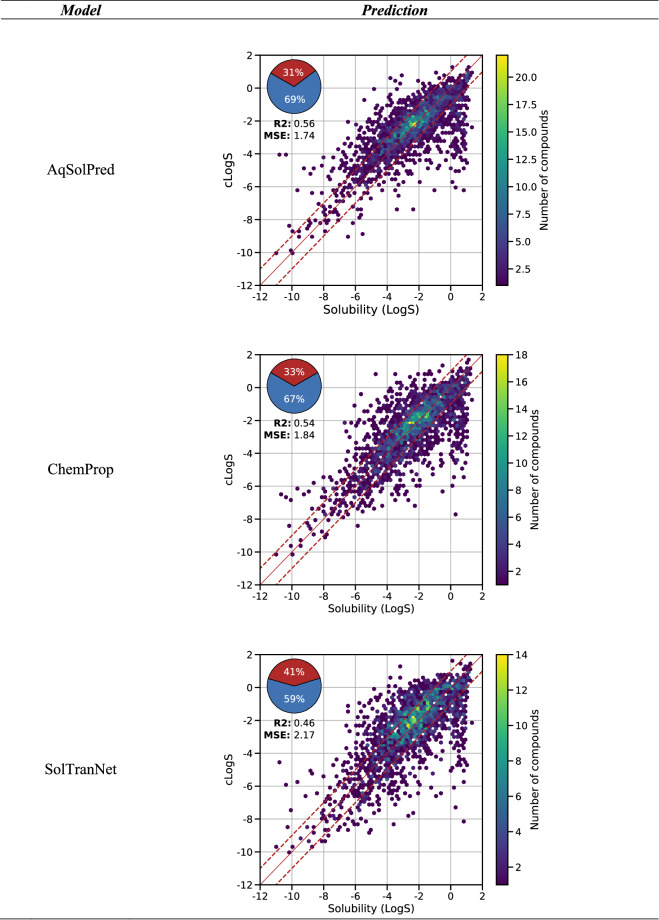
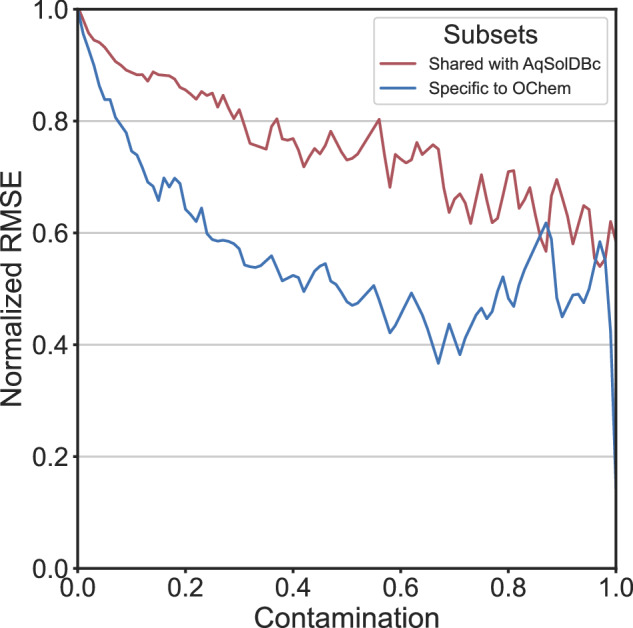
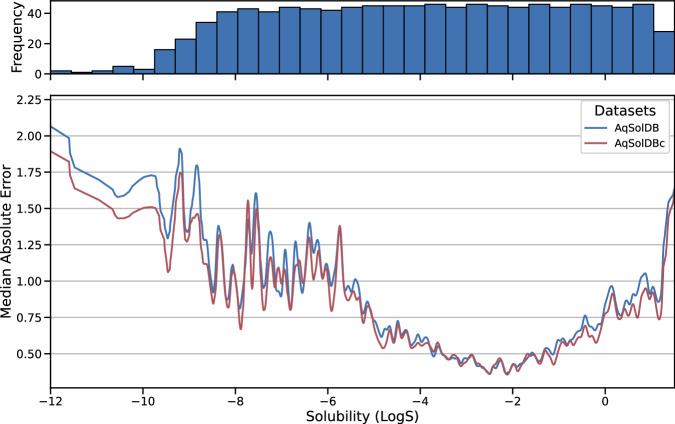
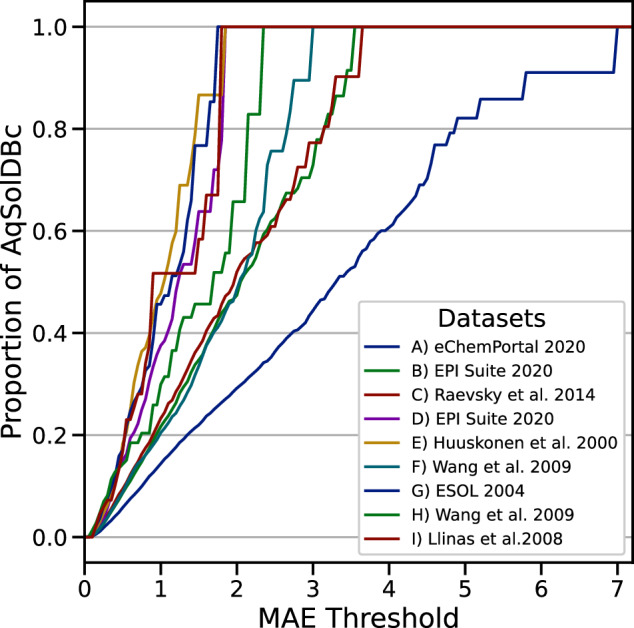
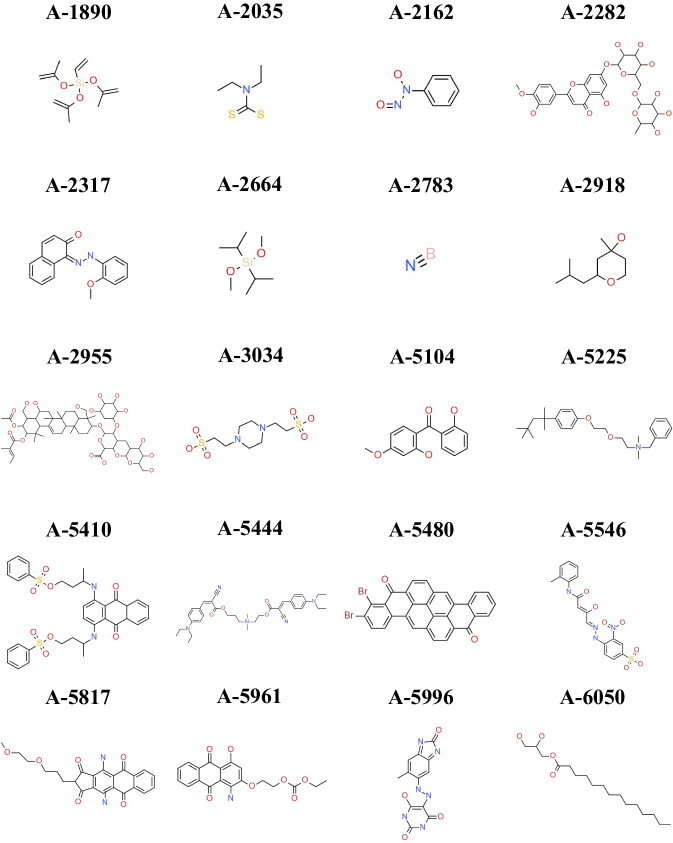
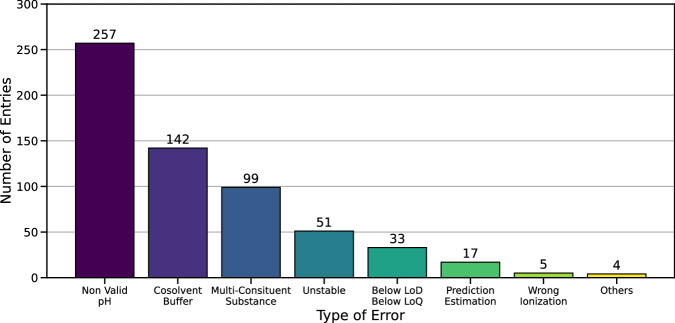
Accurate prediction of thermodynamic solubility by machine learning remains a challenge. Recent models often display good performances, but their reliability may be deceiving when used prospectively. This study investigates the origins of these discrepancies, following three directions: a historical perspective, an analysis of the aqueous solubility dataverse and data quality. We investigated over 20 years of published solubility datasets and models, highlighting overlooked datasets and the overlaps between popular sets. We benchmarked recently published models on a novel curated solubility dataset and report poor performances. We also propose a workflow to cure aqueous solubility data aiming at producing useful models for bench chemist. Our results demonstrate that some state-of-the-art models are not ready for public usage because they lack a well-defined applicability domain and overlook historical data sources. We report the impact of factors influencing the utility of the models: interlaboratory standard deviation, ionic state of the solute and data sources. The herein obtained models, and quality-assessed datasets are publicly available.
通过机器学习准确预测热力学溶解度仍然是一个挑战。最近的模型通常表现出良好的性能,但当前瞻性使用时,它们的可靠性可能会有误导性。本研究从三个方向调查了这些差异的起源:历史视角、水溶液溶解度数据和数据质量分析。我们调查了 20 多年来发表的溶解度数据集和模型,突出了被忽视的数据集和流行数据集之间的重叠。我们在一个新的经过精心整理的溶解度数据集上对最近发表的模型进行了基准测试,报告了较差的性能。我们还提出了一种水相溶解度数据的工作流程,旨在为实验室化学家生成有用的模型。我们的结果表明,由于缺乏明确定义的适用域并且忽略了历史数据源,一些最先进的模型还不能供公众使用。我们报告了影响模型实用性的因素的影响:实验室间标准偏差、溶质的离子状态和数据源。在此获得的模型和经过质量评估的数据集都是公开可用的。